前言
架构概述
从系统架构来看,目前的服务器大体可以分为三类
- 对称多处理器结构(SMP:Symmetric Multi-Processor)
- 非一致存储访问结构(NUMA:Non-Uniform Memory Access)
- 海量并行处理结构(MPP:Massive Parallel Processing)。
共享存储型多处理机有两种模型
- 均匀存储器存取(Uniform-Memory-Access,简称UMA)模型
- 非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型
这一篇主要阐述现在 计算机系统 中,以内存为研究对象分成的两种架构: NUMA 和 UMA。这里的UMA 和NUMA 是站在处理器的角度进行内存访问时的架构。
另外,本文会简述内存管理发展过程中,与UMA 和NUMA 对应的三种内存模型: FLATMEM、 DISCONTIGMEM、 SPARSEMEM。
基本概念
PF(page frame)
操作系统最重要的作用之一就是管理计算机系统中的各种资源,做为最重要的资源:内存,我们必须管理起来。在 linux 操作系统中,物理内存是按照 pages 来管理的,具体每个 page 的 size 是多少是和硬件以及linux系统配置相关的,4k 是最经典的设定。
因此,对于物理内存来说,可以看成一个个 page 排列组成,每个 page size 所属的内存区域称为 page frame,linux 内核中会创建一个 struct page 的数据结构来管理、跟踪这样的一个个 page。
PFN(page frame number)
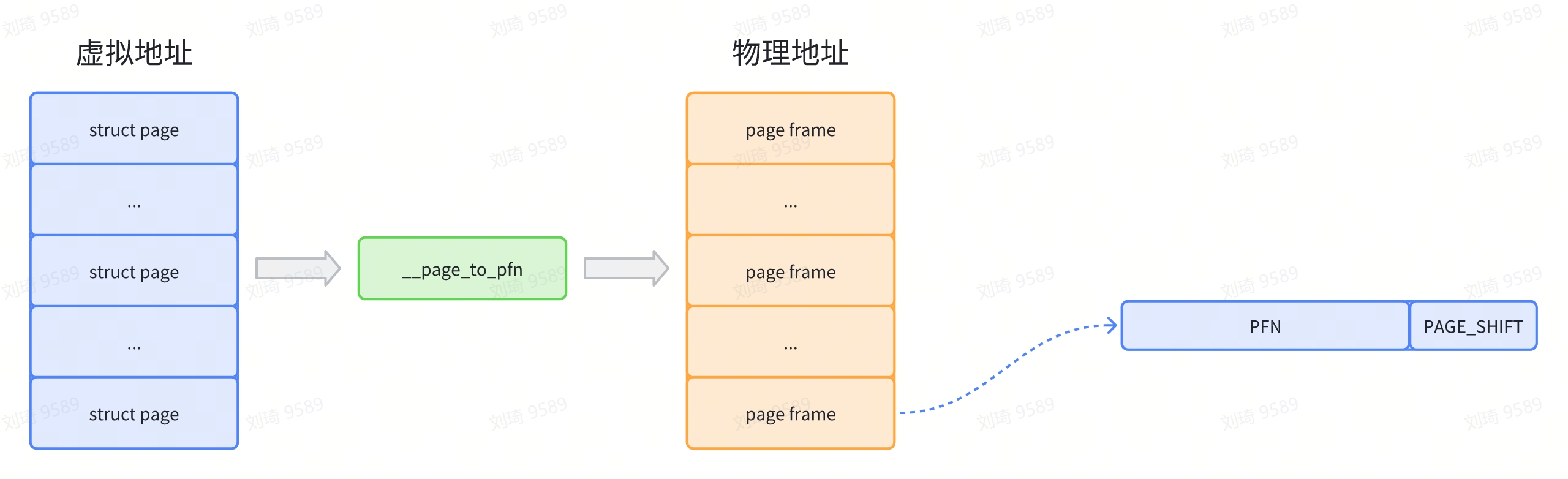
通过上一小节我们得知物理内存时一个个 page frame 组成的。在 linux 内存中将每个 page frame 进行编号,每个 page frame 都有属于自己的编号,这个编号就是 page frame number,即 PFN。
在 linux 内核 early boot 时,会创建一个个 struct page 数据结构与 page frame 对应。为了便于管理,系统提供了两个接口:page_to_pfn() 和 pfn_to_page() 用以在 struct page 和 PFN 之间进行转换。
page :线性地址被分成以固定长度为单位的组,称为页,比如典型的4K大小,页内部连续的线性地址被映射到连续的物理地址中;
page frame :内存被分成固定长度的存储区域,称为页框,也叫物理页。每一个页框会包含一个页,页框的长度和一个页的长度是一致的,在内核中使用struct page来关联物理页。
如下图,PFN从图片中就能看出来了:
内存架构
SMP(Symmetric Multi-Processor)
所谓对称多处理器结构,是指服务器中多个CPU对称工作,无主次或从属关系。
各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的,因此SMP也被称为一致存储器访问结构(UMA:Uniform Memory Access)
对SMP服务器进行扩展的方式包括增加内存、使用更快的CPU、增加CPU、扩充I/O(槽口数与总线数)以及添加更多的外部设备(通常是磁盘存储)。
SMP服务器的主要特征是共享,系统中所有资源(CPU、内存、I/O等)都是共享的。也正是由于这种特征,导致了SMP服务器的主要问题,那就是它的扩展能力非常有限。
对于SMP服务器而言,每一个共享的环节都可能造成SMP服务器扩展时的瓶颈,而最受限制的则是内存。由于每个CPU必须通过相同的内存总线访问相同的内存资源,因此随着CPU数量的增加,内存访问冲突将迅速增加,最终会造成CPU资源的浪费,使CPU性能的有效性大大降低。实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU
在现行的SMP架构中, 发展出 三种模型: UMA、 NUMA 和 COMA。
UMA(Uniform Memory Access)
Uniform Memory Access, 简称 UMA,即统一内存访问架构。内存有统一的结构并且统一寻址。所有的 CPU 都是经过总线到内存控制器再到物理内存,访问相同的 DDR 物理内存。
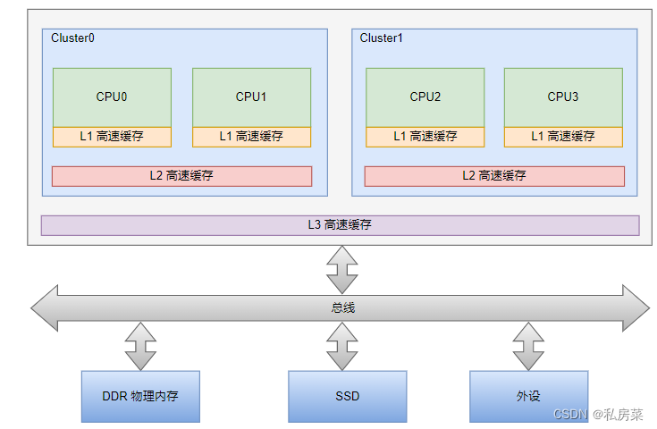
这里有四个CPU,都有L1 高速缓存,其中CPU0 和CPU1 组成一个簇(cluster0),他们共享L2 高速缓存。另外,CPU2 和CPU3 组成一个簇(cluster1),它们共享另外一个L2 高速缓存。4个CPU 都共享同一个L3 高速缓存。最重要一点,它们可以通过系统总线来访问物理内存DDR。
目前大部分嵌入式系统、手机操作系统以及台式机操作系统等采用 UMA 架构。UMA 架构的系统有如下特点:
- 所有硬件资源都是共享的,每个处理器都能访问系统中的内存和外部资源;
- 所有处理器都是平等关系;
- 统一寻址访问内存;
- 处理器和内存通过内部的一条总线连接在一起;
缺点是:
- 随着 CPU 数量增加,每个 CPU 分到的总线的带宽越来越少;
- 总线要与所有的 CPU 相连,那么CPU 越多,总线就越长,时延就会增加;
因为所有对等的处理器都通过一条总线连接,随着处理器数量增多,系统总线称为系统的最大瓶颈。为了解决这个瓶颈,实现了一个新的架构 NUMA。
NUMA(Non-Uniform Memory Access)
Non-Uniform Memory Access, 简称NUMA,即非统一内存访问架构。系统中有 多个内存节点 和 多个CPU 簇,首先整个内存体系可以作为一个整体,任何 CPU 都可以访问,但是,CPU 访问本地内存节点时拥有更小的延迟和更大的带宽,CPU 访问远端的内存节点速度要慢一点。
另外,每个CPU 除了拥有本地的内存节点之外,还可以拥有本地总线。例如 PCIE、SATA 等。

里还是有四个CPU,其中CPU0 和CPU1 组成一个节点(Node0),它们可以通过系统总线访问本地DDR 物理内存,同理,CPU2 和CPU3 组成另外一个节点(Node1),它们也可以通过系统总线访问本地的DDR 物理内存。如果两个节点通过超路径互连(Ultra Path Interconnect, UPI) 总线连接,那么CPU0 可以通过这个内部总线访问远端的内存节点的物理内存,但是访问速度要比访问本地物理内存慢很多。
在 buddy 内存管理中,内存通过数据结构 pglist_data 进行管理,每个 pglist_data 中会将内存分成不同的zone 细分管理。对于 NUMA 架构来说每个 Node 对应一个 pglist_data 数据结构,而对于 UMA 架构,系统只有一个 pglist_data 来管理。
COMA
Cache-Only Memory Access,简称 COMA,即只用高速缓存访问架构。是 NUMA 的一种特例,只是将后者中分布主存储器换成高速缓存。
内存架构总结
| 概念 | 描述 | 特点 |
|---|---|---|
| SMP | 称为共享存储型多处理机(Shared Memory mulptiProcessors), 也称为对称型多处理机(Symmetry MultiProcessors) | 将多个处理器与一个集中的存储器和I/O总线相连。所有处理器只能访问同一个物理存储器。很显然,SMP的缺点是可伸缩性有限,因为在存储器和I/O接口达到饱和的时候,增加处理器并不能获得更高的性能 |
| UMA | 称为均匀存储器存取(Uniform-Memory-Access) | 物理存储器被所有处理机均匀共享。所有处理机对所有存储字具有相同的存取时间,这就是为什么称它为均匀存储器存取的原因。每台处理机可以有私用高速缓存,外围设备也以一定形式共享。 |
| NUMA | 非均匀存储器存取(Nonuniform-Memory-Access) | 其访问时间随存储字的位置不同而变化。其共享存储器物理上是分布在所有处理机的本地存储器上。所有本地存储器的集合组成了全局地址空间,可被所有的处理机访问。处理机访问本地存储器是比较快的,但访问属于另一台处理机的远程存储器则比较慢,因为通过互连网络会产生附加时延。 |
| COMA | 只用高速缓存的存储器结构(Cache-Only Memory Architecture) | 一种只用高速缓存的多处理机。COMA模型是NUMA机的一种特例,只是将后者中分布主存储器换成了高速缓存, 在每个处理机结点上没有存储器层次结构,全部高速缓冲存储器组成了全局地址空间。远程高速缓存访问则借助于分布高速缓存目录进行。是CC-NUMA体系结构的竞争者,两者拥有相同的目标,但实现方式不同。COMA节点不对内存部件进行分布,也不通过互连设备使整个系统保持一致性。COMA节点没有内存,只在每个Quad中配置大容量的高速缓存。 |
从 CPU 角度看物理内存模型
内核是以页为基本单位对物理内存进行管理的,通过将物理内存划分为一页一页的内存块,每页大小为 4K。一页大小的内存块在内核中用 struct page 结构体来进行管理,struct page 中封装了每页内存块的状态信息,比如:组织结构,使用信息,统计信息,以及与其他结构的关联映射信息等。
而为了快速索引到具体的物理内存页,内核为每个物理页 struct page 结构体定义了一个索引编号:PFN(Page Frame Number)。PFN 与 struct page 是一一对应的关系。
内核提供了两个宏来完成 PFN 与 物理页结构体 struct page 之间的相互转换。它们分别是 page_to_pfn 与 pfn_to_page。
内核中{% label 如何组织管理这些物理内存页 struct page 的方式我们称之为做物理内存模型 %},不同的物理内存模型,应对的场景以及 page_to_pfn 与 pfn_to_page 的计算逻辑都是不一样的。
Linux为了高效管理物理内存和快速获取物理内存布局,提供了三种内存模型与之对应,分别是 FLATMEM 、 DISCONTIGMEM 、 SPARSEMEM。三种模型的数据结构定义在: include/asm-generic/memory_model.h
FLATMEM 平坦内存模型
flat 中文意思就是水平、平坦的,按照字面意思理解该模型即位 平坦模型,它是linux最早的模型管理(自0.11版本就存在),一直在早期支撑了linux发展,其他两种内存管理模型也是在该模型基础上进化,所以要理解linux 内存管理,必须要了解此模型,包括很多概念比如 PFN,页等都是在该模型概念基础上进行提出的。
该模型适用于具有连续或大部分连续物理内存的非 NUMA 系统。
我们先把物理内存想象成一片地址连续的存储空间,在这一大片地址连续的内存空间中,内核将这块内存空间分为一页一页的内存块 struct page 。
由于这块物理内存是连续的,物理地址也是连续的,划分出来的这一页一页的物理页必然也是连续的,并且每页的大小都是固定的,所以我们很容易想到用一个数组来组织这些连续的物理内存页 struct page 结构,其在数组中对应的下标即为 PFN 。这种内存模型就叫做平坦内存模型 FLATMEM 。
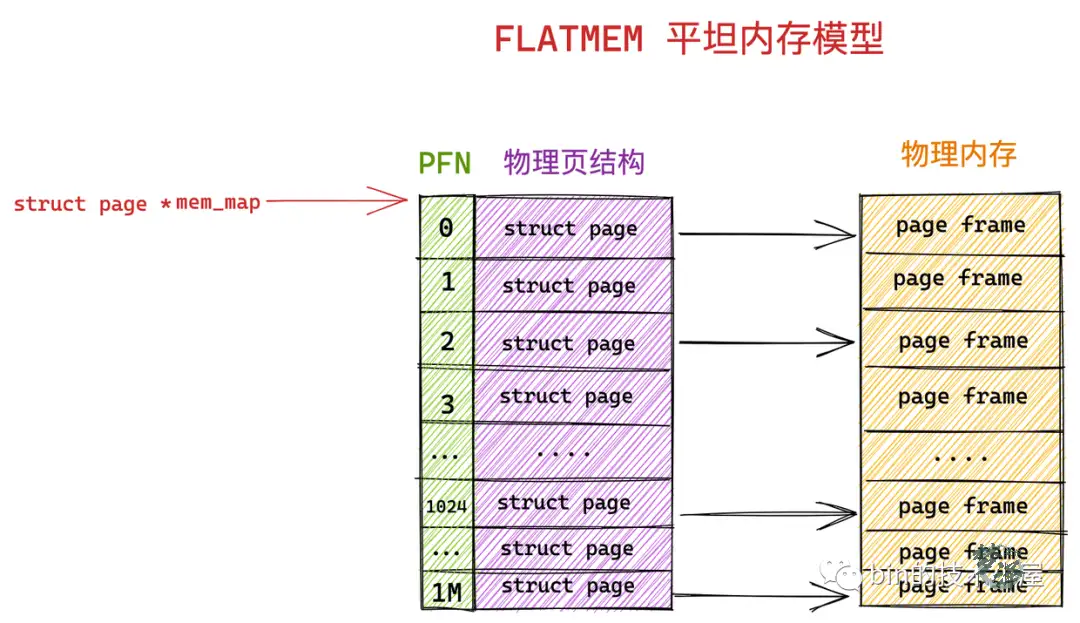
内核中使用了一个 mem_map 的全局数组用来组织所有划分出来的物理内存页。mem_map 全局数组的下标就是相应物理页对应的 PFN 。
在平坦内存模型下 ,page_to_pfn 与 pfn_to_page 的计算逻辑就非常简单,本质就是基于 mem_map 数组进行偏移操作。
#ifndef ARCH_PFN_OFFSET
#define ARCH_PFN_OFFSET (0UL)
#endif
#if defined(CONFIG_FLATMEM)
#define __pfn_to_page(pfn) (mem_map + ((pfn)-ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page)-mem_map) + ARCH_PFN_OFFSET)
#endif
从代码中也可以看到此模型是比较简单的映射,mem_map的与 page 对应关系偏移 ARCH_PFN_OFFSET 为0,当其为0 时,pfn 就是mem_map 的索引,通过pfn 就可以获取mem_map 数组中的page,通过page 也可以退出mem_map 的pfn。
另外,此头文件中也定义了pfn和物理内存phys 的转换关系:
include/asm-generic/memory_model.h
#define __phys_to_pfn(paddr) PHYS_PFN(paddr)
#define __pfn_to_phys(pfn) PFN_PHYS(pfn)
PHYS_PFN 和PFN_PHYS 定义在include/linux/pfn.h 中:
#define PFN_PHYS(x) ((phys_addr_t)(x) << PAGE_SHIFT)
#define PHYS_PFN(x) ((unsigned long)((x) >> PAGE_SHIFT))
可以看到物理内存往右偏移PAGE_SHIFT(例如,4k page 为12)位,就是物理内存的页帧号。在博文 《页面查询过程简述》 中已经提到过物理内存的组成,可以对照看。
DISCONTIGMEM 非连续内存模型
FLATMEM 平坦内存模型只适合管理一整块连续的物理内存,而对于多块非连续的物理内存来说使用 FLATMEM 平坦内存模型进行管理则会造成很大的内存空间浪费。
因为 FLATMEM 平坦内存模型是利用 mem_map 这样一个全局数组来组织这些被划分出来的物理页 page 的,而对于物理内存存在大量不连续的内存地址区间这种情况时,这些不连续的内存地址区间就形成了内存空洞。
由于用于组织物理页的底层数据结构是 mem_map 数组,数组的特性又要求这些物理页是连续的,所以只能为这些内存地址空洞也分配 struct page 结构用来填充数组使其连续。
而每个 struct page 结构大部分情况下需要占用 40 字节(struct page 结构在不同场景下内存占用会有所不同,这一点我们后面再说),如果物理内存中存在的大块的地址空洞,那么为这些空洞而分配的 struct page 将会占用大量的内存空间,导致巨大的浪费。
为了组织和管理这些不连续的物理内存,内核于是引入了 DISCONTIGMEM 非连续内存模型,用来消除这些不连续的内存地址空洞对 mem_map 的空间浪费。
在 DISCONTIGMEM 非连续内存模型中,内核将物理内存从宏观上划分成了一个一个的节点 node (微观上还是一页一页的物理页),每个 node 节点管理一块连续的物理内存。这样一来这些连续的物理内存页均被划归到了对应的 node 节点中管理,就避免了内存空洞造成的空间浪费。
DISCONTIGMEM 在 FLATMEM 模型基础上引进了 pg_data_t 结构。
在架构设置的时候会调用 free_area_init_node() 为系统中每个node 初始化 pg_data_t 数据结构,以及该数据结构中的 node_mem_map 数组。node_mem_map 就类似于FLATMEM 中的mem_map,该node 中的每个page 都会与node_mem_map 对应。模型如图所示:
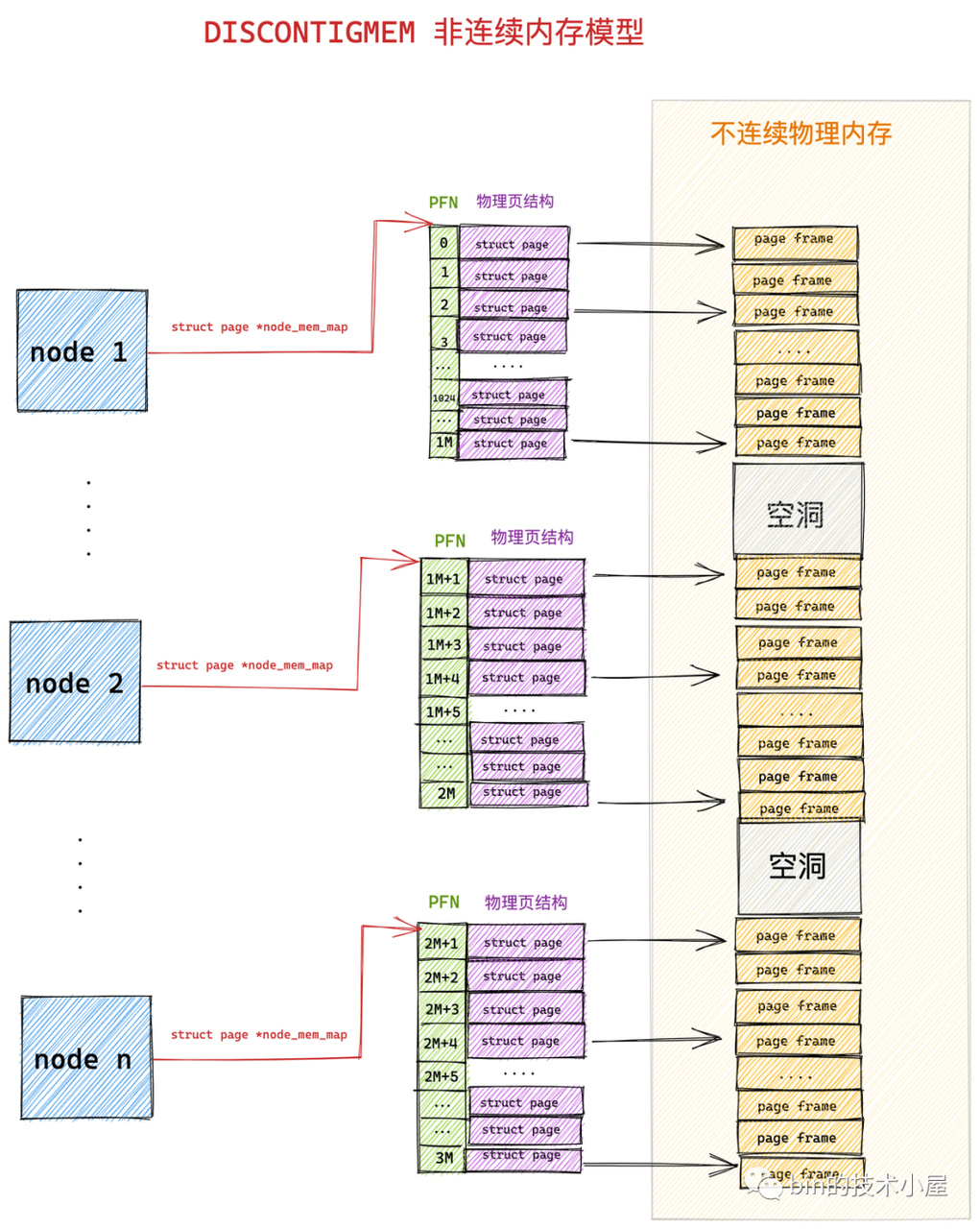
内核中使用 struct pglist_data 表示用于管理连续物理内存的 node 节点(内核假设 node 中的物理内存是连续的),既然每个 node 节点中的物理内存是连续的,于是在每个 node 节点中还是采用 FLATMEM 平坦内存模型的方式来组织管理物理内存页。每个 node 节点中包含一个 struct page *node_mem_map 数组,用来组织管理 node 中的连续物理内存页。
typedef struct pglist_data {
#ifdef CONFIG_FLATMEM
struct page *node_mem_map;
#endif
}
我们可以看出 DISCONTIGMEM 非连续内存模型其实就是 FLATMEM 平坦内存模型的一种扩展,在面对大块不连续的物理内存管理时,通过将每段连续的物理内存区间划归到 node 节点中进行管理,避免了为内存地址空洞分配 struct page 结构,从而节省了内存资源的开销。
由于引入了 node 节点这个概念,所以在 DISCONTIGMEM 非连续内存模型下 page_to_pfn 与 pfn_to_page 的计算逻辑就比 FLATMEM 内存模型下的计算逻辑多了一步定位 page 所在 node 的操作。
- 通过 arch_pfn_to_nid 可以根据物理页的 PFN 定位到物理页所在 node。
- 通过 page_to_nid 可以根据物理页结构 struct page 定义到 page 所在 node。
//include/asm-generic/memory_model.h
#ifndef arch_pfn_to_nid
#define arch_pfn_to_nid(pfn) pfn_to_nid(pfn)
#endif
#ifndef arch_local_page_offset
#define arch_local_page_offset(pfn, nid) \
((pfn) - NODE_DATA(nid)->node_start_pfn)
#endif
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\
})
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \
(unsigned long)(__pg - __pgdat->node_mem_map) + \
__pgdat->node_start_pfn; \
})
从代码的意思看是先通过pfn 或者page 找到nid,在通过 nid 确定 pg_data_t,这里宏 pfn_to_nid() 在别的头文件中定义,我们看到头文件 memory_model.h 都是在其他头文件的最后被 include。例如在 mmzone.h 中定义了 pfn_to_nid():
include/linux/mmzone.h
#ifdef CONFIG_NUMA
#define pfn_to_nid(pfn) \
({ \
unsigned long __pfn_to_nid_pfn = (pfn); \
page_to_nid(pfn_to_page(__pfn_to_nid_pfn)); \
})
#else
#define pfn_to_nid(pfn) (0)
#endif
SPARSEMEM 稀疏内存模型
随着内存技术的发展,内核可以支持物理内存的热插拔了,这样一来物理内存的不连续就变为常态了,在上小节介绍的 DISCONTIGMEM 内存模型中,其实每个 node 中的物理内存也不一定都是连续的。
DISCONTIGMEM 模型同样存在不小的弊端:紧凑型线性映射和不支持内存热拔插。DISCONTIGMEM 模型本质是一个 node 上的 FLATMEM,随着node的增加或者内存热拔插长场景的出现,同一个 node 内,也可能出现大量不连续内存,导致 DISCONTIGMEM 模型开销越来越大。
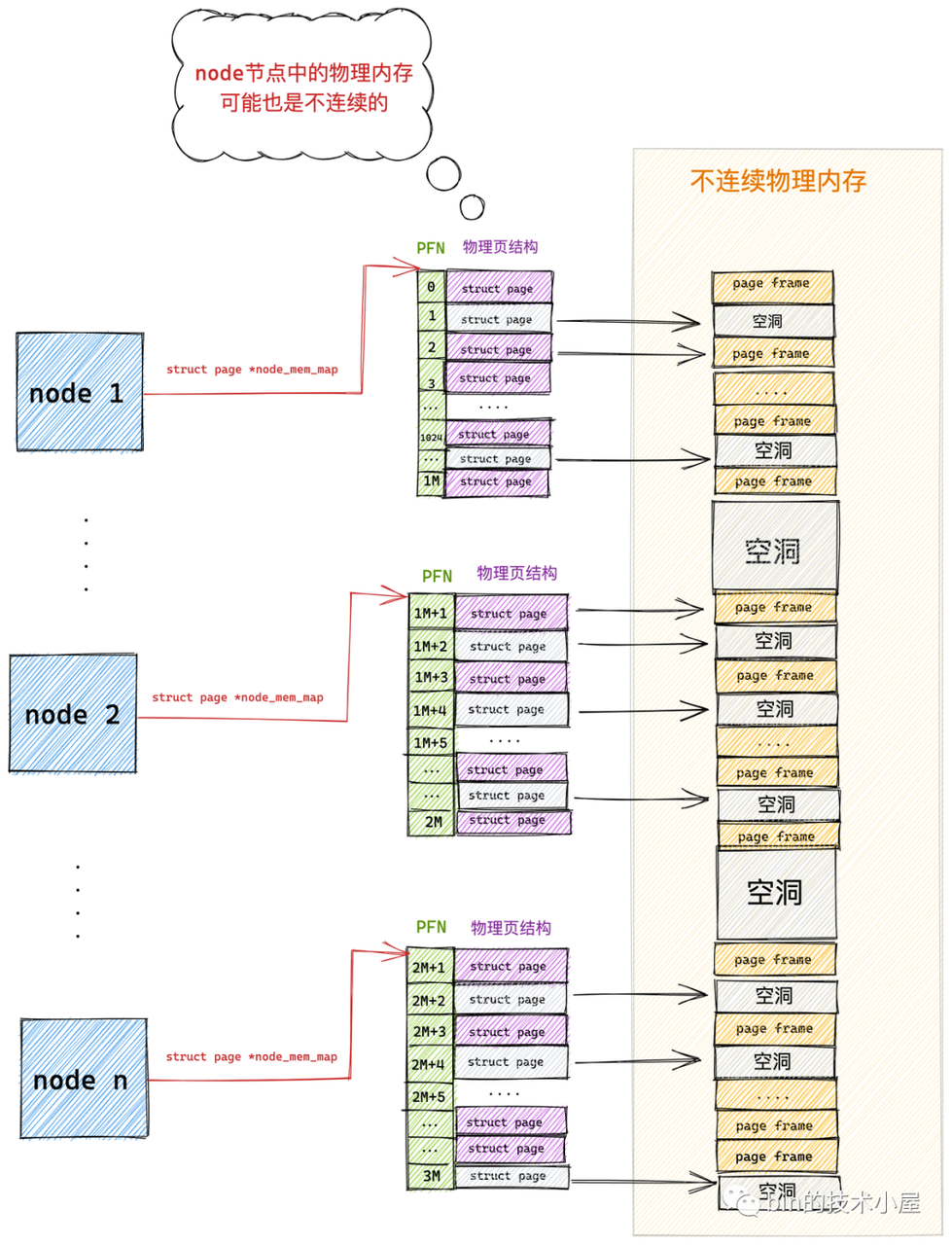
这时候,一个全新的 稀松内存模型( sparse memory model)被引入到内核中。
SPARSEMEM 稀疏内存模型的核心思想就是对粒度更小的连续内存块进行精细的管理,用于管理连续内存块的单元被称作 section 。物理页大小为 4k 的情况下, section 的大小为 128M ,物理页大小为 16k 的情况下, section 的大小为 512M。
在内核中用 struct mem_section 结构体表示 SPARSEMEM 模型中的 section。
struct mem_section {
unsigned long section_mem_map;
...
}
SPARSEMEM 模型使用一个 struct mem_section **mem_section 的二维数组来记录内存布局:
// mm/sparse.c
/*
* Permanent SPARSEMEM data:
*
* 1) mem_section - memory sections, mem_map's for valid memory
*/
#ifdef CONFIG_SPARSEMEM_EXTREME
struct mem_section **mem_section;
#else
struct mem_section mem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT]
____cacheline_internodealigned_in_smp;
#endif
EXPORT_SYMBOL(mem_section);
数组中每一个一级指针都指向一片的物理内存空间,section 的size 和section 的最大个数,由MAX_PHYSMEM_BITS和 SECTION_SIZE_BITS 计算出,而这两个宏定义受支持 SPARSEMEM 模型的框架决定,例如对于ARM64 平台架构:
#ifdef CONFIG_SPARSEMEM
#define MAX_PHYSMEM_BITS CONFIG_ARM64_PA_BITS
#if defined(CONFIG_ARM64_4K_PAGES) || defined(CONFIG_ARM64_16K_PAGES)
#define SECTION_SIZE_BITS 27
#else
#define SECTION_SIZE_BITS 29
#endif /* CONFIG_ARM64_4K_PAGES || CONFIG_ARM64_16K_PAGES */
#endif /* CONFIG_SPARSEMEM*/
比如我司手机配置
CONFIG_ARM64_PA_BITS=48
CONFIG_ARM64_4K_PAGES=y
# CONFIG_ARM64_16K_PAGES is not set
# CONFIG_ARM64_64K_PAGES is not set
这里的 MAX_PHYSMEM_BITS则为48,SECTION_SIZE_BITS为27
物理内存大小支持为 2^48,区间为[ 0, 2^48)。每个 section 大小为 2^27,区间为[ 0, 2^27),也就是每个section 可以囊括地址范围为 128M,所以section 的数量则为 2^(48-27)
所以,系统定义的 SECTIONS_SHIFT 为:
#define SECTIONS_SHIFT (MAX_PHYSMEM_BITS - SECTION_SIZE_BITS)

在SPARSEMEM中,由于是全局的 mem_section 结构,故可以将所有的 mem_section 结构体从下标为 0 开始编号,一直累加到最后一个。
在 SPARSEMEM 稀疏内存模型下 page_to_pfn 与 pfn_to_page 的计算逻辑又发生了变化。
- 在 page_to_pfn 的转换中,首先需要通过 page_to_section 根据 struct page 结构定位到 mem_section 数组中具体的 section 结构。然后在通过 section_mem_map 定位到具体的 PFN。
在 struct page 结构中有一个
unsigned long flags属性,在 flag 的高位 bit 中存储着 page 所在 mem_section 数组中的索引,从而可以定位到所属 section。
- 在 pfn_to_page 的转换中,首先需要通过 __pfn_to_section 根据 PFN 定位到 mem_section 数组中具体的 section 结构。然后在通过 PFN 在 section_mem_map 数组中定位到具体的物理页 Page 。
PFN 的高位 bit 存储的是全局数组 mem_section 中的 section 索引,PFN 的低位 bit 存储的是 section_mem_map 数组中具体物理页 page 的索引。
#if defined(CONFIG_SPARSEMEM)
/*
* Note: section's mem_map is encoded to reflect its start_pfn.
* section[i].section_mem_map == mem_map's address - start_pfn;
*/
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
int __sec = page_to_section(__pg); \
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
})
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})
#endif
当启动 CONFIG_SPARSEMEM_VMEMMAP,即开启 vmemmap 功能后,转换关系直接使用 vmemmap:
#if defined(CONFIG_FLATMEM)
#ifndef ARCH_PFN_OFFSET
#define ARCH_PFN_OFFSET (0UL)
#endif
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
ARCH_PFN_OFFSET)
#elif defined(CONFIG_SPARSEMEM_VMEMMAP)
/* memmap is virtually contiguous. */
#define __pfn_to_page(pfn) (vmemmap + (pfn))
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
#elif defined(CONFIG_SPARSEMEM)
而在我司使用的项目flame中也是开启了CONFIG_SPARSEMEM_VMEMMAP
CONFIG_SPARSEMEM_VMEMMAP_ENABLE=y
CONFIG_SPARSEMEM_VMEMMAP=y
{% tip success %}
关于内存架构以及内存模型的详细描述,建议观看【深入理解 Linux 物理内存管理】,这位作者写的关于内存相关的文章确实非常的经典全面
{% endtip %}