kernel版本:5.15
源码注释:iliuqi的5.15内核
0. 前言
本篇主要在代码剖析Page 之前的理论阐述,其中包括 MMU、TLB、TTW、VIVT、VIPT、PIPT等术语的含义,介绍MMU 中 TLB、TTW 的工作原理,接着会简单地介绍一级页表 ~ 多级页表的映射过程,进而引入 ARMv8 处理器,以此为例简单阐述分页管理的原理。
1. MMU
MMU 是Memory Management Unit 的缩写,翻译为内存管理单元。它是CPU 配置的可选项,MMU 主要负责虚拟地址与物理地址的转换,提供硬件机制的内存访问权限。现在CPU 的应用中,基本上都会选择MMU。
我们通常把处理器能寻址的地址空间称为 虚拟地址空间,对应的为物理地址空间。在没有使能分页机制的系统中,处理器会直接寻址物理地址,把物理地址发送给内存控制器中;而在分页机制的系统中 ,处理器直接寻址虚拟地址,这个地址不会直接发送给内存控制器,而是先发送给MMU的硬件单元。
程序可以在虚拟地址空间任意分配虚拟内存,但是只有当程序需要访问或者修改虚拟内存时操作系统才会为其分配物理内存,这个过程叫做 请求调页(demand page) 或者 缺页异常(page fault)。
2. VPN/PFN/PT/PTE/TTBR
虚拟地址VA[31:0] 可以分成两部分:一部分是虚拟页面内的偏移量,以4KB页为例,VA[11:0] 是虚拟页面内的偏移量;另一部分用来确定属于哪个页,称其为 虚拟页帧号( Virturl Page Frame Number, VPN)。
对于物理地址,也是类似的,PA[11:0] 表示物理页帧的偏移量 (页内偏移),剩余的部分表示物理页帧号, 在 Linux内核中使用的pfn ( Page Fame Number, PFN),实际就是指的物理页帧号。
MMU 的工作内容就是把 VPN 转换成 PFN,处理器通常使用一张表来存储 VPN 到 PFN 的映射关系,这个表称为 页表( Page Table, PT)。页表中的每一个表项称为 页表项( Page Table Entry, PTE)。
若将整张页表存放在寄存器中,则会占用很多硬件资源,因此通常的做法是把页表放在主内存中,通过 页表的基地址寄存器( Translation Table Base Register, TTBR)来指向这个页表的起始地址。
3. TLB
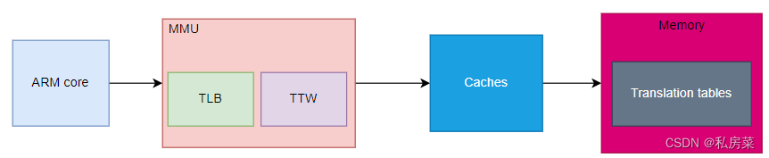
在现代处理器中,软件使用 虚拟地址 访问内存,而处理器的MMU 负责把虚拟地址转换成物理地址。程序可以对底层的物理地址一无所知,物理地址也可以不连续,但是不妨碍映射连续的虚拟地址空间。为了完成这个映射过程,软件和硬件要共同维护一个多级映射页表。
为了加快MMU规则匹配的处理过程,有效地址和实际物理地址的对应表通常保存在一块单独的高速缓存中,称为对应查找表( Translation Lookaside Buffer,TLB),也翻译为页表缓存、转换旁路缓存、转译后背缓存器。
TLB 专门用于缓存 已经翻译好的页表项,一般在MMU 内部。TLB 是一个很小的 高速缓存,TLB表项( TLB Entry) 数量比较少,每个TLB 表项包含一个页面的相关信息,如有效位、VPN、修改位、PFN等。有的书把 TLB 称为 快表,当处理器访问内存时首先从 TLB 中查询是否有对应的表项。当 TLB 命中,那么直接从 TLB 表项中获取物理地址,处理器就不需要再到主内存中查询页表了。
如果没有TLB,虚拟地址的映射关系只能从映射的页表中查询,这样会频繁访问内存,降低系统映射性能。
当TLB 没有命中时,MMU 内的专用硬件使其能够读取内存中的映射表,并将新的映射信息缓存到TLB中,这就是 TTW( Translation Table Walk)。
当处理器要访问一个虚拟地址时,首先会在TLB 中查询。如果TLB 中没有相应的表项(即TLB 未命中),那么需要访问页表来计算出相应的物理地址(TTW 来完成);如果TLB 中有相应的表项(即TLB 命中),那么直接从TLB 表项中获取物理地址。
TLB 是个很小的高速缓存, 基本单位是 TLB 表项,TLB 容量越大,所能存放TLB 的表项越多,TLB 的命中率就越高。但是 TLB 的容量是有限的。目前 Linux 内核默认采用4KB 大小的小页面,如果一个程序使用 512个小页面,即 2MB大小,那么至少需要512个TLB 表项才能保证不会出现TLB未命中的情况。但是如果使用 2MB 大小的巨页,那么只需要一个 TLB 表项就可以保证不会出现TLB 未命中的情况。对于消耗的内存以 GB 为单位的大型应用程序,还可以使用以GB 为单位的巨页,从而减少 TLB 未命中情况出现的次数。

- 使用MMU 查找对应的映射关系,此处会进 TLB 中,对缓存的翻译好的表项查询
- 如果TLB 命中,则直接取出对应的物理地址,即可访问物理空间
- 如果TLB 没有命中, TTW 会从映射好页表中查询,出现4)或 6)结果
- 如果页表命中,说明该虚拟地址之前映射过,直接取出物理地址
- 当上一步命中后,需要将映射信息存入TLB 中,以便下一次的访问
- 如果页表中没有命中,说明还没有进行映射,系统出现page fault,系统会进行调页
- 步骤7和步骤8 进行申请物理内存,如果申请成功会更新页表
最后,我们看 图 1 中的 cache,它是处理器和存储器之间的缓存机制,用以提高访问速率。在ARMv8 上会存在多级Cache,其中 L1 Cache 分为指令Cache (icache)和数据Cache (dcache),在CPU core 内部,支持虚拟地址寻址;L2 Cache容量更大,同时存储指令和数据,为多个CPU core 共用,这多个CPU core 也就组成了一个Cluster。
4. 一级页表映射过程
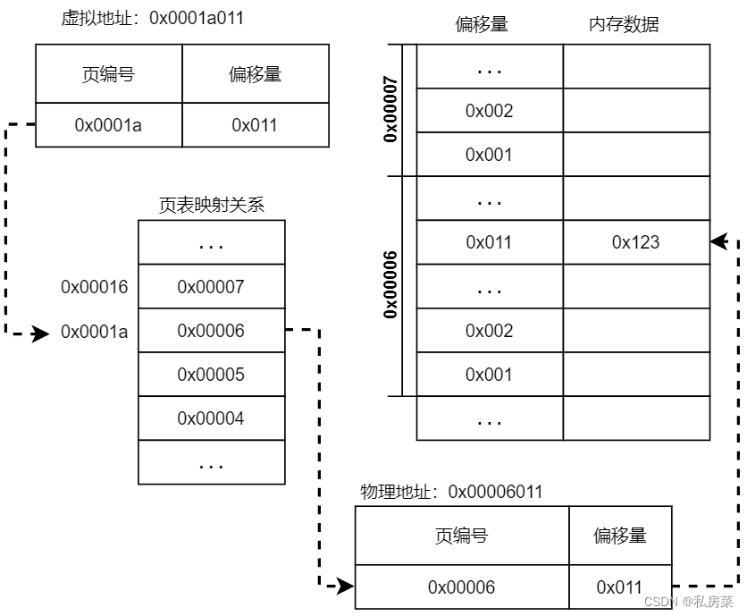
对于页来说,无论是虚拟页和物理页,一页之内的地址都是连续的。这样虚拟页和物理页就可以对应起来。这意味着,虚拟内存地址和物理内存地址的末端部分完全相同。对于4KB 的页,是 2 的12 次方,所以地址最后 12 位的对应关系天然成立。我们把地址的这一部分称为 偏移量(offset)。偏移量实际上表达了该字节的页内的位置。地址的前面部分则称为 页编号,操作系统只记录页编号的对应关系。
5. 为什么要使用多级分页表
内存分页制度的关键,在于管理进程空间页和物理页的对应关系。操作系统把对应关系记录在分页表(page table)中。这种对应关系让上层的抽象内存和下层的物理内存分离,从而让Linux能灵活地进行内存管理。由于每个进程会有一套虚拟内存地址,那么每个进程都会有一个分页表。为了保证查询速度,分页表也会保存在内存中。分页表有很多种实现方式,最简单的一种分页表就是把所有的对应关系记录到同一个线性列表中,即如上图所示。
这种单一的连续分页表,需要给每一个虚拟页预留一条记录的位置。但对于任何一个应用进程,其进程空间真正用到的地址都相当有限。我们还记得,进程空间会有栈和堆。进程空间为栈和堆的增长预留了地址,但栈和堆很少会占满进程空间。这意味着, 如果使用连续分页表,很多条目都没有真正用到。
另外,对于32位的处理器,虚拟地址空间位4G,如果是使用一个分页表,则有2^20 项(100多万项,假设每项为4B,2^20 * 4B = 4MB,存放时每个进程大概4M空间内存)。如果是使用64位处理器,情况会更糟糕,仅用户空间则有2^36项(680亿项,存放时每个进程大概 256GB 空间内存)。
因此,Linux中的分页表,采用了多层的数据结构。多层的分页表能够减少所需的空间。
6. 64位系统中的分页
32位处理器普遍采用两级分页。然而两级分页并不适用于采用64位系统的计算机。
原因如下 :
首先假设一个大小为4KB的标准页,4KB覆盖 2^12 个地址,所以offset字段是12位。如果我们现在决定仅仅使用64位中的48位来寻址(这个限制仍然能是我们自在地拥有256TB的寻址空间!),剩下的48-12=36位被分配给Table和Directory字段。如果我们决定为两个字段个预留18位,那么每个进程的页目录和页表都含有 2^18 个项,即超过256000个项。
由于这个原因,所有64位处理器的硬件分页系统都使用了额外的分页级别。使用的级别数量取决于处理器的类型。
| 平台名称 | 页大小 | 寻址使用位数 | 分页级别 | 线性地址分级 |
|---|---|---|---|---|
| alpha | 8KB | 43 | 3 | 10+10+10+13 |
| ia64 | 4KB | 39 | 3 | 9+9+9+12 |
| ppc64 | 4KB | 41 | 3 | 10+10+9+12 |
| x86_64 | 4KB | 48 | 4 | 9+9+9+9+12 |
注:ia64是intel的一门高端技术,不与x86_64系统兼容
7. Linux 中的分页
为了同时支持适用于32位和64位的系统,x86 Linux 此采用了通用的分页模型。在Linux-2.6.10 版本中,Linux 采用了三级分页模型。而从2.6.11 开始普遍采用了四级分页模型。
从PGD、PMD、PTE 三级模型变成PGD、PUD、PMD、PTE 四级模型。
| 单元 | 描述 |
|---|---|
| 页全局目录 | PGD(Page Global Directory) |
| 页上级目录 | PUD(Page Upper Directory) |
| 页中间目录 | PMD(Page Middle Directory) |
| 页表 | PTE(Page Table) |
| 页内偏移 | Page offset |
8. ARMv8 分页管理
8.1 虚拟地址支持
64 位虚拟地址中,并不是所有的位都用上,除了高16位用于区分内核空间和用户空间外,有效位的配置可以是:36、39、42、47. 这可决定了Linux 内核中地址空间的大小。
使用内核中的有效位配置通过: CONFIG_ARM64_VA_BITS,例如设为39,那么用户空间的地址范围为:0x00000000_00000000 ~ 0x0000007F_FFFFFFFF,大小为512G,内核地址的范围为:0xFFFFFF80_00000000 ~ 0xFFFFFFFF_FFFFFFFF,大小为 512G。
8.2 页面支持
支持 3 中页面大小,4KB,16KB,64KB。
使用 CONFIG_ARM64_4K_PAGES、CONFIG_ARM64_16K_PAGES、CONFIG_ARM64_64K_PAGES 设置页面大小。
同时要配置 CONFIG_ARM64_PAGE_SHIFT 8例如设为12,表示 4KB。
8.3 页表支持
至少两级页表,至多支持四级页表,level1 ~ level4
使用 CONFIG_PGTABLE_LEVELS设置页表等级,值为1 ~ 4。
下面以 kernel 5.15 实际使用设置为例:
CONFIG_ARM64_VA_BITS_39=y
CONFIG_ARM64_VA_BITS=39
CONFIG_PGTABLE_LEVELS=3
CONFIG_ARM64_PAGE_SHIFT=12

- TTBRn:由虚拟地址最高位 bit[63] 决定,如果该位为 1,表示这个地址用于内核空间,页表的基地址寄存器用TTBR1;若该位为0,表示这个地址属于用户空间,页表的基地址寄存器用 TTBR0。确定最初的页表基地址寄存器,就可以从中获取 PGD 的页表的 基地址;
- PGD:页表由虚拟地址 bit[38 : 30] 共9个bits 管理512 个表项,每一个表项存放的是下一个页表的基地址,即PMD的 基地址,通过9个bits索引找到确切的页表项;
- PMD:页表由虚拟地址 bit[29 : 21] 共9个bits 管理512 个表项,每一个表项存放的是下一个页表的基地址,即PTE 的 基地址,通过9个bits索引找到确切的页表项;
- PTE:页表由虚拟地址 bit[20 : 12] 共9个bits 管理512 个表项,每一个表项存放的是 物理地址 的 bit[39 : 12],再结合虚拟地址 bit[11 : 0],可以组合成最终的物理地址,完成地址的翻译过程;
基本上内核中关于页表的操作都会围绕着上图进行操作,似乎脱离了代码有点不太合适,那么就来一波fucking source code解析吧,主要讲讲各类page table相关的API。
8.4 源码分析
8.4.1 根据page table 的level不同,选择确实PUD 或者 PMD
arch/arm64/include/asm/pgtable-types.h
typedef struct { pteval_t pte; } pte_t;
#if CONFIG_PGTABLE_LEVELS > 2
typedef struct { pmdval_t pmd; } pmd_t;
#endif
#if CONFIG_PGTABLE_LEVELS > 3
typedef struct { pudval_t pud; } pud_t;
#endif
typedef struct { pgdval_t pgd; } pgd_t;
例如对于 level 为3,分页模型为3级: PGD、PMD、PTE;
8.4.2 针对页表中entry中权限内容设置
arch/arm64/include/asm/pgtable-prot.h
...
#define PTE_WRITE (PTE_DBM) /* same as DBM (51) */
#define PTE_DIRTY (_AT(pteval_t, 1) << 55)
#define PTE_SPECIAL (_AT(pteval_t, 1) << 56)
#define PTE_DEVMAP (_AT(pteval_t, 1) << 57)
#define PTE_PROT_NONE (_AT(pteval_t, 1) << 58) /* only when !PTE_VALID */
...
8.4.3 PGD/PUD/PMD 划分
下面主要包括虚拟地址中PGD/PUD/PMD等的划分,这个与虚拟地址的有效位及分页大小有关,此外还包括硬件页面的定义,TCR寄存器中的设置等。
arch/arm64/include/asm/pgtable-hwdef.h
#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - 3) * (4 - (n)) + 3)
#define PTRS_PER_PTE (1 << (PAGE_SHIFT - 3))
#if CONFIG_PGTABLE_LEVELS > 2
#define PMD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(2)
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE-1))
#define PTRS_PER_PMD PTRS_PER_PTE
#endif
#if CONFIG_PGTABLE_LEVELS > 3
#define PUD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(1)
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE-1))
#define PTRS_PER_PUD PTRS_PER_PTE
#endif
#define PGDIR_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(4 - CONFIG_PGTABLE_LEVELS)
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
#define PTRS_PER_PGD (1 << (MAX_USER_VA_BITS - PGDIR_SHIFT))
...
#define TCR_T0SZ_OFFSET 0
#define TCR_T1SZ_OFFSET 16
#define TCR_T0SZ(x) ((UL(64) - (x)) << TCR_T0SZ_OFFSET)
#define TCR_T1SZ(x) ((UL(64) - (x)) << TCR_T1SZ_OFFSET)
...
- PGDIR_SHIFT: 表示PGD 页表在虚拟地址中的起始偏移量,与 CONFIG_PGTABLE_LEVELS相关,例如 CONFIG_PGTABLE_LEVELS 值为 3,此值为30,即PGD 从bit 30开始偏移;
- PGDIR_SIZE: 表示PGD 页表项所能映射的区域大小;
- PGDIR_MASK: 用来屏蔽 PUD、PMD、PTE 等字段;
- PTRS_PER_PGD: 表示PGD 页表中页表项个数,MAX_USER_VA_BITS 为宏 CONFIG_ARM64_VA_BITS 的值;
PUD、PMD 这里不再果断分析, 需要注意的是:
- PTRS_PER_PUD 和 PTRS_PER_PMD 的值为 PTRS_PER_PTE,此值与 PAGE_SHIFT 有关,例如对于页面大小为 4KB,PAGE_SHIFT 为 12, PTRS_PER_PTE 为 1<<9;
8.4.4 页表设置相关
arch/arm64/include/asm/pgtable.h
...
//判断该页是否在内存中
#define pte_present(pte) (!!(pte_val(pte) & (PTE_VALID | PTE_PROT_NONE)))
//判断该页是否被访问过
#define pte_young(pte) (!!(pte_val(pte) & PTE_AF))
#define pte_special(pte) (!!(pte_val(pte) & PTE_SPECIAL))
//判断该页是否有可写属性
#define pte_write(pte) (!!(pte_val(pte) & PTE_WRITE))
#define pte_user_exec(pte) (!(pte_val(pte) & PTE_UXN))
#define pte_cont(pte) (!!(pte_val(pte) & PTE_CONT))
#define pte_devmap(pte) (!!(pte_val(pte) & PTE_DEVMAP))
...
这里只是简单列举了几个头文件中的部分代码,详细查看源码~~
kernel版本:5.15
源码注释:iliuqi的5.15内核