
0. 前言
在[linux内存管理] 第011篇 内存模型之Sparse Memory Model中,我们分析了 bootmem_init函数的 sparse_init。而本章暂时停下对 bootmem_init后续流程的分析,梳理一下一些基本的知识点。
在linux里将内存分为三个层次进行了管理,分别是 page、zone以及 node。而这三者分别对应linux物理内存的三大结构体 struct page、struct zone 以及 struct pglist_data。
| 层次 | 描述 |
|---|---|
| 存储节点(node) | CPU被划分为多个节点(node),内存则被分簇,每个CPU对应一个本地的物理内存,即一个CPU-node对应一个内存bank,即每个内存簇被认为是一个节点。UMA架构下只存在一个node |
| 管理区(zone) | 每个物理内存节点node被划分为多个内存管理区域,用于表示不同范围的内存,内核可以使用不同映射方式映射物理内存 |
| 页面(page) | 内存被细分为多个页面帧,页面是最基本的页面分配的单位 |
好了,本章就开始讲 zone啦!
1. ZONE概述
内存管理域(zone)是 Linux 内核内存管理机制的重要组成部分,它根据不同内存区域的特点(如 DMA、普通内存、可移动内存等)对物理内存进行合理划分。内存的 zone 分类有助于提高内存分配的效率,确保系统在处理不同类型的内存需求时能更好地发挥性能。
Zone 是 Linux 内存管理中的逻辑分区,主要用来反映硬件内存布局的差异,满足不同的内存分配需求。例如,某些硬件设备只能访问低地址的内存区域,而某些高地址的内存则可能有更高的性能。
为了支持NUMA模型,也即CPU对不同内存单元的访问时间可能不同,此时系统的物理内存被划分为几个节点(node),一个node对应一个内存簇bank,即每个内存簇被认为是一个节点。
- 首先, 内存被划分为结点. 每个节点关联到系统中的一个处理器, 内核中表示为
pg_data_t的实例. 系统中每个节点被链接到一个以NULL结尾的pgdat_list链表中。- 每个
pglist_data表示一个 NUMA 节点上的内存集合。 - 在非 NUMA 系统中,整个系统的内存只有一个
pglist_data,即contig_page_data。 - 在 NUMA 系统中,每个 NUMA 节点都有自己的
pglist_data。
- 每个
- 接着各个节点又被划分为内存管理区域, 一个管理区域通过
struct zone描述- 管理特定区域内的页面信息,包括空闲页列表、分配器等。
- 每个
zone包含一个free_area数组,管理按页大小(order)组织的内存块
1. 数据结构
1.1 zone type
正如上面所提到过,内存是分类型的,Linux内核对于不同区域的内存采用了不同的管理方式以及映射方式。为了解决这些制约条件,Linux使用了三种区:
ZONE_DMA:这个区包含的页用来执行DMA操作ZONE_NORMAL:这个区包含的都是能正常映射的页ZONE_HIGHMEM:这个区被称为”高端内存“,其中的页不能被永久映射到内核地址空间
而为了兼容一些设备的热插拔支持以及内存碎片化的处理,内核引入了一些逻辑上的内存区
ZONE_MOVEALE:内核定义了一个伪内存域ZONE_MOVABLE,在防止物理内存碎片的机制memory migration中需要使用该内存域,防止物理内存碎片的极致使用。ZONE_DEVICE:为支持热插拔设备而分配的Non Volatile Memory非易失性内存
这部分定义可以在 mmzone.h中的 enum zone_type中得到。
enum zone_type {
/*
* ZONE_DMA and ZONE_DMA32 are used when there are peripherals not able
* to DMA to all of the addressable memory (ZONE_NORMAL).
* On architectures where this area covers the whole 32 bit address
* space ZONE_DMA32 is used. ZONE_DMA is left for the ones with smaller
* DMA addressing constraints. This distinction is important as a 32bit
* DMA mask is assumed when ZONE_DMA32 is defined. Some 64-bit
* platforms may need both zones as they support peripherals with
* different DMA addressing limitations.
*/
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
/*
* ZONE_MOVABLE is similar to ZONE_NORMAL, except that it contains
* movable pages with few exceptional cases described below. Main use
* cases for ZONE_MOVABLE are to make memory offlining/unplug more
* likely to succeed, and to locally limit unmovable allocations - e.g.,
* to increase the number of THP/huge pages. Notable special cases are:
*
* 1. Pinned pages: (long-term) pinning of movable pages might
* essentially turn such pages unmovable. Therefore, we do not allow
* pinning long-term pages in ZONE_MOVABLE. When pages are pinned and
* faulted, they come from the right zone right away. However, it is
* still possible that address space already has pages in
* ZONE_MOVABLE at the time when pages are pinned (i.e. user has
* touches that memory before pinning). In such case we migrate them
* to a different zone. When migration fails - pinning fails.
* 2. memblock allocations: kernelcore/movablecore setups might create
* situations where ZONE_MOVABLE contains unmovable allocations
* after boot. Memory offlining and allocations fail early.
* 3. Memory holes: kernelcore/movablecore setups might create very rare
* situations where ZONE_MOVABLE contains memory holes after boot,
* for example, if we have sections that are only partially
* populated. Memory offlining and allocations fail early.
* 4. PG_hwpoison pages: while poisoned pages can be skipped during
* memory offlining, such pages cannot be allocated.
* 5. Unmovable PG_offline pages: in paravirtualized environments,
* hotplugged memory blocks might only partially be managed by the
* buddy (e.g., via XEN-balloon, Hyper-V balloon, virtio-mem). The
* parts not manged by the buddy are unmovable PG_offline pages. In
* some cases (virtio-mem), such pages can be skipped during
* memory offlining, however, cannot be moved/allocated. These
* techniques might use alloc_contig_range() to hide previously
* exposed pages from the buddy again (e.g., to implement some sort
* of memory unplug in virtio-mem).
* 6. ZERO_PAGE(0), kernelcore/movablecore setups might create
* situations where ZERO_PAGE(0) which is allocated differently
* on different platforms may end up in a movable zone. ZERO_PAGE(0)
* cannot be migrated.
* 7. Memory-hotplug: when using memmap_on_memory and onlining the
* memory to the MOVABLE zone, the vmemmap pages are also placed in
* such zone. Such pages cannot be really moved around as they are
* self-stored in the range, but they are treated as movable when
* the range they describe is about to be offlined.
*
* In general, no unmovable allocations that degrade memory offlining
* should end up in ZONE_MOVABLE. Allocators (like alloc_contig_range())
* have to expect that migrating pages in ZONE_MOVABLE can fail (even
* if has_unmovable_pages() states that there are no unmovable pages,
* there can be false negatives).
*/
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
假设设备的物理内存大小为 8GB(即 0x0 - 0x200000000)。ARM64 和 Android 的内存管理通常会根据设备需求划分以下区域:
| Zone 类型 | 地址范围 | 大小 | 用途说明 |
|---|---|---|---|
ZONE_DMA |
0x00000000 - 0x01000000 |
16MB | DMA 专用内存,主要支持旧设备。 |
ZONE_DMA32 |
0x01000000 - 0x100000000 |
4GB | 32 位设备的 DMA 内存,主要用于硬件兼容性。 |
ZONE_NORMAL |
0x100000000 - 0x200000000 |
4GB | 普通内存区域,供内核和用户空间直接使用。 |
ZONE_MOVABLE |
(可选,根据配置) | - | 动态分配内存,用于减少碎片化或支持热插拔。 |
ZONE_DEVICE |
(视具体硬件配置) | - | 设备专用内存区域,例如 GPU 或 NVM 内存映射。 |
我们可以从kernel的启动日志中获知当前设备所涉及的zone_type:
[ 0.000000][ T0] Zone ranges:
[ 0.000000][ T0] DMA32 empty
[ 0.000000][ T0] Normal [mem 0x0000000040000000-0x000000023fffffff]
[ 0.000000][ T0] Movable zone start for each node
[ 0.000000][ T0] Early memory node ranges
[ 0.000000][ T0] node 0: [mem 0x0000000040000000-0x00000000456fffff]
[ 0.000000][ T0] node 0: [mem 0x0000000045700000-0x0000000045cfffff]
[ 0.000000][ T0] node 0: [mem 0x0000000045d00000-0x0000000045dfffff]
[ 0.000000][ T0] node 0: [mem 0x0000000045e00000-0x0000000045f3ffff]
[ 0.000000][ T0] node 0: [mem 0x0000000045f40000-0x0000000045ffefff]
[ 0.000000][ T0] node 0: [mem 0x0000000045fff000-0x0000000047ffffff]
[ 0.000000][ T0] node 0: [mem 0x0000000048000000-0x000000004aafffff]
[ 0.000000][ T0] node 0: [mem 0x000000004ab00000-0x00000000513fffff]
[ 0.000000][ T0] node 0: [mem 0x0000000051400000-0x00000000518fffff]
[ 0.000000][ T0] node 0: [mem 0x0000000051900000-0x0000000056516fff]
[ 0.000000][ T0] node 0: [mem 0x0000000056517000-0x000000005fffffff]
[ 0.000000][ T0] node 0: [mem 0x0000000060000000-0x00000000638fffff]
[ 0.000000][ T0] node 0: [mem 0x0000000063900000-0x000000007bafffff]
[ 0.000000][ T0] node 0: [mem 0x0000000080000000-0x000000023fffffff]
[ 0.000000][ T0] Initmem setup node 0 [mem 0x0000000040000000-0x000000023fffffff]
[ 0.000000][ T0] On node 0, zone Normal: 17664 pages in unavailable ranges
我们可以从这段日志中获取到如下的信息:
-
无
ZONE_DMA32区域 -
ZONE_NORMAL区域范围是: [0x0000000040000000−0x000000023fffffff]- 起始地址为
0x40000000(1GB)。 - 结束地址为
0x23FFFFFF(9GB)。 - 这是主内存区域,用于内核和用户空间分配。
- 起始地址为
-
所有内存分布在 Node 0 中,说明系统是 UMA(统一内存访问)架构
-
17664 页不可用
- 每页大小通常为 4KB。
- 不可用内存总计为: 17664×4KB=69MB
- 这些内存可能被设备保留(例如,内核、设备固件、保留区)
1.2 struct zone
内核将每个簇所对应的node又被分成称为管理区(zone)的块,他们各自描述在内存中的范围。一个管理区(zone)由 struct zone结构体来描述。
zone对象用于跟踪诸如页面使用情况的统计数, 空闲区域信息和锁信息。里面保存着内存使用状态信息,如page使用统计, 未使用的内存区域,互斥访问的锁(LOCKS)等。
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long _watermark[NR_WMARK]; ///水位线,包括高水位,低水位,最低水位
unsigned long watermark_boost; ///临时水位线,防止外碎片化的优化
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES];///防止页面分配器过度使用低端zone的内存
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat; ///指向内存节点
struct per_cpu_pages __percpu *per_cpu_pageset; ///用于维护每个CPU的单页面,申请单个页面时,减少自旋锁的竞争
struct per_cpu_zonestat __percpu *per_cpu_zonestats;
/*
* the high and batch values are copied to individual pagesets for
* faster access
*/
int pageset_high;
int pageset_batch;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags; ///存储页块的MIGRATE_TYPES类型的内存空间
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn; ///zone的起始页帧号
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* present_early_pages is present pages existing within the zone
* located on memory available since early boot, excluding hotplugged
* memory.
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* cma pages is present pages that are assigned for CMA use
* (MIGRATE_CMA).
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*/
/*
managed_pages: zone中被伙伴系统管理的页面数量
spanned_pages:zone跨越总页数,包括空洞
present_pages:zone实际管理的页面数量(物理页,不含空洞)
spanned_pages = zone_end_pfn - zone_start_pfn;
present_pages = spanned_pages - holes_pages;
managed_pages = present_pages - reserved_pages;
*/
atomic_long_t managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
#if defined(CONFIG_MEMORY_HOTPLUG)
unsigned long present_early_pages;
#endif
#ifdef CONFIG_CMA
unsigned long cma_pages;
#endif
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER]; ///伙伴系统所需的核心数据结构,管理空闲页块(page block)链表的数组
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock; ///热门锁,要防止高速缓存造成的内存颠簸
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_) ///填充cacheline,防止内存颠簸
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[ASYNC_AND_SYNC];
unsigned long compact_init_migrate_pfn;
unsigned long compact_init_free_pfn;
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
* compact_order_failed is the minimum compaction failed order.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; ///zone计数值
atomic_long_t vm_numa_event[NR_VM_NUMA_EVENT_ITEMS];
} ____cacheline_internodealigned_in_smp; ///高频调用数据,以L1高速缓存对齐
这个结构体涉及的成员数量很多,这里介绍重要的成员变量:
| 成员 | 解释 |
|---|---|
| _watermark | 每个 zone 在系统启动时会计算出3个水位值, 分别为 WMAKR_MIN,WMARK_LOW, WMARK_HIGH水位, 这在页面分配器和 kswapd 页面回收中会用到 |
| watermark_boost | 记录zone 需要boost 时的boost 数值,默认值为15000,按照计算是boost/10000,即当需要boost 时,会将水位提高到high 水位的1.5倍 |
| lowmem_reserve | 为其他zone 设置的reserve 值,即其他zone 借内存时需要为本zone 保留的物理内存 |
| zone_pgdat | 记录当前zone 所处的 pglist_data 节点 |
| pageset | page管理的数据结构对象,内部有一个page的列表(list)来管理。每个CPU维护一个page list,避免自旋锁的冲突。这个数组的大小和NR_CPUS(CPU的数量)有关,这个值是编译的时候确定的 |
| zone_start_pfn | 记录该zone 的起始物理PFN |
| managed_pages | 该zone 留给buddy 算法所管理的物理内存,present_pages - memmap_pages - dma_reserve(通常为0) |
| spanned_pages | 该zone 管理的总的物理内存,zone_end_pfn - zone_start_pfn,包括hole pages |
| present_pages | 该zone 管理的实际物理内存,spanned_pages - hole pages |
| name | zone 的名称 |
| initialized | zone 是否初始化完成 |
| free_area | buddy 算法的核心数据结构,管理空闲页块(page block)链表的数组,数组总大小是MAX_ORDER,根据 CONFIG_FORCE_MAX_ZONEORDER 来确定,如果没有使能该CONFIG,则默认为11。即buddy 算法管理 order 0 ~ 10(2^0 ~ 2^10 pages) ,每一个order 都会有一个free_list 对应,而该free_list 管理的是 migrate,后面会详细解读该数据结构 |
| lock | 并行访问时用于保护zone 的自旋锁 |
| vm_stat | 用以记录 zone 的vm状态。注意数组个数为 NR_VM_ ZONE _STAT_ITEMS,与node 中的vmstat 不一样,详细查看: /proc/vmstat |
| vm_numa_stat | 用以记录NUMA 的vm 状态。对于UMA 架构,NR_VM_NUMA_STAT_ITEMS 的值为 0 |
在看到这个结构体时,我们可以看到其中有3个比较奇怪的变量:
- ZONE_PADDING(_pad1_)
- ZONE_PADDING(_pad2_)
- ZONE_PADDING(_pad3_)
那这个是用来干嘛的呢?
1.2.1 ZONE_PADDING
在 Linux 内核中,ZONE_PADDING 是一个用于 内存对齐和缓存优化 的概念。它的目的是在某些特定情况下对 struct zone 的数据结构进行填充,确保不同内存区域(zones)的元数据不共享缓存行,从而避免缓存伪共享问题(cache false sharing)。
假设 struct zone 的大小为 96 字节,而 CACHE_LINE_SIZE 是 128 字节:
- 通过
ZONE_PADDING,会增加 32 字节的填充空间,使得每个zone的大小达到 128 字节,避免跨越缓存行。 - 如果多个
zone的数据排列在内存中,它们会分别占用独立的缓存行,像这样:
| zone_0 (128 bytes) | zone_1 (128 bytes) | zone_2 (128 bytes) | ...
由于 struct zone 结构经常被访问到, 因此这个数据结构要求以 L1 Cache 对齐. 另外, 这里的
ZONE_PADDING( ) 让 zone->lock 和 zone_lru_lock 这两个很热门的锁可以分布在不同的 Cahe Line 中.
一个内存 node 节点最多也就几个 zone, 因此 zone 数据结构不需要像 struct page 一样关心数据结构的
小, 因此这里的 ZONE_PADDING( ) 可以理解为用空间换取时间(性能). 在内存管理开发过程中, 内核开发者
渐发现有一些自选锁竞争会非常厉害, 很难获取. 像 zone->lock 和 zone->lru_lock 这两个锁有时需要同
获取锁. 因此保证他们使用不同的 Cache Line 是内核常用的一种优化技巧
那么数据保存在CPU高速缓存中, 那么会处理得更快速. 高速缓冲分为行, 每一行负责不同的内存区. 内核使用ZONE_PADDING宏生成”填充”字段添加到结构中, 以确保每个自旋锁处于自身的缓存行中
内核还用了 ____cacheline_internodealigned_in_smp,来实现最优的高速缓存行对其方式。
1.2.2 unsigned long _watermark[NR_WMARK]
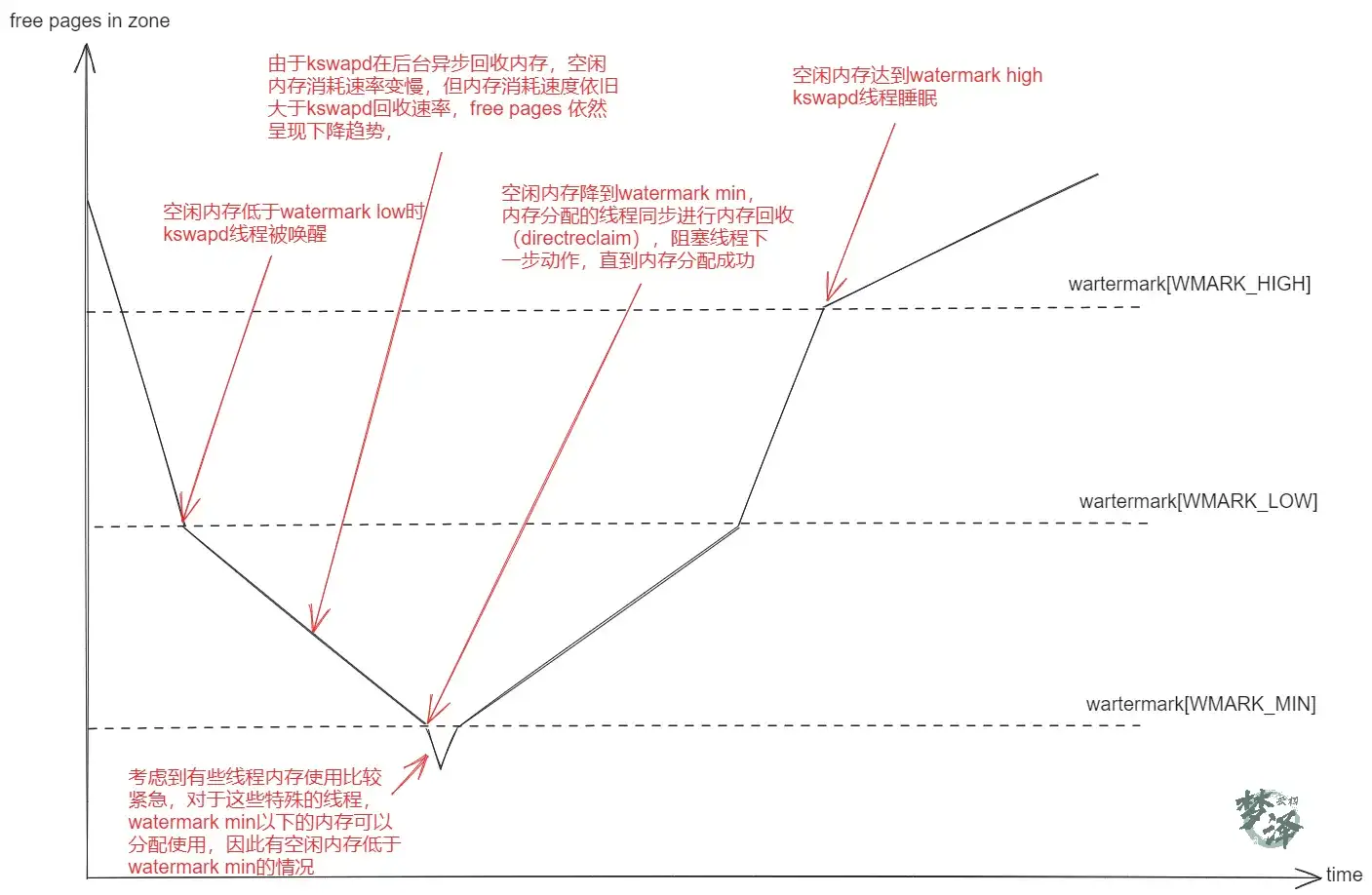
每个zone都有三个水线标准,如下enum定义,分别叫做 WMARK_MIN,WMARK_LOW,WMARK_HIGH,借助水线值与zone的free pages对比,可以知道当前zone的内存压力有多大。这三个值在系统启动阶段memory init时会计算得出,首先是通过 init_per_zone_wmark_min函数计算出 min_free_kbytes,后面根据这个值,计算出这三个水线标准值。
当系统中可用内存很少的时候,系统进程kswapd被唤醒, 开始回收释放page, 水印这些参数(WMARK_MIN, WMARK_LOW, WMARK_HIGH)影响着这个代码的行为。
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
// 若空闲内存页数目小于该值,页回收工作的压力就比较大
#define min_wmark_pages(z) (z->_watermark[WMARK_MIN] + z->watermark_boost)
// 若内存空闲页数目低于该值,buddy system在进行内存分配的同时,后台同步启动内存异步回收的内核线程kswapd去回收内存
#define low_wmark_pages(z) (z->_watermark[WMARK_LOW] + z->watermark_boost)
// 若空闲页数目多于high_wmark_pages,当内存回收后,free pages到达这个水线,kswapd线程将进入睡眠状态,不再通过kswapd进行内存回收
#define high_wmark_pages(z) (z->_watermark[WMARK_HIGH] + z->watermark_boost)
| 标准 | 描述 |
|---|---|
| watermark[WMARK_MIN] | 当空闲页面的数量达到page_min所标定的数量的时候, 说明页面数非常紧张, 分配页面的动作和kswapd线程同步运行.WMARK_MIN所表示的page的数量值,是在内存初始化的过程中调用free_area_init_core中计算的。这个数值是根据zone中的page的数量除以一个>1的系数来确定的。通常是这样初始化的ZoneSizeInPages/12 |
| watermark[WMARK_LOW] | 当空闲页面的数量达到WMARK_LOW所标定的数量的时候,说明页面刚开始紧张, 则kswapd线程将被唤醒,并开始释放回收页面 |
| watermark[WMARK_HIGH] | 当空闲页面的数量达到page_high所标定的数量的时候, 说明内存页面数充足, 不需要回收, kswapd线程将重新休眠,通常这个数值是page_min的3倍 |
如果空闲页多于 pages_high = watermark[WMARK_HIGH], 则说明内存页面充足, 内存域的状态是理想的
如果空闲页的数目低于 pages_low = watermark[WMARK_LOW], 则说明内存页面开始紧张, 内核开始将页患处到硬盘.
如果空闲页的数目低于 pages_min = watermark[WMARK_MIN], 则内存页面非常紧张, 页回收工作的压力就比较大
我们可以通过 cat /proc/vmstat,其中的"pageoutrun"和"allocstall_(dma/dma32/normal/movable)",分别查看kswapd和各个zone的direct reclaim启动的次数。
1.2.3 内存域统计信息 vm_stat
内存域struct zone的vm_stat维护了大量有关该内存域的统计信息. 由于其中维护的大部分信息曲面没有多大意义:vm_stat的统计信息由 enum zone_stat_item 枚举变量标识:
enum zone_stat_item {
/* First 128 byte cacheline (assuming 64 bit words) */
NR_FREE_PAGES,
NR_ZONE_LRU_BASE, /* Used only for compaction and reclaim retry */
NR_ZONE_INACTIVE_ANON = NR_ZONE_LRU_BASE,
NR_ZONE_ACTIVE_ANON,
NR_ZONE_INACTIVE_FILE,
NR_ZONE_ACTIVE_FILE,
NR_ZONE_UNEVICTABLE,
NR_ZONE_WRITE_PENDING, /* Count of dirty, writeback and unstable pages */
NR_MLOCK, /* mlock()ed pages found and moved off LRU */
/* Second 128 byte cacheline */
NR_BOUNCE,
#if IS_ENABLED(CONFIG_ZSMALLOC)
NR_ZSPAGES, /* allocated in zsmalloc */
#endif
NR_FREE_CMA_PAGES,
NR_VM_ZONE_STAT_ITEMS };
内核提供了很多方式来获取当前内存域的状态信息, 这些函数大多定义在:include/linux/vmstat.h
1.2.4 冷热页与Per-CPU上的页面高速缓存
内核经常请求和释放单个页框. 为了提升性能, 每个内存管理区都定义了一个每CPU(Per-CPU)的页面高速缓存. 所有”每CPU高速缓存”包含一些预先分配的页框, 他们被定义满足本地CPU发出的单一内存请求
struct zone 的 per_cpu_pageset 成员用于实现冷热分配器(hot-n-cold allocator)
struct per_cpu_pages __percpu *per_cpu_pageset; ///用于维护每个CPU的单页面,申请单个页面时,减少自旋锁的竞争
内核说页面是热的, 意味着页面已经加载到CPU的高速缓存, 与在内存中的页相比, 其数据访问速度更快. 相反, 冷页则不再高速缓存中. 在多处理器系统上每个CPU都有一个或者多个告诉缓存. 各个CPU的管理必须是独立的
per_cpu_pageset是一个指针, 其容量与系统能够容纳的 CPU 的数目的最大值相同,数组元素类型为 per_cpu_pages:
struct per_cpu_pages {
///链表中页面的个数
int count; /* number of pages in the list */
///高水位
int high; /* high watermark, emptying needed */
///每一次回收到伙伴系统的页面数量
int batch; /* chunk size for buddy add/remove */
short free_factor; /* batch scaling factor during free */
#ifdef CONFIG_NUMA
short expire; /* When 0, remote pagesets are drained */
#endif
/* Lists of pages, one per migrate type stored on the pcp-lists */
//页面链表,有多个迁移类型
struct list_head lists[NR_PCP_LISTS];
};
| 字段 | 描述 |
|---|---|
| count | 记录了与该列表相关的页的数目 |
| high | 是一个水印. 如果count的值超过了high, 则表明列表中的页太多了 |
| batch | 如果可能, CPU的高速缓存不是用单个页来填充的, 而是欧诺个多个页组成的块, batch作为每次添加/删除页时多个页组成的块大小的一个参考值 |
| list | 一个双链表, 保存了当前CPU的冷页或热页, 可使用内核的标准方法处理 |
struct per_cpu_pages则维护了链表中目前已有的一系列页面, 高极值和低极值决定了何时填充该集合或者释放一批页面, 变量决定了一个块中应该分配多少个页面, 并最后决定在页面前的实际链表中分配多少各页面
1.2.5 zone_start_pfn
struct zone中通过 zone_start_pfn 成员标记了内存管理区的页面地址.
然后内核也通过一些全局变量标记了物理内存所在页面的偏移, 这些变量定义在:
unsigned long max_low_pfn;
unsigned long min_low_pfn;
unsigned long max_pfn;
unsigned long long max_possible_pfn;
| 变量 | 描述 |
|---|---|
| max_low_pfn | x86中,max_low_pfn变量是由find_max_low_pfn函数计算并且初始化的,它被初始化成ZONE_NORMAL的最后一个page的位置。这个位置是kernel直接访问的物理内存, 也是关系到kernel/userspace通过“PAGE_OFFSET宏”把线性地址内存空间分开的内存地址位置 |
| min_low_pfn | 系统可用的第一个pfn是min_low_pfn变量, 开始与_end标号的后面, 也就是kernel结束的地方.在文件mm/bootmem.c中对这个变量作初始化 |
| max_pfn | 系统可用的最后一个PFN是max_pfn变量, 这个变量的初始化完全依赖与硬件的体系结构. |
1.2.6 pglist_data
关于这个成员,会在下一篇中着重介绍!这里简单介绍一下
typedef struct pglist_data {
/*
* node_zones contains just the zones for THIS node. Not all of the
* zones may be populated, but it is the full list. It is referenced by
* this node's node_zonelists as well as other node's node_zonelists.
*/
///本节点的所有zone
struct zone node_zones[MAX_NR_ZONES];
/*
* node_zonelists contains references to all zones in all nodes.
* Generally the first zones will be references to this node's
* node_zones.
*/
///本node的备选节点,及内存区域列表
///MAX_ZONELISTS=2,
///ZONELIST_FALLBACK: 指向本地zone;
//ZONELIST_NOFALLBACK: 指向远端的内存节点zone,用于numa系统
struct zonelist node_zonelists[MAX_ZONELISTS];
///本node, zone的个数
int nr_zones; /* number of populated zones in this node */
#ifdef CONFIG_FLATMEM /* means !SPARSEMEM */
///struct page数组的指针
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
#if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT)
/*
* Must be held any time you expect node_start_pfn,
* node_present_pages, node_spanned_pages or nr_zones to stay constant.
* Also synchronizes pgdat->first_deferred_pfn during deferred page
* init.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG
* or CONFIG_DEFERRED_STRUCT_PAGE_INIT.
*
* Nests above zone->lock and zone->span_seqlock
*/
spinlock_t node_size_lock;
#endif
///本node中内存的起始页帧号
unsigned long node_start_pfn;
///本node中所有可用物理页page数量
unsigned long node_present_pages; /* total number of physical pages */
///本node中所有物理页page数量,包括空洞页
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
///负责回收该node内存节点的内核线程,每个node对应一个内核线程kswapd
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
int kswapd_order;
enum zone_type kswapd_highest_zoneidx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_highest_zoneidx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
bool proactive_compact_trigger;
#endif
/*
* This is a per-node reserve of pages that are not available
* to userspace allocations.
*/
unsigned long totalreserve_pages;
#ifdef CONFIG_NUMA
/*
* node reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
ZONE_PADDING(_pad1_)
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
struct deferred_split deferred_split_queue;
#endif
/* Fields commonly accessed by the page reclaim scanner */
/*
* NOTE: THIS IS UNUSED IF MEMCG IS ENABLED.
*
* Use mem_cgroup_lruvec() to look up lruvecs.
*/
struct lruvec __lruvec; ///lru链表向量(包括所有,5种lru链表)
unsigned long flags;
ZONE_PADDING(_pad2_)
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;
该数据结构是内存管理的重要数据结构,用以管理一个 node 中所有内存。对于UMA 架构来说,只有一个节点,也就是全局变量 contig_page_data;
- node_zones:是个zone 数组,记录该node 中所有的zone,详细的zone 的数据结构看第 2 节;
- node_zonelist,备用区域列表,对于UMA 架构来说,zone list是所有zone 的fallback zone 组成的list,详细看第 3 节;
- nr_zones:记录当前node 的zone 数量;例如当有DMA32 和NORMAL时,nr_zones 为2;
- node_start_pfn:记录当前node 的物理起始 PFN;
- node_present_pages:记录node 的实际管理的物理pages,去除了 hole;
- node_spanned_pages:记录node 的总的物理pages,包括hole pages;
- node_id:当前node 的编号,对于UMA 来说只有一个node,此node_id 为0,使用中都是简写为nid;
- kswapd_wait:每个pg_data_t 数据结构都会有一个 kswapd 等待队列,在freee_area_init_core() 函数中初始化,详细看 6.6.1 节;
- kswapd:记录当前node 对应的 kswapd 线程,介绍kswapd 的时候在另行说明
- kswapd_order、 kswpad_classzone_idx、 kswpad_failures 等都是在kswapd 中存放的状态,,这里只需要知道分别对应kswapd 扫描的page order、zone的idx 以及运行状态;
- totalreserve_pages:该node 的reserved pages;
- lru_lock:内存管理的自旋锁;
- __lruvec:针对该node 的LRU 向量,详细看struct lruvec,用以管理LRU的 5 个list;
- vm_stat:用以记录该node 的 vm 状态,注意数组个数为 NR_VM_NODE_STAT_ITEMS,与zone 中的 vmstat 不一样
2. 数据结构总结
2.1 关系结构图
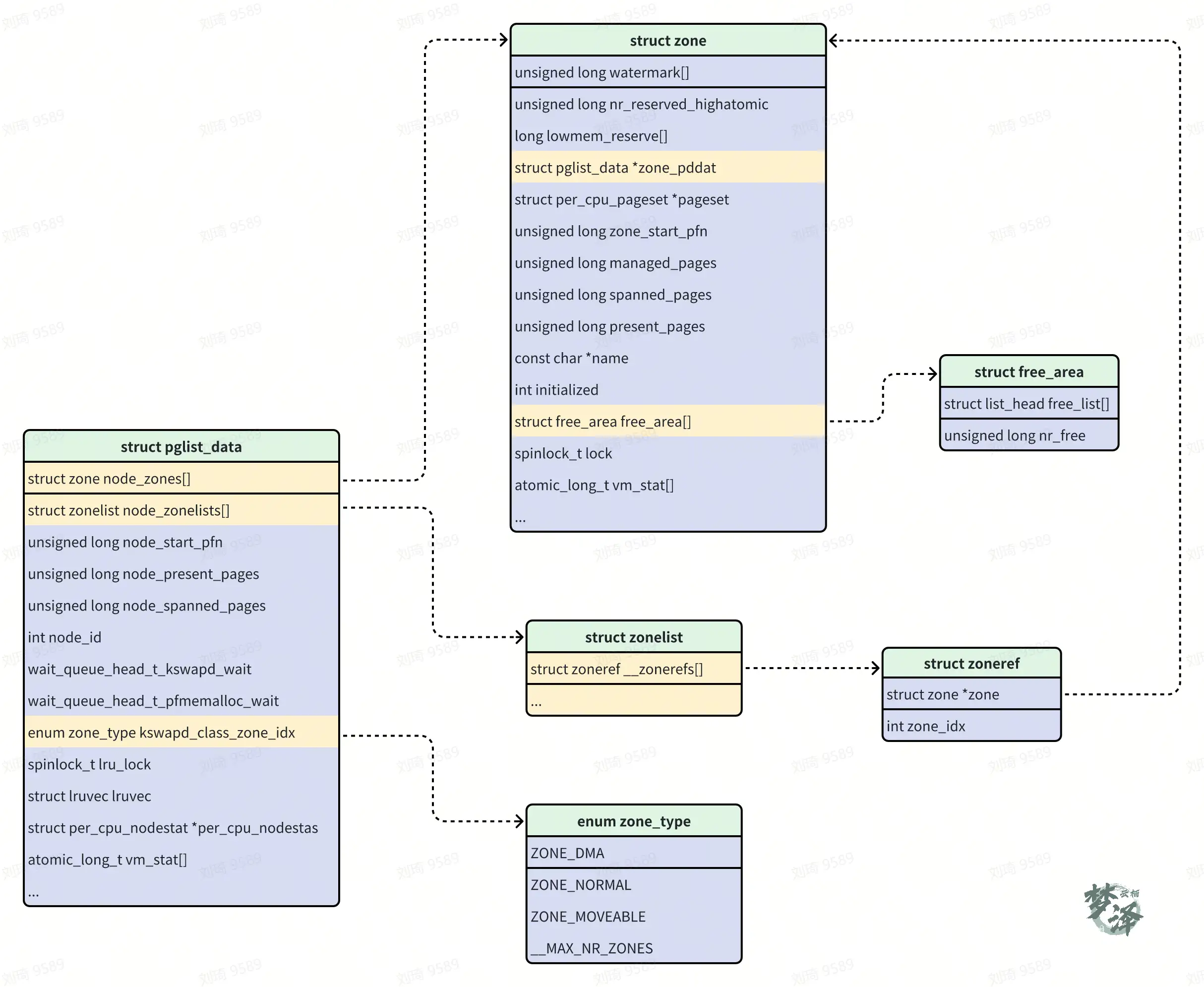
- 在NUMA 架构下,每个node 对应一个struct pglist_data;
- 在UMA 架构下,只有使用一个node,对应唯一的struct pglist_data,例如在AMR64 UMA 中使用的全局变量 struct pglist_data contig_page_data;
include/linux/mmzone.h
#ifndef CONFIG_NEED_MULTIPLE_NODES
extern struct pglist_data contig_page_data;
#define NODE_DATA(nid) (&contig_page_data)
#define NODE_MEM_MAP(nid) mem_map
mm/memblock.c
#ifndef CONFIG_NEED_MULTIPLE_NODES
struct pglist_data __refdata contig_page_data;
EXPORT_SYMBOL(contig_page_data);
#endif
2.2 架构层次图
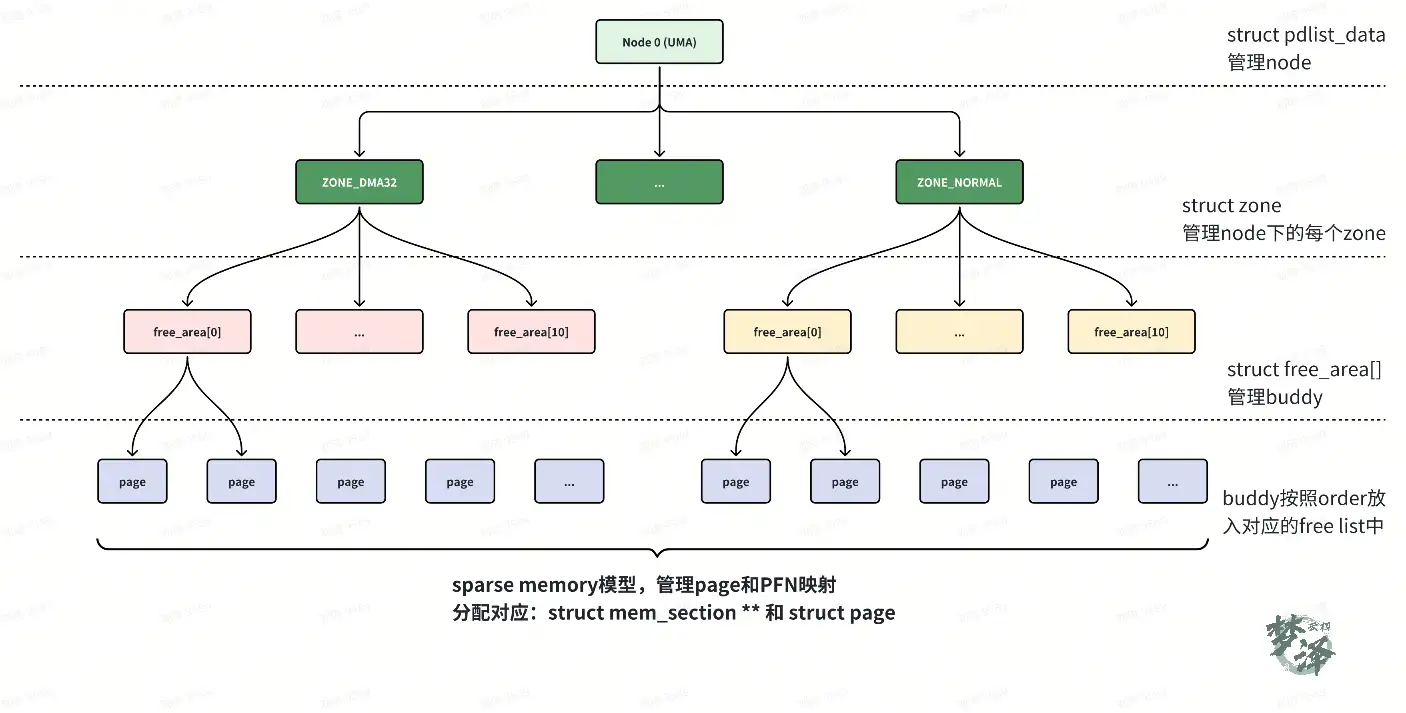
- 每个zone 中都会有个struct free_area[MAX_ORDER] 的数组,在Linux 内核中,MAX_ORDER 受 CONFIG_FORCE_MAX_ZONEORDER 控制,当config 没有定义时,默认为 11,也就是buddy 系统中的 free pages 是按照order 0~10,即 2^0 个page 至 2^10 个page 存放在free_area 数组中;其他的pages 存放在LRU 链表中;
- 另外,所有的page 在zone 初始化的时候分配好,包括page对应的memmap pages。
- memmap pages 区域存放的是zone 管理的pages的属性;
- 当pages初始化完成后,组成的page 数组就与SPARSEMEM 初始化中的mem_section 对应