
进程调度程序是确保进程能有效工作的一个内核子系统,它决定哪个TASK_RUNNING的进程能够投入运行,可以运行多长时间。
2.6引入了一个重要的特性,就是内核抢占。这意味着多个处于特权模式(privileged mode)的执行流(即处于内核态的进程)可以任意的交叉执行,因此进程调度适用于很多内核态中的代码。
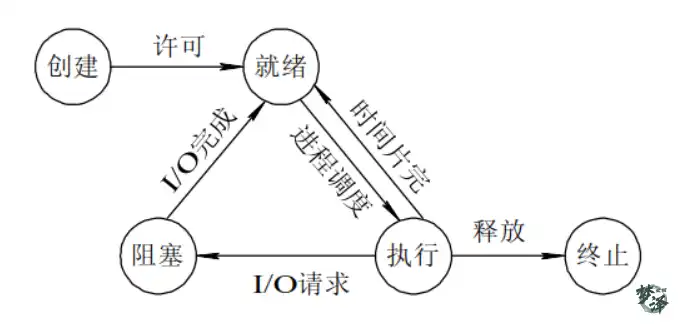
进程和线程的五种状态(生命周期)
进程和线程在创建到销毁的过程中,都会经历五种状态的转换。具体如下:
进程
创建:进程在创建时需要申请一个空白PCB,向其中填写控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调度运行,把此时进程所处状态称为创建状态。
就绪:进程已经准备好,已分配到所需资源,只要分配到CPU就能够立即运行。
执行:进程处于就绪状态被调度后,进程进入执行状态。
阻塞:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。在满足请求时进入就绪状态等待系统调用
终止:进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行
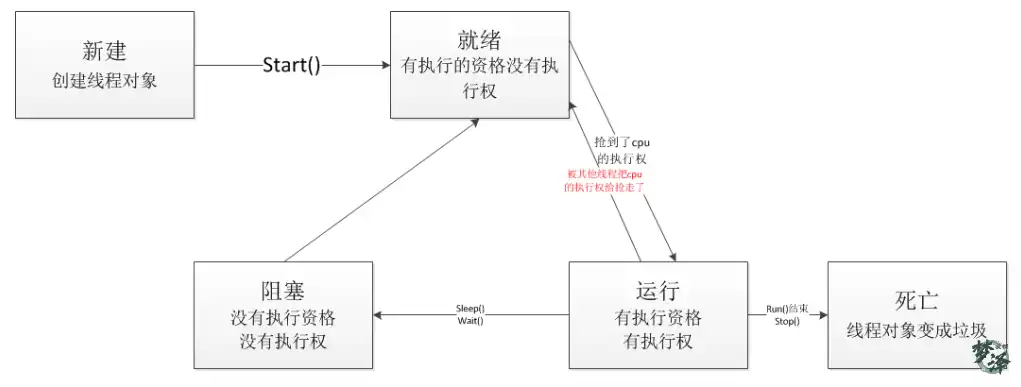
线程
新建:创建线程对象
就绪:线程对象已经启动了,但是还没有获取到cpu的执行权
运行:获取到了cpu的执行权
阻塞:没有cpu的执行权,回到就绪
死亡:代码运行完毕,线程消亡
多任务
多任务操作系统能够同时执行多个进程,在单处理器系统中,同时运行只是一种幻觉,在多处理器系统中则真实的发生着。多任务操作系统可以让多个进程处于阻塞或者睡眠状态,这些进程不会真正的运行,直到等待的条件(例如键盘输入、网络数据到达、定时器)就绪。
多任务操作系统可以分为两类:
非抢占式多任务(Cooperative Multitasking):除非进程自己主动停止执行,否则它会一直占据CPU。进程主动挂起自己的操作称为让步(Yielding)。现在很少OS使用此模式
抢占式多任务(Preemptive Multitasking):Unix变体和许多现代OS采取的方式,在此模式下,调度程序确定何时停止一个进程的运行,以便其它进程获得执行机会,这个强制挂起正在执行进程的动作叫做抢占。进程在被抢占之前能够运行的时间是预先设定的,称为时间片(timeslice)。
进程相关的数据结构
Linux 内核涉及进程和程序的所有算法都围绕一个名为 task_struct 的数据结构(称为进程描述符(process descriptor))建立,该结构定义在 include/sched.h 中。
内核把进程的列表存放在叫做任务队列(tasklist)的双向循环链表中。
鉴于这个结构体的复杂,本文分成多个部分来分析它。
进程状态
进程状态由结构体中的如下代码定义:
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
其中state的可取的值如下:
/*
* Task state bitmask. NOTE! These bits are also
* encoded in fs/proc/array.c: get_task_state().
*
* We have two separate sets of flags: task->state
* is about runnability, while task->exit_state are
* about the task exiting. Confusing, but this way
* modifying one set can't modify the other one by
* mistake.
*/
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_DEAD 16
#define EXIT_ZOMBIE 32
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_STATE_MAX 1024
················
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
其中,有五个互斥状态:
TASK_RUNNING。表示进程要么正在执行,要么正要准备执行(已经就绪),正在等待cpu时间片的调度。
TASK_INTERRUPTIBLE。进程因为等待一些条件而被挂起(阻塞)而所处的状态。这些条件主要包括:硬中断、资源、一些信号……,一旦等待的条件成立,进程就会从该状态(阻塞)迅速转化成为就绪状态TASK_RUNNING。
TASK_UNINTERRUPTIBLE。意义与TASK_INTERRUPTIBLE类似,除了不能通过接受一个信号来唤醒以外,对于处于TASK_UNINTERRUPIBLE状态的进程,哪怕我们传递一个信号或者有一个外部中断都不能唤醒他们。只有它所等待的资源可用的时候,他才会被唤醒。这个标志很少用,但是并不代表没有任何用处,其实他的作用非常大,特别是对于驱动刺探相关的硬件过程很重要,这个刺探过程不能被一些其他的东西给中断,否则就会让进程进入不可预测的状态。
TASK_STOPPED。进程被停止执行,当进程接收到SIGSTOP、SIGTTIN、SIGTSTP或者SIGTTOU信号之后就会进入该状态。
TASK_TRACED。表示进程被debugger等进程监视,进程执行被调试程序所停止,当一个进程被另外的进程所监视,每一个信号都会让进程进入该状态。
两个终止状态:
EXIT_ZOMBIE。进程的执行被终止,但是其父进程还没有使用wait()等系统调用来获知它的终止信息,此时进程成为僵尸进程。
EXIT_DEAD。进程的最终状态。
以及新增的睡眠状态:
TASK_KILLABLE。当进程处于这种可以终止的新睡眠状态中,它的运行原理类似于 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号。
进程描述符pid和tgid
Unix系统通过pid来标识进程,linux把不同的pid与系统中每个进程或轻量级线程关联,而unix程序员希望同一组线程具有共同的pid,遵照这个标准linux引入线程组的概念。一个线程组所有线程与领头线程具有相同的pid,存入tgid字段,getpid()返回当前进程的tgid值而不是pid的值。
在Linux系统中,一个线程组中的所有线程使用和该线程组的领头线程(该组中的第一个轻量级进程)相同的PID,并被存放在tgid成员中。只有线程组的领头线程的pid成员才会被设置为与tgid相同的值。注意,getpid()系统调用返回的是当前进程的tgid值而不是pid值。
注意系统中pid的范围是有限的,这也是为什么尽管僵尸进程几乎不占用资源,我们依然要将其回收。因为僵尸进程占用了pid空间,僵尸进程过多会导致没有pid可以分配给新进程。
进程内核栈
sched.h中的以下代码定义进程内核栈:
void *stack;
对于每个进程,linux都把两个不同的数据结构紧凑的存放在一个单独为进程分配的内存区域中,一个是内核态的进程堆栈,另一个是线程描述符thread_info。这两个数据结构被定义在一个联合体中,由alloc_thread_info_node分配内存空间。
进程标记
进程标记反映进程状态的信息,但不是运行状态,用于内核识别进程当前的状态,以备下一步操作。
unsigned int flags; /* per process flags, defined below */flags可能的取值如下所示:
/*
* Per process flags
*/
#define PF_EXITING 0x00000004 /* getting shut down */
#define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */
#define PF_VCPU 0x00000010 /* I'm a virtual CPU */
#define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */
#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
#define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */
#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
#define PF_DUMPCORE 0x00000200 /* dumped core */
#define PF_SIGNALED 0x00000400 /* killed by a signal */
#define PF_MEMALLOC 0x00000800 /* Allocating memory */
#define PF_NPROC_EXCEEDED 0x00001000 /* set_user noticed that RLIMIT_NPROC was exceeded */
#define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */
#define PF_USED_ASYNC 0x00004000 /* used async_schedule*(), used by module init */
#define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */
#define PF_FROZEN 0x00010000 /* frozen for system suspend */
#define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */
#define PF_KSWAPD 0x00040000 /* I am kswapd */
#define PF_MEMALLOC_NOIO 0x00080000 /* Allocating memory without IO involved */
#define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */
#define PF_KTHREAD 0x00200000 /* I am a kernel thread */
#define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */
#define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */
#define PF_NO_SETAFFINITY 0x04000000 /* Userland is not allowed to meddle with cpus_allowed */
#define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */
#define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */
#define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */
#define PF_SUSPEND_TASK 0x80000000 /* this thread called freeze_processes and should not be frozen */进程的父子、兄弟关系
进程的父子兄弟关系存储在以下代码:
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
这些字段具体描述如下:
real_parent。指向其父进程,如果创建它的父进程不再存在,则指向PID为1的init进程。
parent。指向其父进程,当它终止时,必须向它的父进程发送信号。它的值通常与real_parent相同。
children。表示链表的头部,链表中的所有元素都是它的子进程。
sibling。用于把当前进程插入到兄弟链表中。
group_leader。指向其所在进程组的领头进程。
task_struct总结
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
///Linux5.0中thread_info从内核栈移到了task_struct
///ARM64的SP_EL0用来存放当前进程的task_struct地址
struct thread_info thread_info;
#endif
/*
* 进程存续期间的状态:
* 1.TASK_RUNNING:就绪态和运行态都是TASK_RUNNING
* 就绪态:唯一等待的资源是CPU,并拿到CPU可以立即运行,放在运行队列中rq;
* 运行态:正在运行的当前进程;
*
* 2.TASK_INTERRUPTIBLE:浅度睡眠,可中断的等待状态;
* 睡眠等待某事件或资源,当得到满足时,可以被信号唤醒,
* 进程状态变为TASK_RUNNING, 加入运行队列rq; *
* 3.TASK_UNINTERRUPTIBLE:深度睡眠,不可中断的等待状态;
* 该状态进程等待某个事件或资源,等待过程不能被打断,不响应任何外部信号;
* 比如,从磁盘读入可执行代码过程中,又有代码需要从磁盘读取,会造成嵌套睡眠;
*
* 4.TASK_STOPPED:暂停状态
* 进程暂时停止运行,收到SIGSTOP,SIGTSTP,SIGTTIN,SIGTTOU信号处于该状态;
*
* 5.TASK_ZOMBIE:僵尸态
* 子进程死亡后,变成僵尸,mm,fs等资源都已释放,只剩task_struct结构体躯壳还没被父进程清理,
* 父进程通过wait_pid获取子进程僵尸状态,wait结束,僵尸所有资源被释放;
*/
unsigned int __state;
#ifdef CONFIG_PREEMPT_RT
/* saved state for "spinlock sleepers" */
unsigned int saved_state;
#endif
/*
* This begins the randomizable portion of task_struct. Only
* scheduling-critical items should be added above here.
*/
randomized_struct_fields_start
///指向进程的内核栈
void *stack;
///进程描述符使用计数
refcount_t usage;
/*
* flags:进程当前的状态标志,比如
* #define PF_SIGNALED 0x00000400 // Killed by a signal
*/
/* Per task flags (PF_*), defined further below: */
unsigned int flags;
/*
* ptrace系统调用设置,0表示不需要被跟踪
*/
unsigned int ptrace;
#ifdef CONFIG_SMP
///进程是否正处于运行running状态
int on_cpu;
struct __call_single_node wake_entry;
#ifdef CONFIG_THREAD_INFO_IN_TASK
/* Current CPU: */
///当前进程在哪个CPU运行
unsigned int cpu;
#endif
unsigned int wakee_flips;
unsigned long wakee_flip_decay_ts;
///上一次唤醒的是哪个进程
struct task_struct *last_wakee;
/*
* recent_used_cpu is initially set as the last CPU used by a task
* that wakes affine another task. Waker/wakee relationships can
* push tasks around a CPU where each wakeup moves to the next one.
* Tracking a recently used CPU allows a quick search for a recently
* used CPU that may be idle.
*/
int recent_used_cpu;
///进程上一次运行在哪个cpu
int wake_cpu;
#endif
/*
* on_rq:进程状态
* TASK_ON_RQ_QUEUED:表示进程正在就绪队列中;
* TASK_ON_RQ_MIGRATING: 处于迁移过程中的进程,可能不再就绪队列中
*/
int on_rq;
/*
* prio:调度类考虑的动态优先级,有些情况下可以暂时提高优先级,比如实时互斥锁;
* static_prio:进程静态优先级,进程启动时分配,不会随时间改变,可以用nice(),sched_setscheduler()修改;
* normal_prio:基于static_prio和调度策略计算的优先级,创建时继承父进程normal_prio,
* 对普通进程,normal_prio=static_prio,
* 对实时进程,会根据rt_priority重新计算normal_prio。
* rt_priority:实时进程优先级
* */
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
/*
* 调度类:
* linux实现调度类有:stop_sched_class,dl_sched_class,rt_sched_class,fair_sched_class,idle_sched_class;
* 不同的调度类,对应不同的调度操作方法
*/
const struct sched_class *sched_class;
/*
* 普通进程调度实体:
* se不仅用于单个进程调度,还用于“组调度”
*/
struct sched_entity se;
///rt进程调度实体
struct sched_rt_entity rt;
///deadline进程调度实体
struct sched_dl_entity dl;
#ifdef CONFIG_SCHED_CORE
struct rb_node core_node;
unsigned long core_cookie;
unsigned int core_occupation;
#endif
#ifdef CONFIG_CGROUP_SCHED
///cgroup cpu资源统计对象
struct task_group *sched_task_group;
#endif
#ifdef CONFIG_UCLAMP_TASK
/*
* Clamp values requested for a scheduling entity.
* Must be updated with task_rq_lock() held.
*/
struct uclamp_se uclamp_req[UCLAMP_CNT];
/*
* Effective clamp values used for a scheduling entity.
* Must be updated with task_rq_lock() held.
*/
struct uclamp_se uclamp[UCLAMP_CNT];
#endif
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* List of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
#ifdef CONFIG_BLK_DEV_IO_TRACE
///blktrace,针对Linux中块设备I/O层的跟踪工具
unsigned int btrace_seq;
#endif
/*
* policy:进程的调度策略,目前主要有
* #define SCHED_NORMAL 0 //用于普通进程,cfs调度
* #define SCHED_FIFO 1 //实时调度类, 霸占型,高优先级执行完,才会执行低优先级
* #define SCHED_RR 2 //实时调度类, 不同优先级同SCHED_FIFO, 同优先级,时间片轮转
* #define SCHED_BATCH 3 //非交互CPU密集型,通过cfs实现,不抢占cfs的其他进程,使用场景:不希望该进程影响系统交互性
* #define SCHED_IDLE 5 //cfs处理,相对权重最小
* #define SCHED_DEADLINE 6 //DL调度器思想:谁更紧急,谁先跑
**/
unsigned int policy;
///进程允许运行的cpu个数
int nr_cpus_allowed;
///进程允许运行cpu位图
const cpumask_t *cpus_ptr;
cpumask_t *user_cpus_ptr;
cpumask_t cpus_mask;
void *migration_pending;
#ifdef CONFIG_SMP
unsigned short migration_disabled;
#endif
unsigned short migration_flags;
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
union rcu_special rcu_read_unlock_special;
struct list_head rcu_node_entry;
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TASKS_RCU
unsigned long rcu_tasks_nvcsw;
u8 rcu_tasks_holdout;
u8 rcu_tasks_idx;
int rcu_tasks_idle_cpu;
struct list_head rcu_tasks_holdout_list;
#endif /* #ifdef CONFIG_TASKS_RCU */
///RCU同步原语
#ifdef CONFIG_TASKS_TRACE_RCU
int trc_reader_nesting;
int trc_ipi_to_cpu;
union rcu_special trc_reader_special;
bool trc_reader_checked;
struct list_head trc_holdout_list;
#endif /* #ifdef CONFIG_TASKS_TRACE_RCU */
/*
* 用于调度器统计进程的运行信息
* */
struct sched_info sched_info;
/*
* 系统中所有进程通过tasks组成一个链表,双向环形链表;
* 链表头是init_task, 即0号进程
* next_task(): 遍历下一个进程
* next_thread(): 遍历线程组的下一个线程
*/
struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
struct rb_node pushable_dl_tasks;
#endif
/*
* mm:指向进程的内存描述符,内核线程为NULL
* active_mm:指向进程运行时所使用的内存描述符
*
* 普通进程:两个指针相同;
* 内核线程:mm==NULL,当线程运行时,active_mm被初始化为前一个运行进程的active_mm值?
* */
struct mm_struct *mm;
struct mm_struct *active_mm;
/* Per-thread vma caching: */
struct vmacache vmacache;
#ifdef SPLIT_RSS_COUNTING
struct task_rss_stat rss_stat;
#endif
/*
* 进程退出状态码
* exit_state:
* 判断标志:
* exit_code: 进程的终止代号,_exit()/exit_group()参数,或者内核提供的错误代号
* exit_signal:置-1表示属于某个线程组一员,当线程组最后一个成员终止时,产生一个信号,通知线程组leader进程的父进程
*/
int exit_state;
int exit_code;
int exit_signal;
///父进程终止时,发送的信号
/* The signal sent when the parent dies: */
int pdeath_signal;
/* JOBCTL_*, siglock protected: */
unsigned long jobctl;
/* Used for emulating ABI behavior of previous Linux versions: */
unsigned int personality;
/* Scheduler bits, serialized by scheduler locks: */
unsigned sched_reset_on_fork:1;
unsigned sched_contributes_to_load:1;
unsigned sched_migrated:1;
#ifdef CONFIG_PSI
unsigned sched_psi_wake_requeue:1;
#endif
/* Force alignment to the next boundary: */
unsigned :0;
/* Unserialized, strictly 'current' */
/*
* This field must not be in the scheduler word above due to wakelist
* queueing no longer being serialized by p->on_cpu. However:
*
* p->XXX = X; ttwu()
* schedule() if (p->on_rq && ..) // false
* smp_mb__after_spinlock(); if (smp_load_acquire(&p->on_cpu) && //true
* deactivate_task() ttwu_queue_wakelist())
* p->on_rq = 0; p->sched_remote_wakeup = Y;
*
* guarantees all stores of 'current' are visible before
* ->sched_remote_wakeup gets used, so it can be in this word.
*/
unsigned sched_remote_wakeup:1;
/* Bit to tell LSMs we're in execve(): */
///通知LSM是否被do_execve()调用
unsigned in_execve:1;
///判断是否进行iowait计数
unsigned in_iowait:1;
#ifndef TIF_RESTORE_SIGMASK
unsigned restore_sigmask:1;
#endif
#ifdef CONFIG_MEMCG
unsigned in_user_fault:1;
#endif
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif
#ifdef CONFIG_CGROUPS
/* disallow userland-initiated cgroup migration */
unsigned no_cgroup_migration:1;
/* task is frozen/stopped (used by the cgroup freezer) */
unsigned frozen:1;
#endif
#ifdef CONFIG_BLK_CGROUP
unsigned use_memdelay:1;
#endif
#ifdef CONFIG_PSI
/* Stalled due to lack of memory */
unsigned in_memstall:1;
#endif
#ifdef CONFIG_PAGE_OWNER
/* Used by page_owner=on to detect recursion in page tracking. */
unsigned in_page_owner:1;
#endif
#ifdef CONFIG_EVENTFD
/* Recursion prevention for eventfd_signal() */
unsigned in_eventfd_signal:1;
#endif
unsigned long atomic_flags; /* Flags requiring atomic access. */
struct restart_block restart_block;
/*
* pid:线程id,每个线程都不同
* tgid:线程组id, 同一个进程中所有线程相同
*
* 一个线程组中,所有线程的tgid相同,pid都不相同,只有线程组长(该组第一个线程)的pid==tgid
* getpid():返回TGID
* gettid():返回PID
*/
pid_t pid;
pid_t tgid;
///防止内核栈溢出
#ifdef CONFIG_STACKPROTECTOR
/* Canary value for the -fstack-protector GCC feature: */
unsigned long stack_canary;
#endif
/*
* Pointers to the (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
/*
* real_parent: 指向父进程
* parent: 指向父进程,进程终止时,向父进程发送信号.通常parent==real_parent
* children: 链表头,所有子进程构成的链表
* sibling: 把当前进程插入到兄弟链表中
* group_leader: 指向其所在进程组的leader进程
* */
/* Real parent process: */
struct task_struct __rcu *real_parent;
/* Recipient of SIGCHLD, wait4() reports: */
struct task_struct __rcu *parent;
/*
* Children/sibling form the list of natural children:
*/
struct list_head children;
struct list_head sibling;
struct task_struct *group_leader;
/*
* 'ptraced' is the list of tasks this task is using ptrace() on.
*
* This includes both natural children and PTRACE_ATTACH targets.
* 'ptrace_entry' is this task's link on the p->parent->ptraced list.
*/
struct list_head ptraced;
struct list_head ptrace_entry;
/* PID/PID hash table linkage. */
///进程pid哈希表,可以用来判断线程是否alive,进程退出,这个指针为NULL
struct pid *thread_pid;
struct hlist_node pid_links[PIDTYPE_MAX];
///线程组中所有线程的链表
struct list_head thread_group;
struct list_head thread_node;
struct completion *vfork_done;
/* CLONE_CHILD_SETTID: */
int __user *set_child_tid;
/* CLONE_CHILD_CLEARTID: */
int __user *clear_child_tid;
/* PF_IO_WORKER */
void *pf_io_worker;
/*
* utime: 用于记录进程在用户态经历的节拍数
* stime: 用于记录进程在内核态经历的节拍数
* utimescaled:记录进程在用户态运行时间,以处理器的频率为刻度;
* stimescaled:记录进程在内核态运行时间,以处理器的频率为刻度;
* */
u64 utime;
u64 stime;
#ifdef CONFIG_ARCH_HAS_SCALED_CPUTIME
u64 utimescaled;
u64 stimescaled;
#endif
///以节拍计数的虚拟机运行时间guest time
u64 gtime;
///先前运行的cpu时间
struct prev_cputime prev_cputime;
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
struct vtime vtime;
#endif
#ifdef CONFIG_NO_HZ_FULL
atomic_t tick_dep_mask;
#endif
/* Context switch counts: */
unsigned long nvcsw; ///进程主动(voluntary)切换次数
unsigned long nivcsw; ///进程被动(involuntary)切换次数
/* Monotonic time in nsecs: */
u64 start_time; ///进程开始时间
/* Boot based time in nsecs: */
u64 start_boottime; ///进程开始时间,包含睡眠时间?
///缺页统计
/* MM fault and swap info: this can arguably be seen as either mm-specific or thread-specific: */
unsigned long min_flt;
unsigned long maj_flt;
/* Empty if CONFIG_POSIX_CPUTIMERS=n */
struct posix_cputimers posix_cputimers;
#ifdef CONFIG_POSIX_CPU_TIMERS_TASK_WORK
struct posix_cputimers_work posix_cputimers_work;
#endif
/* Process credentials: */
/* Tracer's credentials at attach: */
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
#ifdef CONFIG_KEYS
/* Cached requested key. */
struct key *cached_requested_key;
#endif
/*
* executable name, excluding path.
*
* - normally initialized setup_new_exec()
* - access it with [gs]et_task_comm()
* - lock it with task_lock()
*/
char comm[TASK_COMM_LEN]; ///程序名字,不包括路径
struct nameidata *nameidata;
#ifdef CONFIG_SYSVIPC
///进程通信相关
struct sysv_sem sysvsem;
struct sysv_shm sysvshm;
#endif
#ifdef CONFIG_DETECT_HUNG_TASK
///最后一次切换时的总切换次数,只有两个地方更新:1.新建进程初始化, 2.hungtask线程中;
unsigned long last_switch_count;
///最后一次切换的时间戳jiffies
unsigned long last_switch_time;
#endif
/*
* fs:表示进程与文件系统的联系,包括当前目录和根目录
* files:表示进程当前打开的文件
* */
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
#ifdef CONFIG_IO_URING
struct io_uring_task *io_uring;
#endif
/* Namespaces: */
struct nsproxy *nsproxy; ///命名空间
/*
* signal:指向进程的信号描述符
* sighand:指向进程的信号响应函数的描述符
* */
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct __rcu *sighand;
sigset_t blocked; ///被阻塞信号的掩码
sigset_t real_blocked; ///临时掩码
/* Restored if set_restore_sigmask() was used: */
sigset_t saved_sigmask;
struct sigpending pending; ///存放私有挂起信号
unsigned long sas_ss_sp; ///信号处理程序备用堆栈地址
size_t sas_ss_size; ///堆栈大小
unsigned int sas_ss_flags;
struct callback_head *task_works;
#ifdef CONFIG_AUDIT
#ifdef CONFIG_AUDITSYSCALL
struct audit_context *audit_context;
#endif
kuid_t loginuid;
unsigned int sessionid;
#endif
struct seccomp seccomp;
struct syscall_user_dispatch syscall_dispatch;
/* Thread group tracking: */
u64 parent_exec_id;
u64 self_exec_id;
/* Protection against (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, mempolicy: */
spinlock_t alloc_lock;
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
struct wake_q_node wake_q;
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task: */
struct rb_root_cached pi_waiters;
/* Updated under owner's pi_lock and rq lock */
struct task_struct *pi_top_task;
/* Deadlock detection and priority inheritance handling: */
struct rt_mutex_waiter *pi_blocked_on;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
/* Mutex deadlock detection: */
struct mutex_waiter *blocked_on;
#endif
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
int non_block_count;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
struct irqtrace_events irqtrace;
unsigned int hardirq_threaded;
u64 hardirq_chain_key;
int softirqs_enabled;
int softirq_context;
int irq_config;
#endif
#ifdef CONFIG_PREEMPT_RT
int softirq_disable_cnt;
#endif
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
int lockdep_depth;
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
#endif
#if defined(CONFIG_UBSAN) && !defined(CONFIG_UBSAN_TRAP)
unsigned int in_ubsan;
#endif
/* Journalling filesystem info: */
void *journal_info;
/* Stacked block device info: */
struct bio_list *bio_list;
#ifdef CONFIG_BLOCK
/* Stack plugging: */
struct blk_plug *plug;
#endif
/* VM state: */
struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
#ifdef CONFIG_COMPACTION
struct capture_control *capture_control;
#endif
/* Ptrace state: */
unsigned long ptrace_message;
kernel_siginfo_t *last_siginfo;
struct task_io_accounting ioac;
#ifdef CONFIG_PSI
///PSI所处状态
/* Pressure stall state */
unsigned int psi_flags;
#endif
#ifdef CONFIG_TASK_XACCT
/* Accumulated RSS usage: */
u64 acct_rss_mem1;
/* Accumulated virtual memory usage: */
u64 acct_vm_mem1;
/* stime + utime since last update: */
u64 acct_timexpd;
#endif
#ifdef CONFIG_CPUSETS
/* Protected by ->alloc_lock: */
nodemask_t mems_allowed;
/* Sequence number to catch updates: */
seqcount_spinlock_t mems_allowed_seq;
int cpuset_mem_spread_rotor;
int cpuset_slab_spread_rotor;
#endif
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock: */
///关联cgroup
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock: */
///同一个cgroup/css_set,所有进程链表
struct list_head cg_list;
#endif
#ifdef CONFIG_X86_CPU_RESCTRL
u32 closid;
u32 rmid;
#endif
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
struct mutex futex_exit_mutex;
unsigned int futex_state;
#endif
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts];
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
#ifdef CONFIG_DEBUG_PREEMPT
unsigned long preempt_disable_ip;
#endif
#ifdef CONFIG_NUMA
/* Protected by alloc_lock: */
struct mempolicy *mempolicy;
short il_prev;
short pref_node_fork;
#endif
#ifdef CONFIG_NUMA_BALANCING
int numa_scan_seq;
unsigned int numa_scan_period;
unsigned int numa_scan_period_max;
int numa_preferred_nid;
unsigned long numa_migrate_retry;
/* Migration stamp: */
u64 node_stamp;
u64 last_task_numa_placement;
u64 last_sum_exec_runtime;
struct callback_head numa_work;
/*
* This pointer is only modified for current in syscall and
* pagefault context (and for tasks being destroyed), so it can be read
* from any of the following contexts:
* - RCU read-side critical section
* - current->numa_group from everywhere
* - task's runqueue locked, task not running
*/
struct numa_group __rcu *numa_group;
/*
* numa_faults is an array split into four regions:
* faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer
* in this precise order.
*
* faults_memory: Exponential decaying average of faults on a per-node
* basis. Scheduling placement decisions are made based on these
* counts. The values remain static for the duration of a PTE scan.
* faults_cpu: Track the nodes the process was running on when a NUMA
* hinting fault was incurred.
* faults_memory_buffer and faults_cpu_buffer: Record faults per node
* during the current scan window. When the scan completes, the counts
* in faults_memory and faults_cpu decay and these values are copied.
*/
unsigned long *numa_faults;
unsigned long total_numa_faults;
/*
* numa_faults_locality tracks if faults recorded during the last
* scan window were remote/local or failed to migrate. The task scan
* period is adapted based on the locality of the faults with different
* weights depending on whether they were shared or private faults
*/
unsigned long numa_faults_locality[3];
unsigned long numa_pages_migrated;
#endif /* CONFIG_NUMA_BALANCING */
#ifdef CONFIG_RSEQ
struct rseq __user *rseq;
u32 rseq_sig;
/*
* RmW on rseq_event_mask must be performed atomically
* with respect to preemption.
*/
unsigned long rseq_event_mask;
#endif
struct tlbflush_unmap_batch tlb_ubc;
union {
refcount_t rcu_users;
struct rcu_head rcu;
};
/* Cache last used pipe for splice(): */
struct pipe_inode_info *splice_pipe;
struct page_frag task_frag;
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
unsigned int fail_nth;
#endif
/*
* When (nr_dirtied >= nr_dirtied_pause), it's time to call
* balance_dirty_pages() for a dirty throttling pause:
*/
int nr_dirtied;
int nr_dirtied_pause;
/* Start of a write-and-pause period: */
unsigned long dirty_paused_when;
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
/*
* Time slack values; these are used to round up poll() and
* select() etc timeout values. These are in nanoseconds.
*/
u64 timer_slack_ns;
u64 default_timer_slack_ns;
#if defined(CONFIG_KASAN_GENERIC) || defined(CONFIG_KASAN_SW_TAGS)
unsigned int kasan_depth;
#endif
#ifdef CONFIG_KCSAN
struct kcsan_ctx kcsan_ctx;
#ifdef CONFIG_TRACE_IRQFLAGS
struct irqtrace_events kcsan_save_irqtrace;
#endif
#endif
#if IS_ENABLED(CONFIG_KUNIT)
struct kunit *kunit_test;
#endif
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack: */
int curr_ret_stack;
int curr_ret_depth;
/* Stack of return addresses for return function tracing: */
struct ftrace_ret_stack *ret_stack;
/* Timestamp for last schedule: */
unsigned long long ftrace_timestamp;
/*
* Number of functions that haven't been traced
* because of depth overrun:
*/
atomic_t trace_overrun;
/* Pause tracing: */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING
/* State flags for use by tracers: */
unsigned long trace;
/* Bitmask and counter of trace recursion: */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
#ifdef CONFIG_KCOV
/* See kernel/kcov.c for more details. */
/* Coverage collection mode enabled for this task (0 if disabled): */
unsigned int kcov_mode;
/* Size of the kcov_area: */
unsigned int kcov_size;
/* Buffer for coverage collection: */
void *kcov_area;
/* KCOV descriptor wired with this task or NULL: */
struct kcov *kcov;
/* KCOV common handle for remote coverage collection: */
u64 kcov_handle;
/* KCOV sequence number: */
int kcov_sequence;
/* Collect coverage from softirq context: */
unsigned int kcov_softirq;
#endif
#ifdef CONFIG_MEMCG
struct mem_cgroup *memcg_in_oom;
gfp_t memcg_oom_gfp_mask;
int memcg_oom_order;
/* Number of pages to reclaim on returning to userland: */
unsigned int memcg_nr_pages_over_high;
/* Used by memcontrol for targeted memcg charge: */
///内存资源统计对象
struct mem_cgroup *active_memcg;
#endif
#ifdef CONFIG_BLK_CGROUP
struct request_queue *throttle_queue;
#endif
#ifdef CONFIG_UPROBES
struct uprobe_task *utask;
#endif
#if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE)
unsigned int sequential_io;
unsigned int sequential_io_avg;
#endif
struct kmap_ctrl kmap_ctrl;
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
unsigned long task_state_change;
# ifdef CONFIG_PREEMPT_RT
unsigned long saved_state_change;
# endif
#endif
int pagefault_disabled;
#ifdef CONFIG_MMU
struct task_struct *oom_reaper_list;
#endif
#ifdef CONFIG_VMAP_STACK
struct vm_struct *stack_vm_area;
#endif
#ifdef CONFIG_THREAD_INFO_IN_TASK
/* A live task holds one reference: */
refcount_t stack_refcount;
#endif
#ifdef CONFIG_LIVEPATCH
int patch_state;
#endif
#ifdef CONFIG_SECURITY
/* Used by LSM modules for access restriction: */
void *security;
#endif
#ifdef CONFIG_BPF_SYSCALL
/* Used by BPF task local storage */
struct bpf_local_storage __rcu *bpf_storage;
/* Used for BPF run context */
struct bpf_run_ctx *bpf_ctx;
#endif
#ifdef CONFIG_GCC_PLUGIN_STACKLEAK
unsigned long lowest_stack;
unsigned long prev_lowest_stack;
#endif
#ifdef CONFIG_X86_MCE
void __user *mce_vaddr;
__u64 mce_kflags;
u64 mce_addr;
__u64 mce_ripv : 1,
mce_whole_page : 1,
__mce_reserved : 62;
struct callback_head mce_kill_me;
int mce_count;
#endif
#ifdef CONFIG_KRETPROBES
struct llist_head kretprobe_instances;
#endif
#ifdef CONFIG_ARCH_HAS_PARANOID_L1D_FLUSH
/*
* If L1D flush is supported on mm context switch
* then we use this callback head to queue kill work
* to kill tasks that are not running on SMT disabled
* cores
*/
struct callback_head l1d_flush_kill;
#endif
/*
* New fields for task_struct should be added above here, so that
* they are included in the randomized portion of task_struct.
*/
randomized_struct_fields_end
/* CPU-specific state of this task: */
///switch_to时,保存进程的硬件上下文
struct thread_struct thread;
/*
* WARNING: on x86, 'thread_struct' contains a variable-sized
* structure. It *MUST* be at the end of 'task_struct'.
*
* Do not put anything below here!
*/
};基本信息
调度相关(Scheduling)
内存管理
信号相关
文件系统/资源
进程关系
时间统计
权限和身份
内核线程上下文
内核线程
内核线程是直接由内核本身启动的进程。内核线程实际上是将内核函数委托给独立的进程,与系统中其他进程“并行”执行(实际上,也并行于内核自身的执行),内核线程经常称之为(内核)守护进程。
内核线程的存在并不违背宏内核的设计理念,因为内核线程是“线程”而不是“进程”,内核线程在内核态运行且可以直接访问内核地址空间的所有内容,而无需使用进程间通信,所以本质上还是内核整体的一部分。
用于执行下列任务:
周期性地将修改的内存页与页来源块设备同步(例如,使用 mmap 的文件映射)(这里说的应该是块设备页的缓存,定期将脏页写入块设备持久化保存)。
如果内存页很少使用,则写入交换区。
管理延时动作(deferred action)。
实现文件系统的事务日志。
基本上,有两种类型的内核线程:
阻塞型:线程启动后一直等待,直至内核请求线程执行某一特定操作。
周期型:线程启动后按周期性间隔运行,检测特定资源的使用,在用量超出或低于预置的限制值时采取行动。内核使用这类线程用于连续监测任务。
调用 kernel_thread 函数可启动一个内核线程, fn 是要执行的函数,arg 是该函数的参数,flags 是 CLONE 标志(挺像 pthread 线程库的启动函数的):
// <asm-arch/processor.h>
int kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)kernel_thread 的第一个任务是构建一个 pt_regs 实例,对其中的寄存器指定适当的值,这与普通的 fork 系统调用类似。接下来调用我们熟悉的 do_fork 函数
p = do_fork(flags | CLONE_VM | CLONE_UNTRACED, 0, ®s, 0, NULL, NULL);因为内核线程是由内核自身生成的,应该注意下面两个特别之处:
(1) 它们在 CPU 的管态(supervisor mode)执行,而不是用户态。
(2) 它们只可以访问虚拟地址空间的内核部分(高于
TASK_SIZE的所有地址),但不能访问用户空间。
内核空间和用户空间
大多数计算机上系统的全部虚拟地址空间分割成两个部分:
用户空间:可以由用户层程序访问
内核空间:专供内核使用
内核空间和用户空间有很高的隔离性,用户进程无法访问内核空间,但可以通过系统调用陷入内核态,此时系统调用可以访问内核空间。处于内核态时,也不能直接访问用户空间,需要通过copy_from_user()和copy_to_user()API 保证访问合法性。
// <sched.h>
struct task_struct {
...
struct mm_struct *mm, *active_mm;
...
}进程所使用的用户空间由 task_struct 中的 mm 描述,当内核执行上下文切换时,内核会找对应进程的 mm,并以此做切换页表、更新 TLB 等其他操作。
内核线程通过把自己的 task_struct 中的 mm 设置为 NULL 来避免访问用户空间(即使这些用户空间也是这个进程私有的,这是为了惰性 TLB 功能)
惰性 TLB:假如用户进程切换到内核线程,又切回同一个用户进程,此时由于内核线程不会去改 mm 内的东西(因为 mm 被设为 NULL 了,这些空间访问不到,也改不了),所以 TLB 表可以不切换到内核线程,从内核线程退出时 TLB 表也不用切换,相当于省了两次切换。
内核线程可以用下面几种方法实现:
直接调用
kernel_thread该函数从内核线程释放其父进程(用户进程)的所有资源(为了避免冲突,所有资源都会被上锁,直到线程结束,但一般内核线程会一直运行,所以干脆把父进程的资源都释放了,反正也用不了了)
daemonize 阻塞信号的接收
将 init 用作该内核线程的父进程
使用更现代的
kthread_create// kernel/kthread.c struct task_struct *kthread_create(int (*threadfn)(void *data), void *data, const char namefmt[], ...)最初该线程是停止的,需要使用 wake_up_process 启动它。宏 kthread_run 封装了创建和启动
kthread_create_cpu 可以取代 kthread_create 用于绑定特定 CPU
使用
kthread_runkthread_run 封装了 kthread_create 和 wake_up_process,也就是创建和启动过程合并了
内核线程会出现在系统进程列表中,但在 ps 的输出中由方括号包围,以便与普通进程区分,斜杠后表示绑定的 CPU 编号:
ps fax
PID TTY STAT TIME COMMAND
2? S< 0:00 [kthreadd]
3? S< 0:00 _ [migration/0]
4? S< 0:00 _ [ksoftirqd/0]
5? S< 0:00 _ [migration/1]
6? S< 0:00 _ [ksoftirqd/1]
...
52? S< 0:00 _ [kblockd/3]
55? S< 0:00 _ [kacpid]
56? S< 0:00 _ [kacpi_notify]
..调度器的实现
Linux进程调度机制的历史
从Linux1.0到2.4的内核,进程调度程序都比较简陋。2.5版本对调度程序做了大的改进,被称为O(1)调度器。该调度器能够在数以10计的多处理器环境下表现良好,但是对响应时间敏感(例如用户交互)的程序则表现的差强人意。
2.6版本开发初期,为了提高交互程序的调度性能,Linux开发团队引入了新的进程调度算法——完全公平调度算法(CFS),并在2.6.23内核版本中代替O(1)算法,
进程调度策略
内核必须提供一种方法,在各个进程之间尽可能公平地共享 CPU 时间,而同时又要考虑不同的任务优先级。
schedule 函数是理解调度操作的起点。该函数定义在 kernel/sched.c 中,是内核代码中最常调用的函数之一。
Linux 调度器的一个杰出特性是:它不需要时间片概念,至少不需要传统的时间片。经典的调度器对系统中的进程分别计算时间片,使进程运行直至时间片用尽。在所有进程的所有时间片都已经用尽时,则需要重新计算。相比之下,Linux 的调度器只考虑进程的等待时间,即进程在就绪队列(run-queue)中已经等待了多长时间。对 CPU 时间需求最严格的进程被调度执行。
我们可以把等待时间视为一种不公平因素,等待时间越长越不公平,而依次轮流运行很难解决该问题。所以需要考虑等待时间的调度策略。
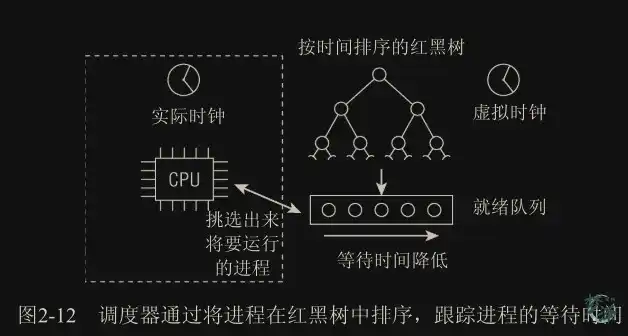
I/O消耗型和处理器消耗型进程
这是一种进程的分类方式:
I/O消耗型:大部分时间用来提交I/O请求或者等待I/O请求,这类进程通常都是运行很短的时间,即被阻塞。引起阻塞的I/O资源可以是鼠标键盘输入、网络I/O等等。大部分GUI程序都是I/O消耗型的,因为其大部分时间需要等待用户交互
处理器消耗型:大部分时间用来执行代码(指令)。除非被强占,这类进程经常不停的执行。由于这类进程的I/O需求较小,因此调度系统会降低其调度频率,以提供系统的响应速度(允许其它I/O型程序能够尽快获得执行机会)。调度系统倾向于在降低调度频率的同时,延长这类进程的执行时间。处理器消耗型进程的典型例子是科学计算应用,极端例子是无限空循环
现实场景中,很多程序不能简单的划分到这两类之一,例如X Window服务既是I/O消耗型,也是处理器消耗型。
调度策略需要在响应时间(响应高速性,进程能否尽快的获取CPU)和吞吐量(最大系统利用率,单位时间执行的有效指令数量)两个目标之间寻求平衡,Linux更加倾向于优先调度I/O消耗型进程,以缩短响应时间。
进程优先级
进程按优先级可分为硬实时进程、软实时进程、普通进程。
硬实时进程
有严格的时间限制,某些任务必须在指定的时限内完成。
实时操作系统就是用来做这件事的,Linux 并非实时操作系统,不支持硬实时进程。Linux 是针对吞吐量优化的,试图尽快地处理常见情形,其实很难实现可保证的响应时间。
软实时进程
硬实时进程的一种弱化形式。尽管仍然需要快速得到结果,但稍微晚一点也能接受
普通进程
没有特定时间约束,但仍然可以根据重要性来分配优先级。
Linux 采用了两种不同的优先级范围:
nice 值:用于表示非实时进程的优先级,它的范围是从-20 到+19,默认值为 0;越大的 nice 值意味着更低的优先级
实时优先级:默认情况下它的变化范围是从 0 到 99。这是为了处理实时进程(Linux 支持软实时进程),实时进程(无论实时优先级值大小)总是优先于普通进程(无实时优先级)。
nice 值与实时优先级属于两个体系,并无直接关系。
时间片
时间片是一个数值,用来表示进程被抢占前,能够持续运行的时间。时间片过长会导致人机交互的响应速度欠佳;时间片过短则明显增大进程切换的开销。I/O消耗型进程不需要太长时间片;CPU消耗型进程则希望时间片越长越好。
为了增加交互响应速度,很多OS把时间片设置为很短的绝对值,例如10ms。Linux的CFS调度器则是以占用CPU时间的比例来定义时间片,这就意味着进程获取的CPU时间和系统负载密切相关,这一比例进一步收到nice值的影响,低nice值的进程获得更多的CPU时间比例。
大部分抢占式系统中,一旦一个进程进入可运行状态,它是否立即投入运行(即抢占CPU上的当前进程),完全由进程的优先级和是否拥有时间片来决定,Linux的CFS调度使用更加复杂的算法:如果新的可运行进程已消耗的CPU时间比例比较小,则立即抢占,否则推迟执行
调度相关的数据结构
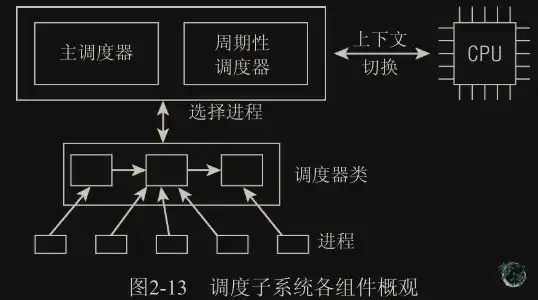
如图所示可以用两种方法激活调度:
主调度器(generic scheduler):直接的,比如进程打算睡眠或出于其他原因
放弃CPU;核心调度器(core scheduler):通过周期性机制,以固定的频率运行,不时检测是否有必要进行进程切换。
在调度器被调用时,它会查询调度器类,得知接下来运行哪个进程。内核支持不同的调度策略(完全公平调度、实时调度、在无事可做时调度空闲进程等),每种策略对应一个调度器类。每个进程都只属于某一调度器类,各个调度器类负责管理所属的进程。
在选中将要运行的进程之后,必须执行底层任务切换。这需要与 CPU 的紧密交互。
task_struct中与调度相关的成员
// <sched.h>
struct task_struct
{
...
int prio, static_prio, normal_prio;
unsigned int rt_priority;
struct list_head run_list;
const struct sched_class *sched_class;
struct sched_entity se;
unsigned int policy;
cpumask_t cpus_allowed;
unsigned int time_slice;
...
}prio, static_prio, normal_prio 优先级,静态优先级和普通优先级。静态优先级是进程启动时分配的优先级。normal_priority 表示基于进程的静态优先级和调度策略计算出的优先级。调度器考虑的优先级则保存在 prio
rt_priority 表示实时进程的实时优先级。0-99,值越大,表明优先级越高。
sched_class 表示该进程所属的调度器类。
se 调度器不限于调度进程,还可以处理更大的实体(entity)。这个实体可以是进程组,也就是多个进程的集合,然后再在组内自行调度每个进程。所以调度器实际上调度的是一个
实体(sched_entity 结构实例),为了调度单进程,需要在 task_struct 结构内加上 sched_entity 结构将其视为一个实体policy 保存了对该进程应用的调度策略。Linux 支持 5 个可能的值,和 sched_class 关联的调度器类有关
SCHED_NORMAL 用于普通进程,通过完全公平调度器来处理
SCHED_BATCH 用于非交互、CPU 密集型的批处理进程。权重较低。
SCHED_IDLE 进程的重要性也比较低,相对权重最小(注意这个不是空闲进程的意思)
SCHED_RR 和 SCHED_FIFO 用于实现软实时进程。SCHED_RR 实现了一种循环方法,而 SCHED_FIFO 则使用先进先出机制。这类进程不是由完全公平调度器类处理,而是由实时调度器类处理,
cpus_allowed 是一个位域,在多处理器系统上使用,用来限制进程可以在哪些 CPU 上运行。
run_list 和 time_slice 是循环实时调度器所需要的,不用于完全公平调度器。run_list 是一个表头,用于维护包含各进程的一个运行表,而 time_slice 则指定进程可使用 CPU 的剩余时间段。
调度器类
Linux以模块的方式提供调度器,以便不同类型的进程可以选择不同的调度算法。这一模块化的结构被称为调度器类(Scheduler Classes),它允许多种可以动态添加的调度算法共存,并遵守以下规则:
每一个调度器负责调度自己管理的进程
每一个调度器具有一个优先级
调度器会按优先级高低被遍历,用于一个可运行进程的、最高优先级的调度器胜出
胜出的调度器决定下一个运行的进程
CFS是针对普通进程的调度器类,在Linux中被称为SCHED_NORMAL,定义在kernel/sched_fair.c中。
目前 Linux 提供以下调度器类:
Completely Fair Scheduler (CFS):CFS 是 Linux 内核默认的调度器,采用红黑树数据结构来维护进程队列,并根据进程的优先级和时间片大小来进行进程调度。
Real-time Scheduler (RT):Real-time Scheduler 是 Linux 内核提供的实时调度器,可用于需要满足硬实时性要求的应用程序。它提供了多种调度策略,如 FIFO、RR 和 Deadline 等。
Deadline Scheduler:Deadline Scheduler 是一种基于 Deadline 的调度器,可以确保任务在其截止时间之前完成。它适用于嵌入式和实时系统中的任务调度。它可以让 Linux 的实时性能得到显著的提升,但是并不能完全将 Linux 变成硬实时操作系统。
本文介绍其中最常用的 CFS 和实时调度器类。
sched_class 结构提供了通用调度器和各个调度方法之间的关联:
// <sched.h>
struct sched_class
{
// 各个调度器类构成单向链表,见上图
const struct sched_class *next;
// 进程加入就绪队列
void (*enqueue_task)(struct rq *rq, struct task_struct *p, int wakeup);
// 从就绪队列删除进程
void (*dequeue_task)(struct rq *rq, struct task_struct *p, int sleep);
// 进程主动放弃CPU时该函数被内核调用
void (*yield_task)(struct rq *rq);
// 用一个新唤醒的进程来抢占当前进程
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p);
// 选择下一个将要运行的进程
struct task_struct *(*pick_next_task)(struct rq *rq);
// 用另一个进程代替当前运行的进程之前调用
void (*put_prev_task)(struct rq *rq, struct task_struct *p);
// 在进程的调度策略发生变化时调用
void (*set_curr_task)(struct rq *rq);
// 在每次激活周期性调度器时,由周期性调度器调用。
void (*task_tick)(struct rq *rq, struct task_struct *p);
// 用于建立fork系统调用和调度器之间的关联。每次新进程建立后,则用new_task 通知调度器。
void (*task_new)(struct rq *rq, struct task_struct *p);
};用户层应用程序无法直接与调度器类交互。它们只知道自己的 policy(如SCHED_NORMAL),也就是自己属于哪类进程(具体由哪个调度器类处理无法得知)。
内核负责将这些常量和可用的调度器类之间提供适当的映射。
fair_sched_class(CFS 类):SCHED_NORMAL、SCHED_BATCH和SCHED_IDLErt_sched_class(实时调度器类):SCHED_RR和SCHED_FIFO
fair_sched_class 和 rt_sched_class 都是 struct sched_class 的实例,分别表示完全公平调度器类和实时调度器类。
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
DEFINE_SCHED_CLASS(fair) = {
.enqueue_task = enqueue_task_fair, ///把进程添加紧rq
.dequeue_task = dequeue_task_fair, ///把进程移除rq
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup, ///检查是否需要抢占当前进程
.pick_next_task = __pick_next_task_fair, ///从就绪队列选择一个最有进程来运行
.put_prev_task = put_prev_task_fair, ///把prev进程重新添加到就绪队列中
.set_next_task = set_next_task_fair, ///修改policy或group
#ifdef CONFIG_SMP
.balance = balance_fair,
.pick_task = pick_task_fair,
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair, ///用于迁移进程到一个新的rq
.rq_online = rq_online_fair, ///设置rq状态为online
.rq_offline = rq_offline_fair, ///关闭就绪队列
.task_dead = task_dead_fair, ///处理已终止的基层你
.set_cpus_allowed = set_cpus_allowed_common, ///设置CPU可运行CPU范围
#endif
.task_tick = task_tick_fair, ///处理时钟节拍
.task_fork = task_fork_fair, ///处理新进程与调度相关的一些初始化信息
.prio_changed = prio_changed_fair, ///改变进程优先级
.switched_from = switched_from_fair, ///切换调度类
.switched_to = switched_to_fair, ///切换到下一个进程运行
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair, ///更新fq的运行时间,CFS更新虚拟时间
#ifdef CONFIG_FAIR_GROUP_SCHED
.task_change_group = task_change_group_fair,
#endif
#ifdef CONFIG_UCLAMP_TASK
.uclamp_enabled = 1,
#endif
}runqueue就绪队列
各个 CPU 都有自身的就绪队列,对应 struct rq,各个活动进程只出现在一个就绪队列中。
进程并不是由就绪队列的成员直接管理的,而是由各个调度器类分别管理,因此在各个就绪队列中嵌入了特定于调度器类的子就绪队列。
/*
* per-CPU变量,描述CPU通用就绪队列,rq记录一个就绪队列所需要的全部信息;
* 包括一个CFS就绪队列cfs_rq, 一个rt_rq, 一个dl_rq,
* 以及就绪队列的负载权重等信息
* */
struct rq {
/* runqueue lock: */
raw_spinlock_t __lock; ///保护通用就绪队列自旋锁
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned int nr_running; ///就绪队列中可运行的进程数量
#ifdef CONFIG_NUMA_BALANCING
unsigned int nr_numa_running;
unsigned int nr_preferred_running;
unsigned int numa_migrate_on;
#endif
#ifdef CONFIG_NO_HZ_COMMON
#ifdef CONFIG_SMP
unsigned long last_blocked_load_update_tick;
unsigned int has_blocked_load;
call_single_data_t nohz_csd;
#endif /* CONFIG_SMP */
unsigned int nohz_tick_stopped;
atomic_t nohz_flags;
#endif /* CONFIG_NO_HZ_COMMON */
#ifdef CONFIG_SMP
unsigned int ttwu_pending;
#endif
u64 nr_switches; ///进程切换次数
#ifdef CONFIG_UCLAMP_TASK
/* Utilization clamp values based on CPU's RUNNABLE tasks */
struct uclamp_rq uclamp[UCLAMP_CNT] ____cacheline_aligned;
unsigned int uclamp_flags;
#define UCLAMP_FLAG_IDLE 0x01
#endif
struct cfs_rq cfs; ///指向cfs就绪队列
struct rt_rq rt; ///指向实时进程就绪队列
struct dl_rq dl; ///指向dl进程就绪队列
#ifdef CONFIG_FAIR_GROUP_SCHED
/* list of leaf cfs_rq on this CPU: */
struct list_head leaf_cfs_rq_list;
struct list_head *tmp_alone_branch;
#endif /* CONFIG_FAIR_GROUP_SCHED */
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned int nr_uninterruptible; ///不可中断进程进入rq的次数
struct task_struct __rcu *curr; ///指向正在运行的进程
struct task_struct *idle; ///指向idle进程
struct task_struct *stop; ///指向系统的stop进程
unsigned long next_balance; ///下一次做负载均衡的时间
struct mm_struct *prev_mm; ///进程切换时,指向前一个进程的mm
unsigned int clock_update_flags; ///更新就绪队列时钟的标志位
u64 clock;
/* Ensure that all clocks are in the same cache line */
u64 clock_task ____cacheline_aligned; ///计算vruntime使用该时钟,每次时钟节拍到来时都会更新
u64 clock_pelt;
unsigned long lost_idle_time;
atomic_t nr_iowait;
#ifdef CONFIG_SCHED_DEBUG
u64 last_seen_need_resched_ns;
int ticks_without_resched;
#endif
#ifdef CONFIG_MEMBARRIER
int membarrier_state;
#endif
#ifdef CONFIG_SMP
struct root_domain *rd; ///调度域的根
struct sched_domain __rcu *sd; ///指向CPU对应的最低等级的调度域
unsigned long cpu_capacity; ///cpu对应普通进程的量化计算能力,系统大约预留80%计算能力给普通进程,20%给实时进程
unsigned long cpu_capacity_orig; ///CPU最高的量化计算能力,通常为1024
struct callback_head *balance_callback;
unsigned char nohz_idle_balance;
unsigned char idle_balance;
unsigned long misfit_task_load; ///若一个进程实际算力大于CPU额定算力的80%,那这是个不合适的进程misfit_task
/* For active balancing */
int active_balance;
int push_cpu; ///用于负载均衡,表示迁移的目标CPU
struct cpu_stop_work active_balance_work;
/* CPU of this runqueue: */
int cpu; ///表示就绪队列运行在哪个CPU上
int online; ///表示CPU处于active或online状态
struct list_head cfs_tasks; ///可运行状态的se都添加到这个链表
struct sched_avg avg_rt;
struct sched_avg avg_dl;
#ifdef CONFIG_HAVE_SCHED_AVG_IRQ
struct sched_avg avg_irq;
#endif
#ifdef CONFIG_SCHED_THERMAL_PRESSURE
struct sched_avg avg_thermal;
#endif
u64 idle_stamp;
u64 avg_idle;
unsigned long wake_stamp;
u64 wake_avg_idle;
/* This is used to determine avg_idle's max value */
u64 max_idle_balance_cost;
#ifdef CONFIG_HOTPLUG_CPU
struct rcuwait hotplug_wait;
#endif
#endif /* CONFIG_SMP */
#ifdef CONFIG_IRQ_TIME_ACCOUNTING
u64 prev_irq_time;
#endif
#ifdef CONFIG_PARAVIRT
u64 prev_steal_time;
#endif
#ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING
u64 prev_steal_time_rq;
#endif
/* calc_load related fields */
unsigned long calc_load_update;
long calc_load_active;
#ifdef CONFIG_SCHED_HRTICK
#ifdef CONFIG_SMP
call_single_data_t hrtick_csd;
#endif
struct hrtimer hrtick_timer;
ktime_t hrtick_time;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
unsigned long long rq_cpu_time;
/* could above be rq->cfs_rq.exec_clock + rq->rt_rq.rt_runtime ? */
/* sys_sched_yield() stats */
unsigned int yld_count;
/* schedule() stats */
unsigned int sched_count;
unsigned int sched_goidle;
/* try_to_wake_up() stats */
unsigned int ttwu_count;
unsigned int ttwu_local;
#endif
#ifdef CONFIG_CPU_IDLE
/* Must be inspected within a rcu lock section */
struct cpuidle_state *idle_state;
#endif
#ifdef CONFIG_SMP
unsigned int nr_pinned;
#endif
unsigned int push_busy;
struct cpu_stop_work push_work;
#ifdef CONFIG_SCHED_CORE
/* per rq */
struct rq *core;
struct task_struct *core_pick;
unsigned int core_enabled;
unsigned int core_sched_seq;
struct rb_root core_tree;
/* shared state -- careful with sched_core_cpu_deactivate() */
unsigned int core_task_seq;
unsigned int core_pick_seq;
unsigned long core_cookie;
unsigned char core_forceidle;
unsigned int core_forceidle_seq;
#endif
};系统的所有就绪队列都在 runqueues 数组中,该数组的每个元素分别对应于系统中的一个 CPU。在单处理器系统中,由于只需要一个就绪队列,数组只有一个元素:
DECLARE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu)))
#define this_rq() this_cpu_ptr(&runqueues)
#define task_rq(p) cpu_rq(task_cpu(p))
#define cpu_curr(cpu) (cpu_rq(cpu)->curr)
#define raw_rq() raw_cpu_ptr(&runqueues)调度实体(sched_entity)
调度器操作的是比进程描述符更通用的调度实体(sched_entity),而非 task_struct 结构。
struct sched_entity {
/* For load-balancing: */
struct load_weight load; ///权重信息,计算vruntime的时候,会用到in_weight
struct rb_node run_node; ///红黑树挂载点
struct list_head group_node; ///se加入就绪队列后,添加到rq->cfs_tasks链表
unsigned int on_rq; ///已加入就绪队列,on_rq=1,否则on_rq=0
u64 exec_start; ///se虚拟时间的起始时间
u64 sum_exec_runtime; ///实际运行时间总和
u64 vruntime; ///虚拟运行时间,加权后的时间,单位ns,与定时器节拍无关
u64 prev_sum_exec_runtime; ///上一次统计se运行总时间
u64 nr_migrations; ///该se发生迁移的次数
struct sched_statistics statistics; ///统计信息
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
///该se挂在到cfs_rq,指向parent->my_rq
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
///本se的cfs_rq,只有group se才有cfs_rq,task_se为NULl
struct cfs_rq *my_q;
/* cached value of my_q->h_nr_running */
unsigned long runnable_weight;
#endif
#ifdef CONFIG_SMP
/*
* Per entity load average tracking.
*
* Put into separate cache line so it does not
* collide with read-mostly values above.
*/
struct sched_avg avg; ///负载相关的信息
#endif
};每个 task_struct 都嵌入了一个 sched_entity 成员,以便其可以被调度器调度。多个进程可以合并为调度组,由同一个调度实体管理(组调度),通过启用CONFIG_FAIR_GROUP_SCHED实现:
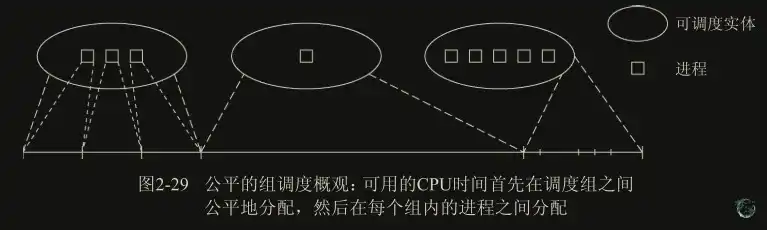
处理优先级
Linux 中的 nice 值表示进程的友好度,范围为[-20,+19],越高越友好,表示其更愿意让出 CPU,相反越低表示其越“吝啬”和严格。
nice 值是优先级和权重的基础,Linux 会根据 nice 值计算各进程的优先级和权重。
优先级的内核表示
在用户空间可以通过 nice 命令设置进程的静态优先级,这在内部会调用 nice 系统调用。进程的 nice 值在 -20 和+19 之间(包含)。值越低,表明优先级越高。
内核使用一个简单些的数值范围,从 0 到 139(包含),用来表示内部优先级,整合了实时和非实时进程的优先级。同样是值越低,优先级越高。从 0 到 99 的范围专供实时进程使用。nice 值[-20, +19]映射到范围 100 到 139,如图 2-14 所示。 实时进程的优先级总是比普通进程更高。
/*
* Priority of a process goes from 0..MAX_PRIO-1, valid RT
* priority is 0..MAX_RT_PRIO-1, and SCHED_NORMAL/SCHED_BATCH
* tasks are in the range MAX_RT_PRIO..MAX_PRIO-1. Priority
* values are inverted: lower p->prio value means higher priority.
*/
#define MAX_RT_PRIO 100
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH)
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
/*
* Convert user-nice values [ -20 ... 0 ... 19 ]
* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],
* and back.
*/
#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO)
#define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)计算优先级
动态优先级(task_struct->prio)
普通优先级(task_struct->normal_prio)
静态优先级(task_struct->static_prio)
这些优先级按有趣的方式彼此关联,动态优先级和普通优先级通过静态优先级计算而来:
p->prio = effective_prio(p);
// kernel/sched.c
// 计算动态优先级
static int effective_prio(struct task_struct *p)
{
// 计算普通优先级
p->normal_prio = normal_prio(p);
if (!rt_prio(p->prio))
// 如果不是实时进程,返回普通优先级(会赋值给p->prio)
return p->normal_prio;
/* 如果是实时进程(或是临时提高至实时优先级的普通进程),则保持优先级不变。*/
return p->prio;
}
// kernel/sched.c
// 计算普通优先级
static inline int normal_prio(struct task_struct *p)
{
int prio;
// 如果是实时进程
if (task_has_rt_policy(p))
// 利用task_struct中的rt_priority
// rt_priority是个独立的用于表示实时优先度的变量,越高优先度越高
// 由于该优先度表示和内核优先级相反(内核是越小越高),
// 需要用减法做处理
prio = MAX_RT_PRIO - 1 - p->rt_priority;
// 如果是普通进程
else
prio = __normal_prio(p);
return prio;
}
// kernel/sched.c
static inline int __normal_prio(struct task_struct *p)
{
// 如果是普通进程,直接让normal优先级和static相同
return p->static_prio;
}对各种类型的进程计算优先级结果:
从上表可知,内核允许让非实时进程通过修改 prio 的值来临时上升为实时进程优先级,prio 值除非被单独修改否则后续不会受到 static_prio 的影响(比如用 nice 修改 static_prio)。
在进程分支出子进程时,子进程的静态优先级继承自父进程。子进程的动态优先级,即 task_struct->prio,则设置为父进程的普通优先级。这确保了实时互斥量引起的优先级提高不会传递到子进程。
计算负荷权重
进程的重要性不仅由优先级决定,还需要考虑权重(保存在 task_struct->se.load)。Linux 调度器类会根据优先级和权重共同计算下个要调度的进程,以及其可占用的 CPU 时间。
// <sched.h>
struct load_weight
{
unsigned long weight, inv_weight;
};set_load_weight() 函数负责根据进程类型及其静态优先级计算权重。内核不仅维护了权重自身(weight),而且还有另一个数值(inv_weight),用于表示权重倒数(1/weight)。
一般概念是这样,进程每降低一个 nice 值,则多获得 10% 的 CPU 时间,每升高一个 nice 值,则放弃 10% 的 CPU 时间。为执行该策略,内核将优先级转换为权重值。我们首先看一下转换表:
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};对内核使用的范围[-20, +15]中的每个 nice 级别,该数组中都有一个对应项(映射到 0-39)。数组各项间的乘数因子是 1.25(index项 是 index+1项 的 1.25 倍,这是为了上面说的增加 nice 值带来的 10% CPU 时间提升)。
两个进程 A 和 B 在 nice 级别 0 运行,因此两个进程的 CPU 份额相同,即都是 50%。nice 级别为 0 的进程,其权重查表可知为 1024。每个进程的份额是 1024/(1024+1024)=0.5,即 50%。如果进程 B 的优先级值加 1(优先级降低),那么其 CPU 份额应该减少 10%。换句话说,这意味着进程 A 得到总的 CPU 时间的 55%,而进程 B 得到 45%。优先级增加 1 导致权重减少,即 1024/1.25≈820。因此进程 A 现在将得到的 CPU 份额是 1024/(1024+820)≈0.55(数学中标准权重占比计算方式),而进程 B 的份额则是 820/(1024+820)≈0.45,这样就产生了 10% 的差值。
执行转换的代码也需要考虑实时进程。实时进程的权重至少是普通进程的两倍,而SCHED_IDLE类型的空闲进程的权重总是非常小:
// kernel/sched.c
#define WEIGHT_IDLEPRIO 2
#define WMULT_IDLEPRIO (1 << 31)
static void
set_load_weight(struct task_struct *p)
{
// 如果是实时进程
if (task_has_rt_policy(p))
{
// 权重总是最大值,且需要翻个倍
p->se.load.weight = prio_to_weight[0] * 2;
// 计算倒数,保存到inv_weight
p->se.load.inv_weight = prio_to_wmult[0] >> 1;
return;
}
/** SCHED_IDLE进程得到的权重最小:
*/
if (p->policy == SCHED_IDLE)
{
p->se.load.weight = WEIGHT_IDLEPRIO;
p->se.load.inv_weight = WMULT_IDLEPRIO;
return;
}
// 如果是非实时普通进程
p->se.load.weight = prio_to_weight[p->static_prio - MAX_RT_PRIO];
p->se.load.inv_weight = prio_to_wmult[p->static_prio - MAX_RT_PRIO];
}计算负荷
在 Linux 系统中,系统负荷(system load) 是指的是在给定时刻的可运行状态(TASK_RUNNING) 和 不可中断状态(TASK_UNINTERRUPTIBLE) 的进程数量,处于空闲状态时为 0。
一般使用一段时间内的 平均系统负荷(load average) 来表示系统运行情况(下面例子是单核 CPU 的情况):
当平均负荷小于 1 时,表示这段时间 CPU 不仅能处理所有进程,还有部分时间处于没有进程运行的空闲状态,也就是说这段时间内所有的进程都得到了所需的 CPU 时间;
当平均负荷大于 1 时,表示肯定有部分进程没有获得所需的 CPU 时间;
如果持续过高,表示有部分进程长时间处于饥饿状态。
系统负荷和 CPU 使用率并无直接关系,高负荷也有可能是过多的 I/O 导致的(占用 CPU 时间片但并实际是在忙等待,忙等待一般采取休眠 CPU 并轮询的方式,持续占用 CPU 但 CPU 使用率并不高)。可以说系统负荷表示 CPU 时间的占用率,具体进程占用时间片用于什么目的才能决定 CPU 的使用率。
不同 CPU 指令的消耗
当 CPU 执行指令时,会产生电流和功率消耗。一些指令需要更多的电流和功率,因此会产生更多的热量。例如,浮点数运算、乘法和除法等指令需要更多的电流和功率,因此会产生更多的热量,而移位、逻辑运算等指令则需要更少的电流和功率,因此产生的热量也相对较少。而 空指令(NOP) 仅占用 CPU 时间,不执行任何操作,几乎不消耗额外资源。
之前在就绪队列一节提到就绪队列 rq 中有一个 load,表示负荷值。它和系统负荷相关,但它并不表示系统负荷(system load),真正的系统负荷需要结合调度策略等共同计算。
每次进程被加到就绪队列时,内核会调用 inc_nr_running 添加该负荷:
核心调度器
调度器的实现基于两个函数:
周期性调度器函数
主调度器函数
周期性调度器
周期性调度器函数 scheduler_tick()在每个 CPU ticks 调用一次,该函数有下面两个主要任务:
(1) 管理内核中与整个系统和各个进程的调度相关的统计量。其间执行的主要操作是对各种
计数器加 1。(2) 激活负责当前进程的调度类的周期性调度方法(
task_tick钩子)
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
struct rq_flags rf;
unsigned long thermal_pressure;
u64 resched_latency;
arch_scale_freq_tick();
sched_clock_tick();
rq_lock(rq, &rf);
///更新当前CPU就绪队列rq中的时钟计数clock和clock_task
update_rq_clock(rq);
thermal_pressure = arch_scale_thermal_pressure(cpu_of(rq));
update_thermal_load_avg(rq_clock_thermal(rq), rq, thermal_pressure);
///调度类的方法,处理时钟节拍到来时调度器相关事情
curr->sched_class->task_tick(rq, curr, 0);
if (sched_feat(LATENCY_WARN))
resched_latency = cpu_resched_latency(rq);
calc_global_load_tick(rq);
rq_unlock(rq, &rf);
if (sched_feat(LATENCY_WARN) && resched_latency)
resched_latency_warn(cpu, resched_latency);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
///触发SMP负载均衡机制,每个始终tick都会检查是否需要负载均衡
trigger_load_balance(rq);
#endif
}task_tick 的实现方式取决于底层的调度器类。例如,完全公平调度器会在该方法中检测是否进程已经运行太长时间,以避免过长的延迟。(这里就是和时间片轮转不同的地方,完全公平调度器会实时检测进程的运行的时长而动态调整调度它的时间,而不是死板的进程开始就确定只能运行多长时间片)
如果当前进程应该被重新调度(还没执行结束就被抢占了),那么调度器类方法会在 task_struct 中设置 TIF_NEED_RESCHED 标志(需要调度标志),而内核会在接下来的适当时机完成该请求。
也就是说周期性调度器并不负责执行调度过程,只是设置应该调度的标志,后续会由内核在合适的时候调用主调度器schedule()根据标志执行调度。(一般来说内核会在定时中断返回用户空间前执行一次schedule(),给了一次调度的机会)
主调度器
在内核中的许多地方,如果要将 CPU 分配给与当前活动进程不同的另一个进程(切换进程),都会直接调用主调度器函数(schedule)。在从系统调用返回之后(如果支持内核抢占,中断返回后也会检测一次),内核也会检查当前进程是否设置了重调度标志 TIF_NEED_RESCHED,例如,前述的 scheduler_tick 就会设置该标志,标志置位时内核会调用 schedule()。
会调用 schedule 的函数模板必须有 __sched 前缀:
void __sched some_function(...) {
...
schedule();
...
}__sched 前缀:该前缀用于所有可能调用 schedule 的函数, 包括 schedule 自身。该前缀目的在于,将相关函数的代码编译之后,放到目标文件的一个特定的段中,即.sched.text 中。该信息使得内核在显示栈转储或类似信息时,忽略所有与调度有关的调用。由于调度器函数调用不是普通代码流程的一部分,因此在这种情况下这些信息和被调度的进程是没有关系的。
schedule() 的实现:
static void __sched notrace __schedule(unsigned int sched_mode)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
unsigned long prev_state;
struct rq_flags rf;
struct rq *rq;
int cpu;
///获取当前CPU
cpu = smp_processor_id();
///获取当前CPU的rq
rq = cpu_rq(cpu);
///prev指向当前进程,完成切换后,当前进程就变成了prev进程
prev = rq->curr;
///判断是否是atomic上下文(硬件中断上下文,软件中断上下文),若是则报dbug
schedule_debug(prev, !!sched_mode);
if (sched_feat(HRTICK) || sched_feat(HRTICK_DL))
hrtick_clear(rq);
///关闭本地CPU中断
local_irq_disable();
rcu_note_context_switch(!!sched_mode);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up():
*
* __set_current_state(@state) signal_wake_up()
* schedule() set_tsk_thread_flag(p, TIF_SIGPENDING)
* wake_up_state(p, state)
* LOCK rq->lock LOCK p->pi_state
* smp_mb__after_spinlock() smp_mb__after_spinlock()
* if (signal_pending_state()) if (p->state & @state)
*
* Also, the membarrier system call requires a full memory barrier
* after coming from user-space, before storing to rq->curr.
*/
rq_lock(rq, &rf);
smp_mb__after_spinlock();
/* Promote REQ to ACT */
rq->clock_update_flags <<= 1;
update_rq_clock(rq);
switch_count = &prev->nivcsw;
/*
* We must load prev->state once (task_struct::state is volatile), such
* that:
*
* - we form a control dependency vs deactivate_task() below.
* - ptrace_{,un}freeze_traced() can change ->state underneath us.
*/
prev_state = READ_ONCE(prev->__state);
///判断为主动让出CPU
///防止进程切换前某时刻,发生中断,中断返回时发生抢占,若不加处理直接移出rq,可能导致本进程永远无法再得到调度
///linux中,当进程处于运行态或就绪态,进程在rq中,进程需要睡眠则移出rq,当进程被唤醒,会重新加入就绪队列中
if (!(sched_mode & SM_MASK_PREEMPT) && prev_state) {
if (signal_pending_state(prev_state, prev)) {
WRITE_ONCE(prev->__state, TASK_RUNNING);
} else {
prev->sched_contributes_to_load =
(prev_state & TASK_UNINTERRUPTIBLE) &&
!(prev_state & TASK_NOLOAD) &&
!(prev->flags & PF_FROZEN);
if (prev->sched_contributes_to_load)
rq->nr_uninterruptible++;
/*
* __schedule() ttwu()
* prev_state = prev->state; if (p->on_rq && ...)
* if (prev_state) goto out;
* p->on_rq = 0; smp_acquire__after_ctrl_dep();
* p->state = TASK_WAKING
*
* Where __schedule() and ttwu() have matching control dependencies.
*
* After this, schedule() must not care about p->state any more.
*/
///主动调度让出CPU,移出就绪队列
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
if (prev->in_iowait) {
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
}
switch_count = &prev->nvcsw;
}
///preempt发生抢占调度,直接获取进程
///从就绪队列获取合适进程,比如CFS会从红黑树中寻找最左边节点对应的进程
next = pick_next_task(rq, prev, &rf);
///清除调度标记,保证本进程不会被调度
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
#ifdef CONFIG_SCHED_DEBUG
rq->last_seen_need_resched_ns = 0;
#endif
if (likely(prev != next)) {
rq->nr_switches++;
/*
* RCU users of rcu_dereference(rq->curr) may not see
* changes to task_struct made by pick_next_task().
*/
RCU_INIT_POINTER(rq->curr, next);
/*
* The membarrier system call requires each architecture
* to have a full memory barrier after updating
* rq->curr, before returning to user-space.
*
* Here are the schemes providing that barrier on the
* various architectures:
* - mm ? switch_mm() : mmdrop() for x86, s390, sparc, PowerPC.
* switch_mm() rely on membarrier_arch_switch_mm() on PowerPC.
* - finish_lock_switch() for weakly-ordered
* architectures where spin_unlock is a full barrier,
* - switch_to() for arm64 (weakly-ordered, spin_unlock
* is a RELEASE barrier),
*/
++*switch_count;
migrate_disable_switch(rq, prev);
psi_sched_switch(prev, next, !task_on_rq_queued(prev));
trace_sched_switch(sched_mode & SM_MASK_PREEMPT, prev, next);
/* Also unlocks the rq: */
///进程切换
rq = context_switch(rq, prev, next, &rf);
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unpin_lock(rq, &rf);
__balance_callbacks(rq);
raw_spin_rq_unlock_irq(rq);
}
}核心步骤选择下一个运行的进程pick_next_task
主调度器的触发时机
内核抢占
进程阻塞,主动放弃 CPU
在内核中耗时较长的函数中见缝插针(比如每个循环中)的触发,这会使用到
cond_resched()(其实很像preempt_schedule()):
static inline int should_resched(void)
{
return need_resched() && !(preempt_count() & PREEMPT_ACTIVE);
}
static void __cond_resched(void)
{
add_preempt_count(PREEMPT_ACTIVE);
__schedule();
sub_preempt_count(PREEMPT_ACTIVE);
}
int __sched _cond_resched(void)
{
if (should_resched()) {
__cond_resched();
return 1;
}
return 0;
}与 fork 的交互
每当使用 fork 系统调用或其变体之一建立新进程时,会执行调度器对应的 sched_fork 函数,为进程初始化调度相关信息。在单处理器系统上,该函数实质上执行 3 个操作:
初始化新进程与调度相关的字段
建立数据结构(相当简单直接)
确定进程的动态优先级
// kernel/sched.c
/* * fork()/clone()时的设置: */
void sched_fork(struct task_struct *p, int clone_flags)
{
/* 初始化数据结构 */
...
/** 确认没有将提高的优先级泄漏到子进程 */
// 使用父进程的normal_prio,具体含义见上面讲过的优先级介绍
p->prio = current->normal_prio;
// 如果是非实时进程
if (!rt_prio(p->prio))
// 用完全公平调度器
p->sched_class = &fair_sched_class;
...
}
在使用 wake_up_new_task 唤醒新进程时(上文有提到),则是调度器与进程创建逻辑交互的第二个时机:内核会调用调度类的 task_new 函数。这提供了一个时机,将新进程加入到相应类的就绪队列中。
上下文切换
// kernel/sched/core.c
static inline void
context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
// prepare_task_switch会调用每个体系结构都必须定义的prepare_arch_switch函数
prepare_task_switch(rq, prev, next);
// mm_struct为内存管理上下文结构,主要包括加载页表、刷出地址转换后备缓冲器(部分或全部)、向内存管理单元(MMU)提供新的信息。
mm = next->mm;
oldmm = prev->active_mm;
arch_start_context_switch(prev);
// 内核线程没有自己的用户空间内存上下文,可能在某个随机进程地址空间的上部执行,可见上文。
// 其task_struct->mm为NULL。从当前进程“借来”的地址空间记录在active_mm中:
if (unlikely(!mm))
{// !mm表示mm为空,也就是说是内核线程
// 每次都借上一个用户进程的地址空间,内核线程使用匿名地址空间
next->active_mm = oldmm;
// 增加该内存描述符引用计数
atomic_inc(&oldmm->mm_count);
// 由于内核线程实际并不会使用任何用户进程地址空间
// 所以通知内核无需切换页表。借用只是形式上借用下
enter_lazy_tlb(oldmm, next);
}
else
// 实际切换mm
switch_mm(oldmm, mm, next);
// 如果当前进程是内核线程
if (unlikely(!prev->mm))
{
// 取消对借用的地址空间的借用
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
#ifndef __ARCH_WANT_UNLOCKED_CTXSW
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
#endif
context_tracking_task_switch(prev, next);
/* 这里我们只是切换寄存器状态和栈。注意这里的三个参数,后面介绍 */
switch_to(prev, next, prev);
// switch_to之后的代码只有在当前进程下一次被选择运行时才会执行。
// switch_to返回后,prev将会是最后一次切换前的进程
// barrier语句是一个编译器指令,确保switch_to和finish_task_switch语句的执行顺序不会因为任何可能的优化而改变
barrier();
/*
* finish_task_switch完成一些清理工作,使得能够正确地释放锁,
* this_rq必须重新计算,因为在调用schedule()之后本进程可能已经移动到其他CPU,
* 此时其栈帧上的rq是无效的。
* prev就是实际上一个运行的进程,后面有提到
*/
finish_task_switch(this_rq(), prev);
}用户空间进程的寄存器内容在进入内核态时由硬件自动保存在内核栈上,在上下文切换期间无需显式操作。每个用户进程都是从switch_to后开始执行,此时还处于内核态,所以所有用户进程都是从内核态开始执行的(之后会切换到用户态),在返回用户空间时,会使用内核栈上保存的值自动恢复寄存器数据
switch_to() 的复杂之处:
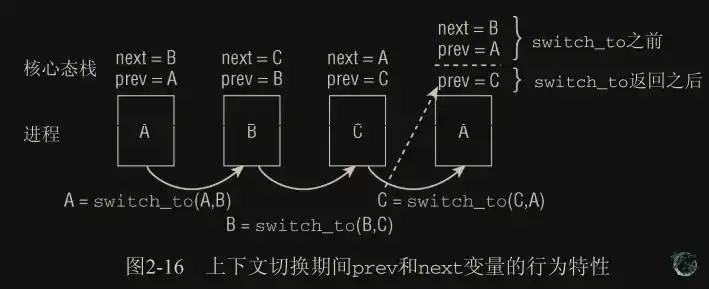
进程 A 切 B,再切 C,最后切 A,A 被恢复执行时,switch_to 返回后,它的栈被恢复,此时它认为的 prev 还是 A,next 还是 B,就是第一次调度时保存下来的栈。在这种情况下,内核无法知道实际上在进程 A 之前运行的是进程 C。因此,在新进程被选中时,底层的进程切换例程必须将此前执行的进程提供给 context_switch。
switch_to 宏实际上执行的代码如下:
prev = switch_to(prev,next)
通过这个方式,内核可以用实际的 switch_to 函数的返回值为恢复的栈提供实际的 prev 值。这个过程依赖底层的体系结构,也就是内核需要有能力控制这两个栈。
惰性 FPU 模式:
上下文切换时一般会把当前进程用到的寄存器压栈,然后从需要执行的进程的栈中恢复寄存器。但浮点计算寄存器(FPU)由于很少使用且每次保存恢复的开销较大,就有了惰性 FPU 模式,也就是上下文切换期间默认不去操作该寄存器(假定新的进程不会去操作该寄存器),直到进程第一次使用该寄存器时将原有的值压入最后一次使用的进程的栈中。
现代 CPU 为 FPU context 切换进行了优化,所以 save/restore 的开销不再是一个问题。
休眠和唤醒
进程休眠肯定是为了等待一些事件,如文件 I/O、等待键盘输入等。
休眠有两种相关的进程状态:TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE
进程休眠时离开就绪队列进入等待队列,如果是 CFS 策略,则从红黑树中移出。
休眠通过等待队列进行,数据结构为进程组成的链表。休眠的实现可能会有竞争条件:condition 为真后进程却进入了休眠,导致永远无法被唤醒。以下实现可以规避该问题:
#define __wait_event(wq, condition) \
do { \
DEFINE_WAIT(__wait); \
\
for (;;) { \
prepare_to_wait(&wq, &__wait, TASK_UNINTERRUPTIBLE); \
if (condition) \
break; \
schedule(); \
} \
finish_wait(&wq, &__wait); \
} while (0)伪唤醒:有时进程被唤醒并不是其等待的条件满足了,而是收到了其他事件被唤醒(比如被信号唤醒,或和其他进程处于同一个等待队列时被同步唤醒),所以每次重新开始执行后需要再次判断条件。
此处的 while 循环和判断条件实际只是为了防止伪唤醒,也就是条件实际并未达成就被唤醒,就继续进入唤醒状态。正常唤醒情况下,条件肯定是满足的,可以简化为:
DEFINE_WAIT(wait); // 将本进程打包为wait_queue_t项
// 假设仅会在条件满足时被wakeup()唤醒
prepare_to_wait(&q, &wait, TASK_UNINTERRUPTIBLE);
if(!condition)
// 非预期错误
finish_wait(&q, &wait);相关的函数:
#define set_mb(var, value) do { var = value; mb(); } while (0)
#define set_current_state(state_value) \
set_mb(current->state, (state_value))
/*
* Note: we use "set_current_state()" _after_ the wait-queue add,
* because we need a memory barrier there on SMP, so that any
* wake-function that tests for the wait-queue being active
* will be guaranteed to see waitqueue addition _or_ subsequent
* tests in this thread will see the wakeup having taken place.
*
* The spin_unlock() itself is semi-permeable and only protects
* one way (it only protects stuff inside the critical region and
* stops them from bleeding out - it would still allow subsequent
* loads to move into the critical region).
*/
void
prepare_to_wait(wait_queue_head_t *q, wait_queue_t *wait, int state)
{
unsigned long flags;
wait->flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags); // 使用该接口使得其可在中断中使用
if (list_empty(&wait->task_list))
__add_wait_queue(q, wait);
// 若未保证原子性可能加入队列之后立即被唤醒(移出队列),
// 然后这步状态却是置为休眠,导致错过唤醒,永远休眠了
set_current_state(state);
spin_unlock_irqrestore(&q->lock, flags);
}
/*
* The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just
* wake everything up. If it's an exclusive wakeup (nr_exclusive == small +ve
* number) then we wake all the non-exclusive tasks and one exclusive task.
*
* There are circumstances in which we can try to wake a task which has already
* started to run but is not in state TASK_RUNNING. try_to_wake_up() returns
* zero in this (rare) case, and we handle it by continuing to scan the queue.
*/
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
/**
* __wake_up - wake up threads blocked on a waitqueue.
* @q: the waitqueue
* @mode: which threads
* @nr_exclusive: how many wake-one or wake-many threads to wake up
* @key: is directly passed to the wakeup function
*
* It may be assumed that this function implies a write memory barrier before
* changing the task state if and only if any tasks are woken up.
*/
void __wake_up(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, void *key)
{
unsigned long flags;
spin_lock_irqsave(&q->lock, flags);
__wake_up_common(q, mode, nr_exclusive, 0, key);
spin_unlock_irqrestore(&q->lock, flags);
}
/**
* try_to_wake_up - wake up a thread
* @p: the thread to be awakened
* @state: the mask of task states that can be woken
* @wake_flags: wake modifier flags (WF_*)
*
* Put it on the run-queue if it's not already there. The "current"
* thread is always on the run-queue (except when the actual
* re-schedule is in progress), and as such you're allowed to do
* the simpler "current->state = TASK_RUNNING" to mark yourself
* runnable without the overhead of this.
*
* Returns %true if @p was woken up, %false if it was already running
* or @state didn't match @p's state.
*/
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
/*
* If we are going to wake up a thread waiting for CONDITION we
* need to ensure that CONDITION=1 done by the caller can not be
* reordered with p->state check below. This pairs with mb() in
* set_current_state() the waiting thread does.
*/
smp_mb__before_spinlock(); // 先设置一个屏障保证之前的赋值操作完成
raw_spin_lock_irqsave(&p->pi_lock, flags);
if (!(p->state & state))
goto out;
success = 1; /* we're going to change ->state */
cpu = task_cpu(p);
/*
* Ensure we load p->on_rq _after_ p->state, otherwise it would
* be possible to, falsely, observe p->on_rq == 0 and get stuck
* in smp_cond_load_acquire() below.
*
* sched_ttwu_pending() try_to_wake_up()
* [S] p->on_rq = 1; [L] P->state
* UNLOCK rq->lock -----.
* \
* +--- RMB
* schedule() /
* LOCK rq->lock -----'
* UNLOCK rq->lock
*
* [task p]
* [S] p->state = UNINTERRUPTIBLE [L] p->on_rq
*
* Pairs with the UNLOCK+LOCK on rq->lock from the
* last wakeup of our task and the schedule that got our task
* current.
*/
smp_rmb();
if (p->on_rq && ttwu_remote(p, wake_flags))
goto stat;
// (以下省略)
}其中竞争条件(condition 的赋值和 condition 的读取顺序)的处理使用屏障的方式:
CPU 1 CPU 2
=============================== ===============================
// prepare_to_wait 内部实现 STORE event_indicated
set_current_state(); // wake_up 的实现
set_mb(); wake_up();
// 进程进入休眠态 <write barrier> // 写屏障,保证event_indicated已经写成功
STORE current->state STORE current->state // 进程进入就绪态
<general barrier> // 读写屏障,保证 event_indicated 的读取在写 state 后(等唤醒后执行)
LOAD event_indicated通过 prepare_to_wait 内部(set_current_state)封装的一个读写屏障和 wake_up 内部封装的一个写屏障(可能和上面的内核代码不对应,但这是核心思想),保证了 CPU2 对 event_indicated 的修改一定在唤醒进程(修改state)前,且 CPU1 对 event_indicated 的读取一定在休眠之后(这点主要还是为了防止伪唤醒)。
唤醒操作可通过函数 wake_up()进行,它会唤醒指定的等待队列上的所有进程。它调用函数 try_to_wake_up(),该函数负责将进程设置为 TASK_RUNNING 状态。如果是 CFS 队列进程,还会调用 enqueue_task() 将此进程放入红黑树中。
内核代码实例:
static ssize_t inotify_read(struct file *file, char __user *buf,
size_t count, loff_t *pos)
{
struct fsnotify_group *group;
struct fsnotify_event *kevent;
char __user *start;
int ret;
DEFINE_WAIT(wait);
start = buf;
group = file->private_data;
while (1) {
prepare_to_wait(&group->notification_waitq, &wait, TASK_INTERRUPTIBLE);
mutex_lock(&group->notification_mutex);
kevent = get_one_event(group, count);
mutex_unlock(&group->notification_mutex);
pr_debug("%s: group=%p kevent=%p\n", __func__, group, kevent);
if (kevent) {
ret = PTR_ERR(kevent);
if (IS_ERR(kevent))
break;
ret = copy_event_to_user(group, kevent, buf);
fsnotify_put_event(kevent);
if (ret < 0)
break;
buf += ret;
count -= ret;
continue;
}
ret = -EAGAIN;
if (file->f_flags & O_NONBLOCK)
break;
ret = -ERESTARTSYS;
if (signal_pending(current))
break;
if (start != buf)
break;
schedule();
}
finish_wait(&group->notification_waitq, &wait);
if (start != buf && ret != -EFAULT)
ret = buf - start;
return ret;
}完全公平调度类(CFS)
Completely Fair Scheduler(CFS)结构中是一系列的函数指针:
`(fair) = {
.enqueue_task = enqueue_task_fair, ///把进程添加紧rq
.dequeue_task = dequeue_task_fair, ///把进程移除rq
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup, ///检查是否需要抢占当前进程
.pick_next_task = __pick_next_task_fair, ///从就绪队列选择一个最有进程来运行
.put_prev_task = put_prev_task_fair, ///把prev进程重新添加到就绪队列中
.set_next_task = set_next_task_fair, ///修改policy或group
#ifdef CONFIG_SMP
.balance = balance_fair,
.pick_task = pick_task_fair,
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair, ///用于迁移进程到一个新的rq
.rq_online = rq_online_fair, ///设置rq状态为online
.rq_offline = rq_offline_fair, ///关闭就绪队列
.task_dead = task_dead_fair, ///处理已终止的基层你
.set_cpus_allowed = set_cpus_allowed_common, ///设置CPU可运行CPU范围
#endif
.task_tick = task_tick_fair, ///处理时钟节拍
.task_fork = task_fork_fair, ///处理新进程与调度相关的一些初始化信息
.prio_changed = prio_changed_fair, ///改变进程优先级
.switched_from = switched_from_fair, ///切换调度类
.switched_to = switched_to_fair, ///切换到下一个进程运行
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair, ///更新fq的运行时间,CFS更新虚拟时间
#ifdef CONFIG_FAIR_GROUP_SCHED
.task_change_group = task_change_group_fair,
#endif
#ifdef CONFIG_UCLAMP_TASK
.uclamp_enabled = 1,
#endif
}
主调度器的每个就绪队列中都嵌入了一个该 cfs_rq 结构的实例(每个 CPU 一个就绪队列)
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load; ///就绪队列里所有调度实体权重之和
unsigned int nr_running; ///就绪队列中调度实体个数
unsigned int h_nr_running; /* SCHED_{NORMAL,BATCH,IDLE} */
unsigned int idle_h_nr_running; /* SCHED_IDLE */
u64 exec_clock; ///就绪队列总运行时间
///就绪队列中最小的虚拟运行时间,红黑树的最小vruntime值
u64 min_vruntime;
#ifdef CONFIG_SCHED_CORE
unsigned int forceidle_seq;
u64 min_vruntime_fi;
#endif
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root_cached tasks_timeline; ///红黑树的根,跟踪红黑树信息,缓存最小节点和根节点
/*
* 'curr' points to currently running entity on this cfs_rq.
* It is set to NULL otherwise (i.e when none are currently running).
*/
struct sched_entity *curr; ///指向当前正在运行进程
struct sched_entity *next; ///切换即将运行的下一个进程
struct sched_entity *last; ///抢占内核时,唤醒进程抢占了当前进程,last指向当前进程
struct sched_entity *skip;
#ifdef CONFIG_SCHED_DEBUG
unsigned int nr_spread_over;
#endif
#ifdef CONFIG_SMP
/*
* CFS load tracking
*/
struct sched_avg avg; ///用于PELT算法的负载计算
#ifndef CONFIG_64BIT
u64 load_last_update_time_copy;
#endif
struct {
raw_spinlock_t lock ____cacheline_aligned;
int nr;
unsigned long load_avg;
unsigned long util_avg;
unsigned long runnable_avg;
} removed;
#ifdef CONFIG_FAIR_GROUP_SCHED
unsigned long tg_load_avg_contrib;
long propagate;
long prop_runnable_sum;
/*
* h_load = weight * f(tg)
*
* Where f(tg) is the recursive weight fraction assigned to
* this group.
*/
unsigned long h_load;
u64 last_h_load_update;
struct sched_entity *h_load_next;
#endif /* CONFIG_FAIR_GROUP_SCHED */
#endif /* CONFIG_SMP */
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /* CPU runqueue to which this cfs_rq is attached */
/*
* leaf cfs_rqs are those that hold tasks (lowest schedulable entity in
* a hierarchy). Non-leaf lrqs hold other higher schedulable entities
* (like users, containers etc.)
*
* leaf_cfs_rq_list ties together list of leaf cfs_rq's in a CPU.
* This list is used during load balance.
*/
int on_list;
struct list_head leaf_cfs_rq_list;
struct task_group *tg; /* group that "owns" this runqueue */
/* Locally cached copy of our task_group's idle value */
int idle;
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
s64 runtime_remaining;
u64 throttled_clock;
u64 throttled_clock_task;
u64 throttled_clock_task_time;
int throttled;
int throttle_count;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};虚拟运行时间vruntime
关于为什么需要一个虚拟运行时间来描述进程:假设我们直接使用实际运行时间,也就是绝对物理时间,现实世界的 1 秒就是 1 秒,在调度进程时,我们可以选择实际运行时间最短的进程运行,来保证公平性。但是要怎么实现优先级的概念?如何知道拥有了优先级后的进程的饥饿情况?最终我们肯定需要通过优先级(或者权重)和实际运行时间进行换算得到进程的饥饿情况,也就有了虚拟运行时间的概念,这样调度进程时直接调度虚拟运行时间最短的进程就行(其实也可以称为相对运行时间。关于为什么需要一个变量单独保存就是为了空间换时间,虚拟运行时间可以通过权重和实际运行时间换算,只不过每次使用都换算一遍太浪费性能,能一次算完用一个变量保存最好,同时用作红黑树键值进行管理也更方便)。
所有与虚拟时钟有关的计算都在 update_curr 中执行,该函数在系统中各个不同地方调用,包括周期性调度器之内。
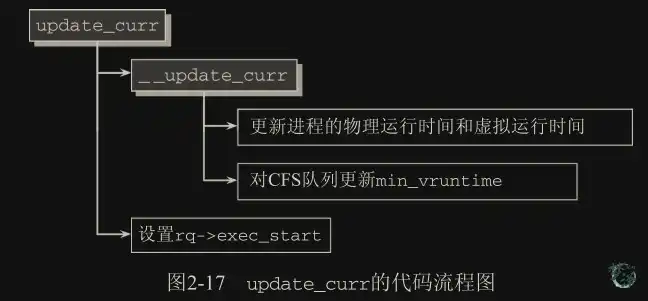
update_curr()实现了 CFS 策略所需信息(进程所占用的虚拟运行时间)的统计:
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
///rq_clock_task在每个时钟节拍都会被更新
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
delta_exec = now - curr->exec_start; ///上次调用以来的时间差
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
///更新累计实际运行时间
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
///计算,更新虚拟时间
curr->vruntime += calc_delta_fair(delta_exec, curr);
///更新cfs_rq最小vruntime
update_min_vruntime(cfs_rq);
///更新组统计信息
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
//trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
trace_sched_stat_my_runtime(curtask,cfs_rq->min_vruntime);
cgroup_account_cputime(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}此操作并不会更新红黑树,因为正在运行的进程并不在红黑树中,在其运行前就已经被移出红黑树了,所以仅更新该进程的统计量 vruntime 不影响红黑树的排序
虚拟运行时间计算
calc_delta_fair() 函数作用是根据物理运行时间计算虚拟运行时间,公式如下:
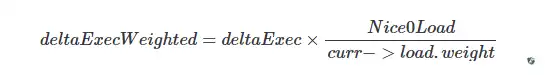
负荷权重 weight 的计算方式见计算负荷权重,权重和优先级值成反比(和优先级成正比),权重 weight越大,进程的虚拟运行时间 vruntime越小(也就是走的越慢),这样就能占用更多的物理 CPU 时间(优先级越高)。
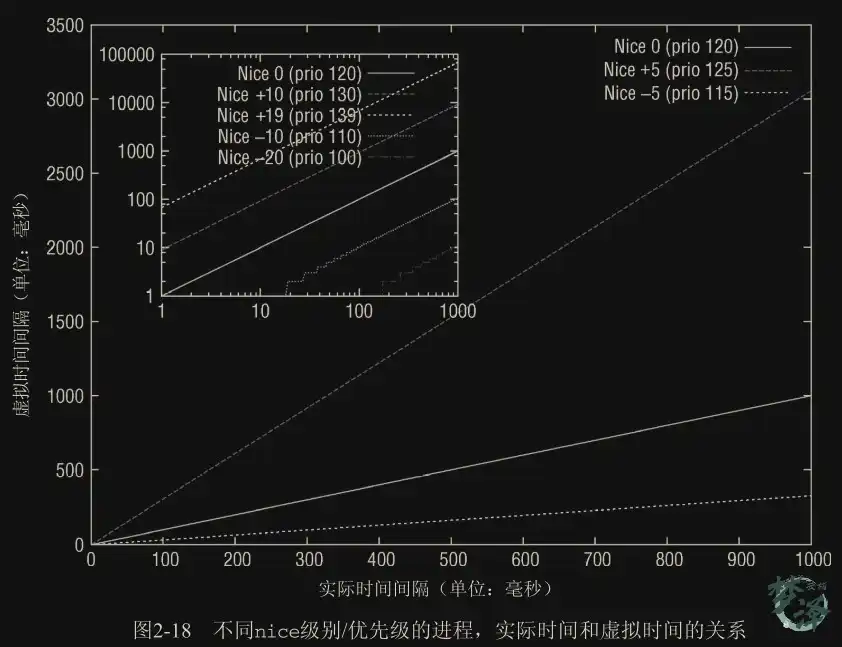
红黑树
完全公平调度器类(CFS)使用红黑树来组织可运行进程队列。排序依据(键值)为 vruntime。键值较小的结点,排序位置就更靠左,因此会被更快地调度。用这种方法,内核实现了下面两种对立的机制:
在进程运行时,其
vruntime稳定地增加,它在红黑树中总是向右移动的。 因为越重要的进程 vruntime 增加越慢,因此它们向右移动的速度也越慢,这样其被调度的机会要大于次要进程,这刚好是我们需要的。如果进程进入睡眠,则其
vruntime保持不变。因为每个队列min_vruntime同时会增加(根据上面的代码,它是单调递增的),那么睡眠进程醒来后,在红黑树中的位置会更靠左,因为其键值变得更小了。
查找树中最左边的节点,也就是键值最小的节点,表示最应该被调度的进程实体:
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)
{
struct rb_node *left = cfs_rq->rb_leftmost;
if (!left)
return NULL;
return rb_entry(left, struct sched_entity, run_node);
}向树中加入一个节点,也就是进程加入就绪队列(发生在进程变为可运行状态(被唤醒)或者是通过fork()调用第一次创建进程时):
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Update the normalized vruntime before updating min_vruntime
* through callig update_curr().
*/
// 如果是新创建的进程(不是被唤醒WAKEUP的进程)
if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))
/*
* cfs_rq->min_vruntime可以表示当前队列已运行的虚拟运行时间,
* 后续新加入的进程在该时间的基础上运行,也就是vruntime需要加上
* 这个已经经过的虚拟时间。
*
* 否则该进程的vruntime可能就以0开始,这对其他已经在队列中的进程不公平
*/
se->vruntime += cfs_rq->min_vruntime;
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
enqueue_entity_load_avg(cfs_rq, se, flags & ENQUEUE_WAKEUP);
account_entity_enqueue(cfs_rq, se);
update_cfs_shares(cfs_rq);
if (flags & ENQUEUE_WAKEUP) {
place_entity(cfs_rq, se, 0);
enqueue_sleeper(cfs_rq, se);
}
update_stats_enqueue(cfs_rq, se);
check_spread(cfs_rq, se);
if (se != cfs_rq->curr)
// 把一个调度实体插入红黑树中
__enqueue_entity(cfs_rq, se);
se->on_rq = 1;
if (cfs_rq->nr_running == 1) {
list_add_leaf_cfs_rq(cfs_rq);
check_enqueue_throttle(cfs_rq);
}
}static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
// 获取树的根节点
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
int leftmost = 1;
/*
* Find the right place in the rbtree:
*/
// 从根开始遍历红黑树节点
while (*link) {
parent = *link;
// 获取节点对象(sched_entity对象)
entry = rb_entry(parent, struct sched_entity, run_node);
/*
* We dont care about collisions. Nodes with
* the same key stay together.
*/
// 如果新节点在该节点的左边(key值小于该节点)
if (entity_before(se, entry)) {
// 遍历左子树
link = &parent->rb_left;
} else {
// 遍历右子树
link = &parent->rb_right;
// 因为一旦开始遍历右子树,表示新节点已经不可能是树中最左边的节点了,
// 我们将leftmost标志置为0
leftmost = 0;
}
}
/*
* Maintain a cache of leftmost tree entries (it is frequently
* used):
*/
// 如果新节点为最左节点,那可以直接缓存它,以后获取树的最左子节点直接用这个缓存
if (leftmost)
cfs_rq->rb_leftmost = &se->run_node;
rb_link_node(&se->run_node, parent, link);
// 树的自平衡(红黑着色)操作
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
}当进程切换时,schedule()会调用deactivate_task()将当前进程从对应的调度器类(比如这里是 CFS)的队列中移除(这里就是从红黑树中删除节点)
延迟跟踪
上面的虚拟运行时间保证的进程分到的 CPU 时间的公平性,但不能保证进程的执行间隔(及时性),可能分到了 10ms,但是执行时一次执行了 10ms,后面的 1s 都没有执行机会,对用户来说就是无响应状态。所以需要细分一个执行周期,保证周期内所有进程都至少执行一次,哪怕执行的时间很短,也能保证及时性。但是也不能过于频繁的切换进程,这会影响效率,后续会提到通过 sysctl_sched_wakeup_granularity 来限制进程切换速度。
通过延迟跟踪来保证进程执行的及时性:
sysctl_sched_latency:延迟周期。保证每个可运行的进程都应该至少运行一次的某个时间间隔。可通过/proc/sys/kernel/sched_latency_ns控制,默认值为 20000000 纳秒或 20 毫秒。这个时间是物理运行时间sched_nr_latency:控制在一个延迟周期中处理的最大活动进程数目。如果活动进程的数目超出该上限,则延迟周期也成比例地线性扩展。
通过考虑各个进程的相对权重,将一个延迟周期的时间在活动进程之间进行分配。
对于由某个可调度实体表示的给定进程,一个延迟周期内分配到的物理运行时间如下计算:
// kernel/sched_fair.c
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
// __sched_period用于计算sysctl_sched_latency,也就是延迟周期
u64 slice = __sched_period(cfs_rq->nr_running);
// 计算物理运行时间比重,进程的负荷权重先乘以延迟周期,再除以总负荷权重。计算得到占用延迟周期内物理运行时间
slice *= se->load.weight;
do_div(slice, cfs_rq->load.weight);
return slice;
}队列操作
进程加入就绪队列
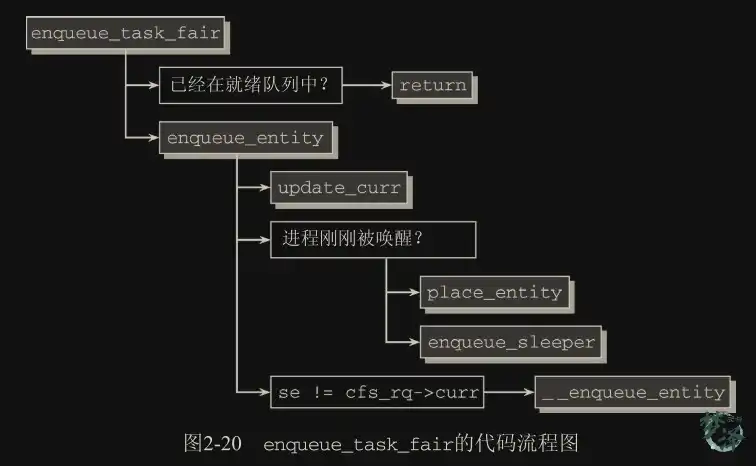
用于被唤醒的进程和新创建的进程,通过参数 wakeup 标识。
如果进程此前在睡眠,那么在 place_entity 中首先会调整进程的虚拟运行时间(新进程的加入会导致队列的总权重上升,让其中原有的每个进程权重的占比略微降低,也就是会降低每个进程在一个延迟周期内的运行时间,为了不干扰本轮延迟周期,本函数会进行一些操作修正 vruntime):
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
///新建进程,vruntime进行惩罚,vruntime增加一个调度周期的时长,设定为刚执行完一个时间片
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
///唤醒睡眠进程,做一定补偿,默认补偿半个调度周期
/* sleeps up to a single latency don't count. */
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* 如果GENTLE_FAIR_SLEEPERS标志置位,表示启用
* 限制睡眠线程的补偿时间为sysctl_sched_latency的50%,
* 可以减少其他任务的调度延迟,该功能内核默认打开。
* 否则按延迟周期100%补偿该进程因休眠损失的CPU时间。
* 老版本的内核没有该特性,都是100%补偿的。
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
/*
* 在当前周期补偿该进程因休眠损失的CPU时间,
* 通过这样让cfs_rq->min_vruntime减去sysctl_sched_latency周期,
* vruntime就落后于当前队列运行时间,直到其运行时间达到cfs_rq->min_vruntime,
* 才能消除该补偿。
*/
vruntime -= thresh;
}
/* ensure we never gain time by being placed backwards. */
// 确保se->vruntime不会小于vruntime,让该进程适用place_entity的修正,
// 当然,如果se->vruntime本身就大于vruntime说明该进程之前已经占用了过量的CPU时间,不需要修正,无需操作
se->vruntime = max_vruntime(se->vruntime, vruntime);
}之后通过__enqueue_entity将该修正 vruntime 后的节点加入红黑树中。
选择下一个进程
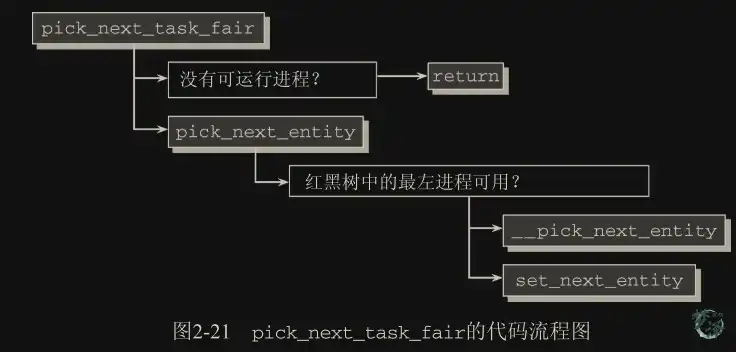
红黑树只包含就绪且未在实际运行中的进程,进程运行前需要从红黑树中去除。
///获取红黑树最左边的进程
struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
///根cfs就绪队列
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
int new_tasks;
again:
if (!sched_fair_runnable(rq))
goto idle;
///组调度
#ifdef CONFIG_FAIR_GROUP_SCHED
if (!prev || prev->sched_class != &fair_sched_class)
goto simple;
/*
* Because of the set_next_buddy() in dequeue_task_fair() it is rather
* likely that a next task is from the same cgroup as the current.
*
* Therefore attempt to avoid putting and setting the entire cgroup
* hierarchy, only change the part that actually changes.
*/
do {
struct sched_entity *curr = cfs_rq->curr;
/*
* Since we got here without doing put_prev_entity() we also
* have to consider cfs_rq->curr. If it is still a runnable
* entity, update_curr() will update its vruntime, otherwise
* forget we've ever seen it.
*/
if (curr) {
if (curr->on_rq)
update_curr(cfs_rq);
else
curr = NULL;
/*
* This call to check_cfs_rq_runtime() will do the
* throttle and dequeue its entity in the parent(s).
* Therefore the nr_running test will indeed
* be correct.
*/
if (unlikely(check_cfs_rq_runtime(cfs_rq))) {
cfs_rq = &rq->cfs;
if (!cfs_rq->nr_running)
goto idle;
goto simple;
}
}
///从就绪队列选择最优先se
se = pick_next_entity(cfs_rq, curr);
///如果时task se,那么cfs_rq=NULL
///如果是group se,cfs_rq=组se对应的cfs_rq
///如果是group se,继续从group的cfs_rq中选择下一个最优先的se,循环执行,直到找到最底层task se
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
/*
* Since we haven't yet done put_prev_entity and if the selected task
* is a different task than we started out with, try and touch the
* least amount of cfs_rqs.
*/
if (prev != p) {
struct sched_entity *pse = &prev->se;
while (!(cfs_rq = is_same_group(se, pse))) {
int se_depth = se->depth;
int pse_depth = pse->depth;
if (se_depth <= pse_depth) {
put_prev_entity(cfs_rq_of(pse), pse);
pse = parent_entity(pse);
}
if (se_depth >= pse_depth) {
set_next_entity(cfs_rq_of(se), se);
se = parent_entity(se);
}
}
put_prev_entity(cfs_rq, pse);
set_next_entity(cfs_rq, se);
}
goto done;
simple:
#endif
if (prev)
put_prev_task(rq, prev);
do {
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
done: __maybe_unused;
#ifdef CONFIG_SMP
/*
* Move the next running task to the front of
* the list, so our cfs_tasks list becomes MRU
* one.
*/
list_move(&p->se.group_node, &rq->cfs_tasks);
#endif
if (hrtick_enabled_fair(rq))
hrtick_start_fair(rq, p);
update_misfit_status(p, rq);
return p;
idle:
if (!rf)
return NULL;
new_tasks = newidle_balance(rq, rf);
/*
* Because newidle_balance() releases (and re-acquires) rq->lock, it is
* possible for any higher priority task to appear. In that case we
* must re-start the pick_next_entity() loop.
*/
if (new_tasks < 0)
return RETRY_TASK;
if (new_tasks > 0)
goto again;
/*
* rq is about to be idle, check if we need to update the
* lost_idle_time of clock_pelt
*/
update_idle_rq_clock_pelt(rq);
return NULL;
}CFS 周期性调度函数
该函数是周期性调度器使用的钩子函数.task_tick = task_tick_fair中的一部分
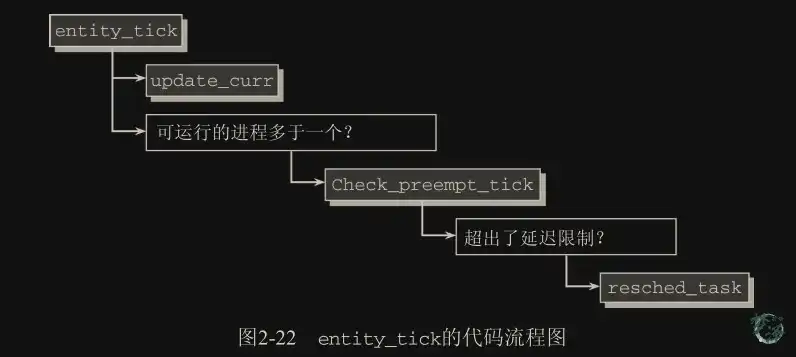
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
/* 如果开启组机制,还需要遍历上一级调度实体;依次往上遍历所有父se
* 只要有一个se超过分配限额时间,就需要重新调度
*
* 否则就处理本se
*/
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
///检查是否需要调度
entity_tick(cfs_rq, se, queued);
}
if (static_branch_unlikely(&sched_numa_balancing))
task_tick_numa(rq, curr);
update_misfit_status(curr, rq);
update_overutilized_status(task_rq(curr));
task_tick_core(rq, curr);
}
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the 'current'.
*/
///更新当前进程vruntime和就绪队列的min_vruntime
update_curr(cfs_rq);
/*
* Ensure that runnable average is periodically updated.
*/
///更新当前进程实体和就绪队列rq的负载
update_load_avg(cfs_rq, curr, UPDATE_TG);
///更新group负载
update_cfs_group(curr);
#ifdef CONFIG_SCHED_HRTICK
/*
* queued ticks are scheduled to match the slice, so don't bother
* validating it and just reschedule.
*/
if (queued) {
resched_curr(rq_of(cfs_rq));
return;
}
/*
* don't let the period tick interfere with the hrtick preemption
*/
if (!sched_feat(DOUBLE_TICK) &&
hrtimer_active(&rq_of(cfs_rq)->hrtick_timer))
return;
#endif
if (cfs_rq->nr_running > 1)
///检查当前是否需要调度
check_preempt_tick(cfs_rq, curr);
}nr_running=1 时表示可运行进程就 1 个,有两种情况:
正在运行的进程 1 个,就绪队列为空
正在运行的进程 0 个,就绪队列中有 1 个进程
以上两种情况都无需做任何操作,因为本函数的目的是进行进程的切换,只有一个无法实现切换。
如果进程数目大于等于两个,则由 check_preempt_tick 作出决策:
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
///理论运行时间
ideal_runtime = sched_slice(cfs_rq, curr);
///实际运行时间
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
///实际运行时间>理论运行时间,时间片用完,需要调度
if (delta_exec > ideal_runtime) {
///设置调度标记TIF_NEED_RESCHED
resched_curr(rq_of(cfs_rq));
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* Ensure that a task that missed wakeup preemption by a
* narrow margin doesn't have to wait for a full slice.
* This also mitigates buddy induced latencies under load.
*/
///实际运行小于sysctl_sched_min_granularity默认0.75ms,不调度
if (delta_exec < sysctl_sched_min_granularity)
return;
se = __pick_first_entity(cfs_rq);
///虚拟时间和红黑树最左树时间比较,仍然最小,不调度
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}这会在 task_struct 中设置 TIF_NEED_RESCHED 标志,主调度器会在下一个适当时机发起重调度。
唤醒抢占
当在 try_to_wake_up 和 wake_up_new_task 中唤醒进程时,内核使用 check_preempt_curr 看看是否新进程可以抢占当前运行的进程。
内核会根据当前正在运行的进程所属的调度器类定义的钩子函数 check_preempt_curr,完全公平调度器类 fair_sched_class 中的 check_preempt_curr 指向 check_preempt_wakeup 函数:
// kernel/sched_fair.c
// p为刚唤醒的进程
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p)
{
struct task_struct *curr = rq->curr;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
// 当前进程的sched_entity
struct sched_entity *se = &curr->se, *pse = &p->se;
unsigned long gran;
// 刚唤醒的进程是否是实时进程,(除了此处与实时进程有关联外,其他地方都没有)
if (unlikely(rt_prio(p->prio)))
{
// 让当前的普通进程(非实时进程都使用完全公平调度器类)停止运行
update_rq_clock(rq);
update_curr(cfs_rq);
resched_task(curr);
// 直接 return 无需后续步骤
return;
}
...
// 如果是SCHED_BATCH进程,根据定义它们不抢占其他进程
if (unlikely(p->policy == SCHED_BATCH))
return;
...
// 当运行进程被新进程(非上面已判断的进程类型)抢占时,
// 内核确保被抢占者至少已经运行了某一最小时间限额sysctl_sched_wakeup_granularity(注意是虚拟运行时间)。
// sysctl_sched_wakeup_granularity一般为4ms,防止过于频繁的抢占产生大量上下文切换
gran = sysctl_sched_wakeup_granularity;
if (unlikely(se->load.weight != NICE_0_LOAD))
// 根据物理运行时间计算虚拟运行时间
gran = calc_delta_fair(gran, &se->load);
...
if (pse->vruntime + gran < se->vruntime)
// TIF_NEED_RESCHED置位
resched_task(curr);
}处理新进程
创建新进程fork()时调用的挂钩函数:task_fork_fair。该函数的行为可使用参数 sysctl_sched_child_runs_first 控制(默认为 1,也就是默认启用)。顾名思义,该参数用于判断新建子进程是否应该在父进程之前运行。
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
struct rq *rq = this_rq();
struct rq_flags rf;
rq_lock(rq, &rf);
update_rq_clock(rq);
///获取当前进程所在的CFS就绪队列cfs_rq
cfs_rq = task_cfs_rq(current);
curr = cfs_rq->curr;
if (curr) {
///更新当前正在运行的调度实体的运行时间
update_curr(cfs_rq);
///初始化当前创建的新进程的虚拟时间
se->vruntime = curr->vruntime;
}
///新建进程,对虚拟时间进行惩罚,防止新进程恶意抢占CPU
place_entity(cfs_rq, se, 1);
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {
/*
* Upon rescheduling, sched_class::put_prev_task() will place
* 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
}
///加入就绪队列时,会重新计算vruntime
se->vruntime -= cfs_rq->min_vruntime;
rq_unlock(rq, &rf);
}实时调度类(RT)
按照 POSIX 标准的强制要求,除了“普通”进程之外,Linux 还支持两种实时调度器类。相应的,普通的非实时调度策略是SCHED_NORMAL
性质
实时进程与普通进程有一个根本的不同之处:如果系统中有一个实时进程且可运行,那么调度器总是会选中它运行,除非有另一个优先级更高的实时进程。
两种实时类:
循环进程(SCHED_RR):有时间片,其值在进程运行时会减少,就像是普通进程。在所有的时间段都到期后,则该值重置为初始值,而进程则置于队列的末尾。这确保了在有几个优先级相同的 SCHED_RR 进程的情况下,它们总是依次执行。
先进先出进程(SCHED_FIFO):没有时间片,在被调度器选择执行后,可以运行任意长时间。 很明显,如果实时进程编写得比较差,系统可能变得无法使用。只要写一个无限循环,循环体内不进入睡眠,其他进程就别想运行了。在编写实时应用程序时,应该多加小心。
实时调度器类定义:
DEFINE_SCHED_CLASS(rt) = {
.enqueue_task = enqueue_task_rt,
.dequeue_task = dequeue_task_rt,
.yield_task = yield_task_rt,
.check_preempt_curr = check_preempt_curr_rt,
.pick_next_task = pick_next_task_rt,
.put_prev_task = put_prev_task_rt,
.set_next_task = set_next_task_rt,
#ifdef CONFIG_SMP
.balance = balance_rt,
.pick_task = pick_task_rt,
.select_task_rq = select_task_rq_rt,
.set_cpus_allowed = set_cpus_allowed_common,
.rq_online = rq_online_rt,
.rq_offline = rq_offline_rt,
.task_woken = task_woken_rt,
.switched_from = switched_from_rt,
.find_lock_rq = find_lock_lowest_rq,
#endif
.task_tick = task_tick_rt,
.get_rr_interval = get_rr_interval_rt,
.prio_changed = prio_changed_rt,
.switched_to = switched_to_rt,
.update_curr = update_curr_rt,
#ifdef CONFIG_UCLAMP_TASK
.uclamp_enabled = 1,
#endif
};就绪队列数据结构
struct rt_prio_array {
DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit for delimiter */
struct list_head queue[MAX_RT_PRIO];
};
struct rt_rq {
struct rt_prio_array active;
unsigned int rt_nr_running;
unsigned int rr_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */
#ifdef CONFIG_SMP
int next; /* next highest */
#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned int rt_nr_migratory;
unsigned int rt_nr_total;
int overloaded;
struct plist_head pushable_tasks;
#endif /* CONFIG_SMP */
int rt_queued;
int rt_throttled;
u64 rt_time;
u64 rt_runtime;
/* Nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned int rt_nr_boosted;
struct rq *rq;
struct task_group *tg;
#endif
};具有相同优先级的所有实时进程都保存在一个链表中,表头为 active.queue[prio],
active.bitmap 位图中的每个比特位对应于一个链表,凡包含了进程的链表,对应的比特位则置位。如果链表中没有进程,则对应的比特位不置位。(用于快速判断对应链表是否为空)
亮点:链表与位图的组合,很适合优先级相关应用,此处用于快速判断有效的最高优先级链表
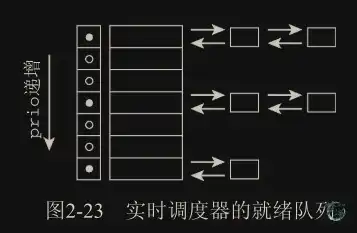
调度器类操作
插入新进程
通过优先级作为 index 可获取对应链表,新进程总是排列在每个链表的末尾。
选择下一个执行的进程

static struct sched_rt_entity *pick_next_rt_entity(struct rq *rq,
struct rt_rq *rt_rq)
{
struct rt_prio_array *array = &rt_rq->active;
struct sched_rt_entity *next = NULL;
struct list_head *queue;
int idx;
idx = sched_find_first_bit(array->bitmap);
BUG_ON(idx >= MAX_RT_PRIO);
queue = array->queue + idx;
next = list_entry(queue->next, struct sched_rt_entity, run_list);
return next;
}
static struct task_struct *_pick_next_task_rt(struct rq *rq)
{
struct sched_rt_entity *rt_se;
struct rt_rq *rt_rq = &rq->rt;
do {
rt_se = pick_next_rt_entity(rq, rt_rq);
BUG_ON(!rt_se);
rt_rq = group_rt_rq(rt_se);
} while (rt_rq);
return rt_task_of(rt_se);
}
static struct task_struct *pick_task_rt(struct rq *rq)
{
struct task_struct *p;
if (!sched_rt_runnable(rq))
return NULL;
p = _pick_next_task_rt(rq);
return p;
}
static struct task_struct *pick_next_task_rt(struct rq *rq)
{
struct task_struct *p = pick_task_rt(rq);
if (p)
set_next_task_rt(rq, p, true);
return p;
}与调度相关的系统调用
Linux提供了一系列和进程调度有关的系统调用,用于执行进程优先级、调度策略、处理器绑定、让出CPU等操作:
CPU 亲和力:Linux 调度程序提供强制的处理器绑定(processor affinity)机制,称为进程的 CPU 亲和力,保存在进程 task_struct 的 cpus_allowed 这个位掩码标志中。该掩码标志的每一位对应一个系统可用的处理器。默认情况下,所有的位都被设置,进程可以在系统中所有可用的处理器上执行。
调度器增强
SMP 调度
为了高效利用 CPU,内核需要支持以下功能:
CPU 负载均衡,不要出现 1 核有难,7 核围观。
CPU 亲和性设置,例如在 4 个 CPU 系统中,可以将计算密集型应用程序绑定到前 3 个 CPU,而剩余的(交互式)进程则在第 4 个 CPU 上运行。
进程能在 CPU 间移动,但要考虑高速缓存切换和内存移动带来的代价。
数据结构:
// kernel/sched/sched.h
struct rq {
...
#ifdef CONFIG_SMP
struct root_domain *rd;
struct sched_domain *sd;
unsigned long cpu_power;
unsigned char idle_balance;
/* For active balancing */
int post_schedule;
int active_balance;
int push_cpu;
struct cpu_stop_work active_balance_work;
/* cpu of this runqueue: */
int cpu;
int online;
struct list_head cfs_tasks;
u64 rt_avg;
u64 age_stamp;
u64 idle_stamp;
u64 avg_idle;
#endif
...
};和 SMP 调度相关的变量部分在就绪队列结构 rq 中
负载均衡流程
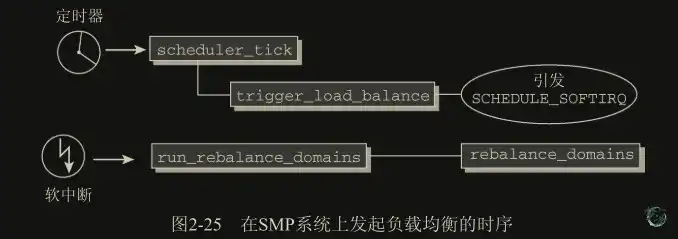
在周期性调度器中,会触发trigger_load_balance(),并使用软中断SCHED_SOFTIRQ来延后执行负载均衡:
void trigger_load_balance(struct rq *rq)
{
/*
* Don't need to rebalance while attached to NULL domain or
* runqueue CPU is not active
*/
if (unlikely(on_null_domain(rq) || !cpu_active(cpu_of(rq))))
return;
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);
nohz_balancer_kick(rq);
}软中断SCHED_SOFTIRQ绑定的中断处理程序为run_rebalance_domains():
static __latent_entropy void run_rebalance_domains(struct softirq_action *h)
{
struct rq *this_rq = this_rq();
enum cpu_idle_type idle = this_rq->idle_balance ?
CPU_IDLE : CPU_NOT_IDLE;
/*
* If this CPU has a pending nohz_balance_kick, then do the
* balancing on behalf of the other idle CPUs whose ticks are
* stopped. Do nohz_idle_balance *before* rebalance_domains to
* give the idle CPUs a chance to load balance. Else we may
* load balance only within the local sched_domain hierarchy
* and abort nohz_idle_balance altogether if we pull some load.
*/
if (nohz_idle_balance(this_rq, idle))
return;
/* normal load balance */
update_blocked_averages(this_rq->cpu);
rebalance_domains(this_rq, idle);
}
CPU 较多的情况下可以选择将物理上相邻的 CPU 的就绪队列组织为调度域(scheduling domain),从而划分为多个调度域,在同一调度域间搬迁进程消耗较少。不过一般非大型的系统上用不上该特性,所有 CPU 都在一个调度域内。
对于rebalance_domains()的具体调度算法,这里不再展开。
抢占
用户抢占
内核即将返回用户空间时,如果need_reched被设置,会导致调度器被调用,以选择一个更加合适的进程来运行。
从中断处理程序或者系统调用的返回路径依赖于体系结构,这些代码包含在entry.S文件中,该文件包含内核入口、退出的代码。
用户抢占的发生时机包括:
中断处理程序返回用户空间时
系统调用返回用户空间时
内核抢占
对于不支持内核抢占的OS,内核代码会一直运行直到它完成(返回用户空间或者明确阻塞)为止,内核没有办法在这种代码运行期间执行调度——内核中的任务是以协作方式调度的,不具有抢占性。
从2.6+开始,只要重新调度是安全的,内核就可以被抢占。当正运行在内核中的进程不持有锁(这里的锁被作为非抢占区域的标记),重新调度就是安全的。由于内核是SMP安全的,因此在不持有锁的情况下,当前代码是可重入的(reentrant,即多个进程可以同时执行,对于单处理器系统不存在重入问题)并且可以被抢占。
为支持内核抢占,进程的 thread_info 引入了 preempt_count 计数器,初值为0,每当使用锁的时候,计数增加,释放锁的时候则计数减小,因此preempt_count 为0时内核就可以被抢占。
当从中断返回内核空间时,内核会检查need_resched和preempt_count,如果need_resched被设置并且preempt_count为0,意味着有一个更加重要的任务可以安全的运行,因此会发生调度。
当进程所有的锁都被释放时,解锁代码负责检查need_resched是否被设置,如果是,调度也会发生。
某些内核代码需要允许或者禁止内核抢占。
如果内核代码被阻塞,或者显式的调用了 schedule() 则内核抢占也会发生,这种形式的内核抢占一直都支持。
内核抢占的实现
在 task_struct 的 thread_info 结构中,有一个抢占计数器 preempt_count:
// <asm-arch/thread_info.h>
struct thread_info {
...
int preempt_count; /* 0 => 可抢占,>0 => 不可抢占, <0 => BUG */
...
}
preempt_count 确定了内核当前是否处于一个可以被抢占的位置。如果 preempt_count 为零,则内核可以被抢占,否则不行。比如处于临界区时内核是不希望自己被抢占的,可以通过preempt_disable暂时停用内核抢占。
preempt_count 是一个 int 而不是 bool 类型的值,表示对内核抢占的开关可以嵌套,多次增加 preempt_count 关闭内核抢占后,必须递减同样次数的 preempt_count,才能再次启用内核抢占。
preempt_count 操作相关的函数:
preempt_disable:通过调用
inc_preempt_count增加计数来停用抢占。此外,会指示编译器避免某些内存优化,以免导致某些与抢占机制相关的问题。preempt_check_resched:会检测是否有必要进行调度,如有必要则进行。
preempt_enable:启用内核抢占,然后立即用 preempt_check_resched 检测是否有必要重调度。
preempt_enable_no_resched:启用内核抢占,但不进行重调度。实际操作是调用
dec_preempt_count()为 preempt_count 加 1。
抢占的实际操作就是调用主调度器__schedule()函数触发一次调度。
在开启抢占式调度(CONFIG_PREEMPT)的情况下,preempt_schedule_context()会在合适的时机执行,此时会检测当前进程是否需要被调度(TIF_NEED_RESCHED 标志),然后执行preempt_schedule()
在 preempt_schedule() 中,判断当前是否允许内核抢占(preempt_count 是否为 0)或是否停用了中断(irqs_disabled()),如果允许,则调用主调度器函数__schedule()触发调度:
static void __sched notrace preempt_schedule_common(void)
{
do {
/*
* Because the function tracer can trace preempt_count_sub()
* and it also uses preempt_enable/disable_notrace(), if
* NEED_RESCHED is set, the preempt_enable_notrace() called
* by the function tracer will call this function again and
* cause infinite recursion.
*
* Preemption must be disabled here before the function
* tracer can trace. Break up preempt_disable() into two
* calls. One to disable preemption without fear of being
* traced. The other to still record the preemption latency,
* which can also be traced by the function tracer.
*/
preempt_disable_notrace();
preempt_latency_start(1);
__schedule(SM_PREEMPT);
preempt_latency_stop(1);
preempt_enable_no_resched_notrace();
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
} while (need_resched());
}
#ifdef CONFIG_PREEMPTION
/*
* This is the entry point to schedule() from in-kernel preemption
* off of preempt_enable.
*/
asmlinkage __visible void __sched notrace preempt_schedule(void)
{
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
if (likely(!preemptible())) ///抢占条件判断
return;
preempt_schedule_common();
}而抢占条preemptible 则在下方实现
#define preemptible() (preempt_count() == 0 && !irqs_disabled()) ///抢占条件:未关闭中断,且preempt_count=0;所以,我们也得到了我们熟知的一条规则:
中断关闭的情况下,不允许发生调度!
如果在中断关闭的情况下,发生调度,会有如下的内核panic
BUG: scheduling while atomic: <task_name>/PID内核抢占的触发时机
不会触发抢占的场景(内核态不可抢占)
PS: 这里举一个比较经典的例子:spin_lock和spin_unlock期间是不允许使用可以休眠的函数的
这个是为什么呢?
static __always_inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}自旋锁是非睡眠锁,意味着 它假设临界区代码是短、快、不会阻塞的。
持锁期间,内核通过提升
preempt_count禁止调度(不是睡眠,而是禁止切换任务)。如果这时候 sleep:
当前任务不能被调度出;
又没释放锁;
其他 CPU 卡在
spin_lock()等它释放 → 死锁。
白话文来说:spinlock时,使用preempt_disable已经禁止调度了,此时CPU需要集中时间片去执行当前的task,然后快速返回去unlock。但是你加了可以睡眠的函数,导致当前CPU很长一段时间无法发生调度,造成系统调度异常!