
前言
紧接上文 [linux内存管理] 第042篇 Linux内核Page Cache机制深入分析,在上文中我们介绍了page cache的基础概念。
Page Cache是Linux内核中一个中心化的磁盘缓存系统,它使用空闲的物理内存来缓存从磁盘读取的数据。当应用程序读取文件时,内核首先检查所需数据是否已在Page Cache中,如果存在(缓存命中),则直接从内存返回数据,避免昂贵的磁盘I/O操作;如果不存在(缓存未命中),则从磁盘读取数据,并存入Page Cache以备后续使用。
Page Cache的缓存单元是内存页(通常为4KB),与虚拟内存管理中的页大小一致。这种设计使得Page Cache能够与虚拟内存系统紧密集成,共享相同的底层页管理机制。

核心的数据结构:
在 Linux 内核中,使用 file 对象来描述一个被打开的文件,其中有个名为 f_mapping 的字段,定义如下
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */ ///指向inode
//...
struct address_space *f_mapping; ///inode映射的地址空间
//...
}从上面代码可以看出f_mapping 字段的类型为 address_space 结构
address_space结构体
address_space 是 Linux 页缓存(page cache)的核心数据结构,每个打开的文件都有一个关联的 address_space,用于:
缓存文件数据页(通过
i_pages)管理文件的内存映射(通过
i_mmap)提供文件与页缓存之间的操作接口(通过
a_ops)
// include/linux/fs.h
struct address_space {
struct inode *host; /// 指向所属的文件inode(哪个文件拥有这个地址空间)
struct xarray i_pages; /// 使用xarray存储的页缓存页面(替代了原来的radix tree)
struct rw_semaphore invalidate_lock; /// 用于同步页失效操作的读写信号量
gfp_t gfp_mask; /// 分配页面时使用的GFP标志
atomic_t i_mmap_writable; /// 记录可写内存映射的数量(用于mlock计数)
#ifdef CONFIG_READ_ONLY_THP_FOR_FS
/* number of thp, only for non-shmem files */
atomic_t nr_thps; /// 透明大页的数量(仅用于非共享内存文件)
#endif
struct rb_root_cached i_mmap; /// 红黑树根,存储所有映射此页缓存的VMA(虚拟内存区域)
struct rw_semaphore i_mmap_rwsem; /// 保护i_mmap红黑树的读写信号量
unsigned long nrpages; /// 地址空间中页面的总数
pgoff_t writeback_index; /// 回写操作的起始偏移(用于writeback)
const struct address_space_operations *a_ops; /// 文件操作函数集合(读页、写页等)
unsigned long flags; /// 地址空间标志位
errseq_t wb_err; /// 写回错误状态序列
spinlock_t private_lock; /// 保护private_list的自旋锁
struct list_head private_list; /// 私有数据链表(由文件系统使用)
void *private_data; /// 私有数据指针(由文件系统使用)
} __attribute__((aligned(sizeof(long)))) __randomize_layout; /// 按long类型对齐,并随机化布局(安全增强)这是 Linux 内核中 address_space 结构体的定义,它用于管理文件页缓存和内存映射,下面介绍一下各个字段的作用:
关键字段说明:
host:指向拥有此地址空间的inode对象,建立了地址空间与文件的关联。i_pages:存储所有缓存页的容器,索引是文件偏移量对应的页号。i_mmap:红黑树,存储所有映射此文件页缓存的 VMA(虚拟内存区域),用于实现mmap()内存映射。a_ops:文件系统特定的操作函数,包括:readpage:从磁盘读取页到缓存writepage:将缓存页写回磁盘direct_IO:直接 I/O 操作等
nrpages:当前缓存的总页数,用于统计和管理。private_list/private_data:供文件系统存储私有数据(如 ext4 的延迟分配结构)。__randomize_layout:内核安全特性,随机化结构体字段布局,防止利用固定偏移的攻击。
address_space_operations 操作函数
/* address_space操作函数表 */
struct address_space_operations {
/* 读取页 */
int (*readpage)(struct file *, struct page *);
/* 写入页 */
int (*writepage)(struct page *, struct writeback_control *);
/* 设置页脏 */
int (*set_page_dirty)(struct page *);
/* 准备写入(用于延迟分配) */
int (*prepare_write)(struct file *, struct page *, unsigned, unsigned);
/* 提交写入 */
int (*commit_write)(struct file *, struct page *, unsigned, unsigned);
/* 回写完成通知 */
void (*write_end)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata);
/* 直接I/O */
ssize_t (*direct_IO)(struct kiocb *, struct iov_iter *iter);
/* 获取块映射 */
sector_t (*bmap)(struct address_space *, sector_t);
/* 使页无效(截断时使用) */
void (*invalidatepage)(struct page *, unsigned int, unsigned int);
/* 释放页 */
int (*releasepage)(struct page *, gfp_t);
/* 释放页(直接I/O) */
void (*freepage)(struct page *);
/* 迁移页 */
int (*migratepage)(struct address_space *,
struct page *, struct page *, enum migrate_mode);
};同时也介绍了page cache的读取路径,既然有了读取那么就有回写操作,所以本章开始介绍回写的流程。由于作者水平有限, 文章不足之处在所难免, 恩请广大读者朋友批评指正。
脏页的概念
脏页是指 内存中被修改过但还没写回磁盘的页(page)。这些页通常位于内核的page cache中。
当写入文件(如 write() 系统调用)时,数据通常不会立刻写入磁盘,而是:
内核先把数据写入 页缓存(Page Cache);
这块缓存页被标记为 “脏”(dirty);
后台的 写回(writeback)线程 在合适的时机(比如页太多、时间到、内存压力大)将脏页写入磁盘;
写入完成后,页标记为 干净(clean)。
这种机制提高了性能 —— 避免每次 I/O 都直接写磁盘。
匿名页不需要跟踪脏页,因为不需要同步到磁盘;私有文件页也不需要跟踪脏页,因为映射的时候,可写页会映射为只读,写访问会发生写时复制,转变为匿名页;所以只有共享的文件页需要跟踪脏页
这里我们需要关注的有两点:一是内核如何在合适的时机记录文件页为脏?二是哪些页面需要跟踪脏页?
哪些页面需要跟踪脏页?
内核主要跟踪那些映射了可写文件数据的内存页。具体包括以下几类:
Page Cache 中的文件数据页:这是最主要的对象。当应用程序通过
write()系统调用写入文件,或者通过mmap()映射文件并修改内存时,对应的 Page Cache 页会被标记为脏。内存映射(mmap)页:如果文件被映射到进程的虚拟内存空间(VMA),且映射是可写的,那么对这段内存的修改也会导致对应的物理页变为脏页。
文件系统元数据页:虽然文档主要讨论数据页,但文件系统的元数据(如 inode 信息、目录结构等)在修改时也会产生脏页,需要被跟踪以便回写。
核心判断逻辑:只要内存中的数据是磁盘文件的缓存副本,且该副本与磁盘上的数据不一致(即被修改过),这个页面就需要被跟踪。
内核如何在合适的时机记录文件页为脏?
内核通过写操作触发和数据结构标记相结合的方式来记录脏页。
A. 触发时机(何时标记)
内核并不是周期性地去扫描哪些页被修改了,而是被动触发。主要有以下三个场景:
表格
B. 记录机制(如何跟踪)
内核利用 address_space 结构体中的特定字段来管理脏页列表:
private_list链表:这是内核用来跟踪脏页的核心数据结构。address_space结构体中包含一个private_list(私有链表)和一个private_lock(自旋锁)。当一个页被标记为脏(dirty)时,它会被插入到所属
address_space的private_list链表中。
mapping指针:页描述符(struct page)中有一个mapping指针,指向它所属的address_space。这使得内核可以通过页快速找到它属于哪个文件的缓存,从而进行统一管理。状态位:页描述符中还有特定的位(bit)用于标记该页的状态(如
PG_dirty),配合address_space的链表进行管理。
这个也是本章的重点内容,这里只作为简单描述!
访问文件页有两种方式:一种是通过mmap映射文件,一种是通过文件系统的write接口操作文件,本文将对这两种方式进行讲解。在Linux内核中,因为跟踪脏页会涉及到文件回写、缺页异常、反向映射等技术,为了保证文章的主题不跑偏,所以本文只重点讲解在Linux内核中如何跟踪脏页的部分!
mmap映射的文件页的脏页回写流程
基本过程如下:
进程通过
mmap系统调用将一个文件以共享(MAP_SHARED)方式映射到其虚拟地址空间。当进程首次写访问映射区域的某个内存页时,会触发缺页异常。内核处理该异常,将文件对应的数据页读入 Page Cache,并更新进程页表项,将其标记为可写和脏(Dirty)。
当内核的回写线程(如
flusher)根据策略(如脏页比例或超时)决定将此脏页回写到磁盘时,会通过反向映射(rmap)机制找到所有映射该页的虚拟内存区域(VMA),并将这些 VMA 对应的页表项设置为只读,同时清除脏标记。当进程再次尝试写访问此内存页时,根据内核页表项的状态,会有以下两种情况:
情况一: 如果该页尚未被回写(即步骤3还未执行),页表项仍为可写。进程可以直接写入,页表项会再次被标记为脏。
情况二: 如果该页已经完成回写(即步骤3已执行),页表项已被设为只读。此时的写访问会再次触发缺页异常。在异常处理中,内核会识别出这是共享映射的写保护,进而重新将页表项更新为可写和脏,允许进程继续写入。
第一次写文件页
handle_pte_fault
->do_fault
->do_shared_fault
->__do_fault //读文件页到page cache
->do_page_mkwrite
->vmf->vma->vm_ops->page_mkwrite() // 以ext4文件系统为例就是 ext4_page_mkwrite
->ext4_page_mkwrite,
->finish_fault //设置页表项
->alloc_set_pte
->if (write)
entry = maybe_mkwrite(pte_mkdirty(entry), vma) //设置页表项脏、可写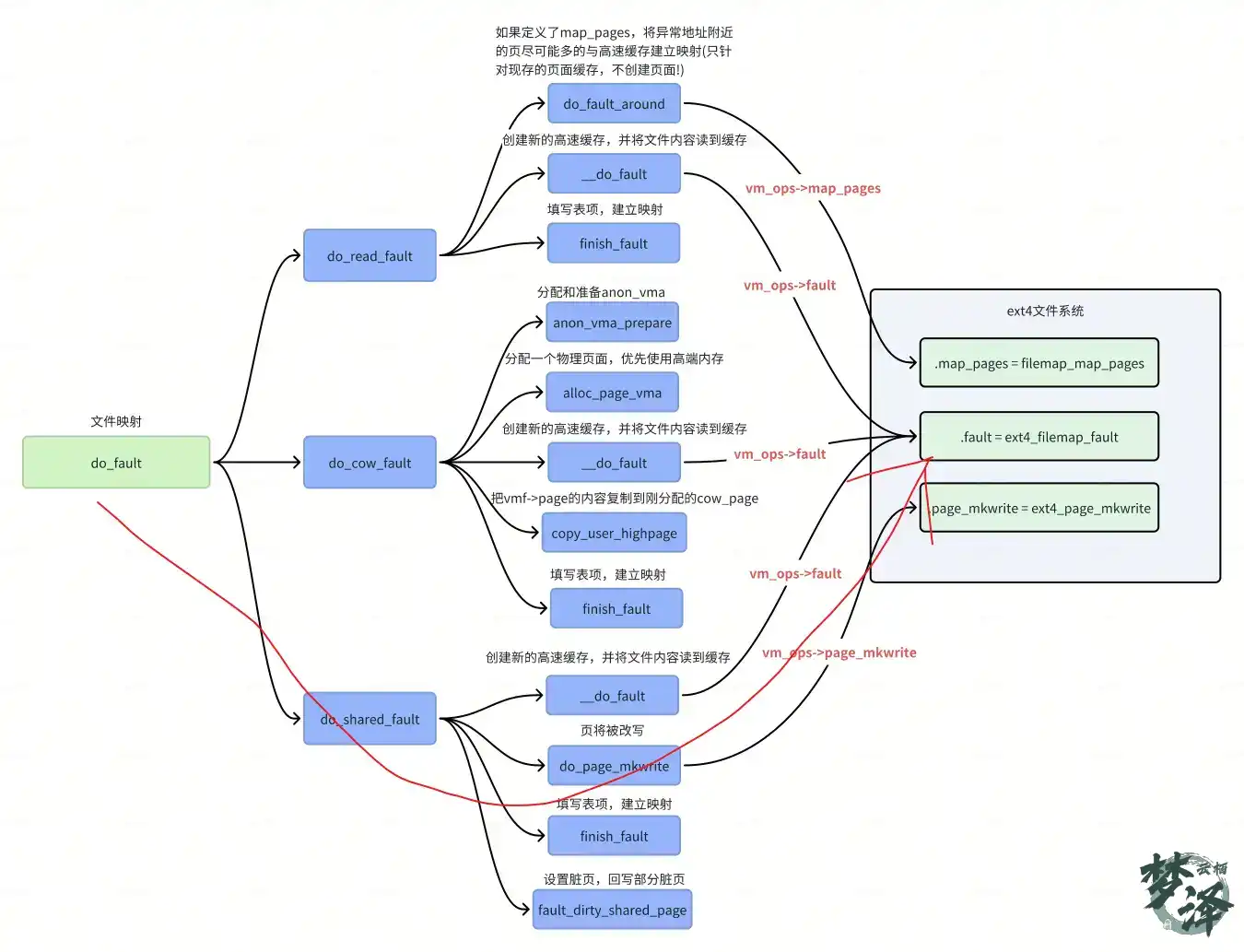
vm_fault_t ext4_page_mkwrite(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page = vmf->page;
loff_t size;
unsigned long len;
int err;
vm_fault_t ret;
struct file *file = vma->vm_file;
struct inode *inode = file_inode(file);
struct address_space *mapping = inode->i_mapping;
handle_t *handle;
get_block_t *get_block;
int retries = 0;
// 如果 inode 被标记为不可变(immutable),直接返回总线错误,禁止写入
if (unlikely(IS_IMMUTABLE(inode)))
return VM_FAULT_SIGBUS;
// 通知文件系统即将发生页面错误,用于防止文件系统冻结等操作
sb_start_pagefault(inode->i_sb);
// 更新文件时间戳
file_update_time(vma->vm_file);
filemap_invalidate_lock_shared(mapping);
err = ext4_convert_inline_data(inode);
if (err)
goto out_ret;
/*
* On data journalling we skip straight to the transaction handle:
* there's no delalloc; page truncated will be checked later; the
* early return w/ all buffers mapped (calculates size/len) can't
* be used; and there's no dioread_nolock, so only ext4_get_block.
*/
// 在 data=journal 模式下,所有数据都需要先写入日志,不能使用简单的
// 延迟分配或普通块分配。直接跳转到 retry_alloc,后续使用事务进行特殊处理
if (ext4_should_journal_data(inode))
goto retry_alloc;
/* Delalloc case is easy... */
// 如果启用了延迟分配(默认情况),且未触发“nonda switch”(强制关闭延迟分配的条件,如内存压力),则调用通用函数 block_page_mkwrite,并传入回调 ext4_da_get_block_prep 来为页面分配延迟块。
if (test_opt(inode->i_sb, DELALLOC) &&
!ext4_nonda_switch(inode->i_sb)) {
do {
err = block_page_mkwrite(vma, vmf,
ext4_da_get_block_prep);
} while (err == -ENOSPC &&
ext4_should_retry_alloc(inode->i_sb, &retries));
goto out_ret;
}
lock_page(page);
size = i_size_read(inode);
/* Page got truncated from under us? */
// 检查页面是否被截断
if (page->mapping != mapping || page_offset(page) > size) {
unlock_page(page);
ret = VM_FAULT_NOPAGE;
goto out;
}
// 计算本次需要处理的长度
if (page->index == size >> PAGE_SHIFT)
len = size & ~PAGE_MASK;
else
len = PAGE_SIZE;
/*
* Return if we have all the buffers mapped. This avoids the need to do
* journal_start/journal_stop which can block and take a long time
*
* This cannot be done for data journalling, as we have to add the
* inode to the transaction's list to writeprotect pages on commit.
*/
if (page_has_buffers(page)) {
// 遍历所有缓冲区,查看是否还有未映射的缓冲区。如果全部已映射,则只需等待页面稳定(防止与回写冲突)
if (!ext4_walk_page_buffers(NULL, inode, page_buffers(page),
0, len, NULL,
ext4_bh_unmapped)) {
/* Wait so that we don't change page under IO */
wait_for_stable_page(page);
ret = VM_FAULT_LOCKED;
goto out;
}
}
// 如果有未映射的缓冲区,则需要分配新块,因此先解锁页面,进入 retry_alloc
unlock_page(page);
/* OK, we need to fill the hole... */
if (ext4_should_dioread_nolock(inode))
get_block = ext4_get_block_unwritten;
else
get_block = ext4_get_block;
retry_alloc:
handle = ext4_journal_start(inode, EXT4_HT_WRITE_PAGE,
ext4_writepage_trans_blocks(inode));
if (IS_ERR(handle)) {
ret = VM_FAULT_SIGBUS;
goto out;
}
/*
* Data journalling can't use block_page_mkwrite() because it
* will set_buffer_dirty() before do_journal_get_write_access()
* thus might hit warning messages for dirty metadata buffers.
*/
if (!ext4_should_journal_data(inode)) {
err = block_page_mkwrite(vma, vmf, get_block);
} else {
lock_page(page);
size = i_size_read(inode);
/* Page got truncated from under us? */
if (page->mapping != mapping || page_offset(page) > size) {
ret = VM_FAULT_NOPAGE;
goto out_error;
}
if (page->index == size >> PAGE_SHIFT)
len = size & ~PAGE_MASK;
else
len = PAGE_SIZE;
// 分配块并创建缓冲区
err = __block_write_begin(page, 0, len, ext4_get_block);
if (!err) {
ret = VM_FAULT_SIGBUS;
if (ext4_walk_page_buffers(handle, inode,
page_buffers(page), 0, len, NULL,
do_journal_get_write_access)) // 为缓冲区获取日志写访问
goto out_error;
if (ext4_walk_page_buffers(handle, inode,
page_buffers(page), 0, len, NULL,
write_end_fn))
goto out_error;
if (ext4_jbd2_inode_add_write(handle, inode,
page_offset(page), len))
goto out_error;
ext4_set_inode_state(inode, EXT4_STATE_JDATA);
} else {
unlock_page(page);
}
}
ext4_journal_stop(handle);
if (err == -ENOSPC && ext4_should_retry_alloc(inode->i_sb, &retries))
goto retry_alloc;
out_ret:
ret = block_page_mkwrite_return(err);
out:
filemap_invalidate_unlock_shared(mapping);
sb_end_pagefault(inode->i_sb);
return ret;
out_error:
unlock_page(page);
ext4_journal_stop(handle);
goto out;
}在 ext4_page_mkwrite 函数中,页面被标记为脏(dirty)主要通过以下两种方式,具体取决于文件系统的挂载选项和日志模式:
何时标记为脏页?
通过 block_page_mkwrite() 间接标记脏
适用路径:
延迟分配模式(
DELALLOC且未触发nonda_switch):调用block_page_mkwrite(vma, vmf, ext4_da_get_block_prep)。传统非数据日志模式(如 ordered 或 writeback):在
retry_alloc分支中,调用block_page_mkwrite(vma, vmf, get_block)(其中get_block可能是ext4_get_block或ext4_get_block_unwritten)。
内部机制:
block_page_mkwrite是通用辅助函数(定义在fs/buffer.c),它会:锁定页面并检查文件大小。
若需要,调用
__block_write_begin()准备写入(可能分配新块)。调用
block_commit_write()完成写入准备。block_commit_write()会遍历页面的缓冲区,对每个新写入的缓冲区调用mark_buffer_dirty()。mark_buffer_dirty()最终通过__set_page_dirty()将页面结构体的PG_dirty标志置位,从而标记页面为脏。
int block_page_mkwrite(struct vm_area_struct *vma, struct vm_fault *vmf,
get_block_t get_block)
{
struct page *page = vmf->page;
struct inode *inode = file_inode(vma->vm_file);
unsigned long end;
loff_t size;
int ret;
lock_page(page);
size = i_size_read(inode);
if ((page->mapping != inode->i_mapping) ||
(page_offset(page) > size)) {
/* We overload EFAULT to mean page got truncated */
ret = -EFAULT;
goto out_unlock;
}
/* page is wholly or partially inside EOF */
if (((page->index + 1) << PAGE_SHIFT) > size)
end = size & ~PAGE_MASK;
else
end = PAGE_SIZE;
ret = __block_write_begin(page, 0, end, get_block);
if (!ret)
ret = block_commit_write(page, 0, end); //// 内部会遍历 __set_page_dirty() 将页面加入脏页列表并设置 PG_dirty 标志
if (unlikely(ret < 0))
goto out_unlock;
set_page_dirty(page); //// 再次显性设置脏页
wait_for_stable_page(page);
return 0;
out_unlock:
unlock_page(page);
return ret;
}数据日志模式下的显式标记脏
适用路径:
当ext4_should_journal_data(inode)为真时,代码跳转到retry_alloc,启动事务后执行数据日志特殊处理。内部机制:
调用
__block_write_begin()分配块并创建缓冲区。使用
ext4_walk_page_buffers()遍历所有缓冲区,依次调用两个函数:do_journal_get_write_access:为缓冲区获取日志写访问(不标记脏)。write_end_fn:该函数通常定义为简单的mark_buffer_dirty(或类似实现),它会将每个缓冲区标记为脏。
通过标记缓冲区脏,最终也会触发页面脏标志的置位(原理同上)。
设置 inode 状态
EXT4_STATE_JDATA,表示数据已加入日志。
ext4_walk_page_buffers 函数其实内部会回调传入的一个fn回调函数,也就是 do_journal_get_write_access 和 write_end_fn
而在 write_end_fn 中就会设置dirty
static int write_end_fn(handle_t *handle, struct inode *inode,
struct buffer_head *bh)
{
int ret;
if (!buffer_mapped(bh) || buffer_freed(bh))
return 0;
set_buffer_uptodate(bh);
ret = ext4_handle_dirty_metadata(handle, NULL, bh); //// 设置脏页
clear_buffer_meta(bh);
clear_buffer_prio(bh);
return ret;
}何时标记页表项为脏?
->finish_fault //设置页表项
->alloc_set_pte
->if (write)
entry = maybe_mkwrite(pte_mkdirty(entry), vma) //设置页表项脏、可写void do_set_pte(struct vm_fault *vmf, struct page *page, unsigned long addr)
{
struct vm_area_struct *vma = vmf->vma;
bool write = vmf->flags & FAULT_FLAG_WRITE;
bool prefault = vmf->address != addr;
pte_t entry;
flush_icache_page(vma, page);
entry = mk_pte(page, vma->vm_page_prot);
if (prefault && arch_wants_old_prefaulted_pte())
entry = pte_mkold(entry);
else
entry = pte_sw_mkyoung(entry);
if (write)
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
/* copy-on-write page */
if (write && !(vma->vm_flags & VM_SHARED)) {
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
page_add_new_anon_rmap(page, vma, addr, false);
lru_cache_add_inactive_or_unevictable(page, vma);
} else {
inc_mm_counter_fast(vma->vm_mm, mm_counter_file(page));
page_add_file_rmap(page, false);
}
set_pte_at(vma->vm_mm, addr, vmf->pte, entry);
}如果当前缺页是写操作(FAULT_FLAG_WRITE),则:
pte_mkdirty(entry):在页表项中设置脏位(_PAGE_DIRTY),表示该页即将被写入。这是页表层面的脏位,用于跟踪页面的修改状态。maybe_mkwrite(entry, vma):根据 VMA 的权限,决定是否设置可写位(_PAGE_RW)。对于共享映射,如果 VMA 允许写,则直接设置可写;对于私有映射,即使当前是写缺页,通常也会先以只读方式映射,直到实际发生写时复制(COW)。但在do_set_pte中,write标志通常意味着页面已经准备好被写入(如 COW 新页),因此maybe_mkwrite会设置可写位(前提是 VMA 允许写且不是只读)。实际上,maybe_mkwrite的逻辑是:如果 VMA 可写,则返回可写的 PTE,否则保持只读。这里因为write为真,且页面是 COW 新页(私有)或共享可写,通常 VMA 是可写的,所以最终 PTE 会是可写且脏的。
脏页回写
write_cache_pages 是内核中用于将给定地址空间(address_space)中的脏页回写到磁盘的核心函数。它被广泛用于各种文件系统的回写路径(如 ext4_writepages、generic_writepages 等),负责遍历页面缓存中的脏页,并对每个页面调用文件系统提供的 writepage 回调,从而将数据持久化。
//mm/page-writeback.c
write_cache_pages
->clear_page_dirty_for_io(page) //对于回写的每一个页
->page_mkclean(page) //清脏标记 mm/rmap.c
->page_mkclean_one //反向映射查找这个页的每个vma,调用清脏标记和写保护处理
->entry = pte_wrprotect(entry); //写保护处理,设置只读
entry = pte_mkclean(entry); //清脏标记 set_pte_at(vma->vm_mm, address, pte, entry) //设置到页表项中
->TestClearPageDirty(page) //清页描述符脏标记函数原型
int write_cache_pages(struct address_space *mapping,
struct writeback_control *wbc,
writepage_t writepage,
void *data)mapping:目标文件的地址空间,即
inode->i_mapping,包含了该文件的全部页面缓存。wbc:写回控制结构,包含回写范围、同步模式、回写页数限制等信息。
writepage:文件系统提供的回调函数,用于将单个页面写入磁盘(通常为
ext4_writepage或__ext4_writepage)。data:传递给
writepage的额外参数(通常用于传递文件系统特定上下文)。
主要流程
while (!done && (index <= end)) {
nr_pages = pagevec_lookup_range_tag(&pvec, mapping, &index, end, tag);
if (nr_pages == 0)
break;
for (i = 0; i < nr_pages; i++) {
struct page *page = pvec.pages[i];
done_index = page->index;
lock_page(page);
// 检查页面是否仍属于该 mapping(可能被截断或移走)
if (unlikely(page->mapping != mapping))
goto continue_unlock;
// 页面不再是脏页(可能已被其他回写线程处理)
if (!PageDirty(page))
goto continue_unlock;
// 如果页面正在回写,根据同步模式决定等待或跳过
if (PageWriteback(page)) {
if (wbc->sync_mode != WB_SYNC_NONE)
wait_on_page_writeback(page);
else
goto continue_unlock;
}
BUG_ON(PageWriteback(page)); // 确保不再有回写进行中
// 关键步骤:清除页面脏标志并准备 I/O
if (!clear_page_dirty_for_io(page))
goto continue_unlock;
// 调用文件系统的 writepage 回调
error = (*writepage)(page, wbc, data);
// ... 错误处理 ...
}
pagevec_release(&pvec);
cond_resched();
}页面锁:对每个页面加锁,防止并发修改。
有效性检查:确认页面仍属于正确的
mapping,避免处理已被截断的页。脏页检查:如果页面不再是脏的(可能被其他回写线程处理),则跳过。
等待回写:如果页面已在回写中(
PageWriteback置位),且同步模式要求等待(WB_SYNC_ALL或WB_SYNC_NONE?实际上代码中if (wbc->sync_mode != WB_SYNC_NONE)表示除了纯异步模式外都等待),则调用wait_on_page_writeback等待完成。清除脏标志:
clear_page_dirty_for_io(page)是核心函数,它负责清除页面的PG_dirty标志,并将页面的修改记录到文件系统(例如通过将缓冲区标记为“正在回写”),同时确保页面的所有修改都被捕获。如果清除失败(例如页面被并发截断),则跳过。调用
writepage:文件系统提供的回调实际执行 I/O。该回调通常会将页面内容写入磁盘,并在 I/O 完成后清除PG_writeback标志。错误处理:如果
writepage返回错误,根据同步模式决定是否提前终止。对于AOP_WRITEPAGE_ACTIVATE特殊错误,解锁页面并继续(该错误表示页面被激活,需要重试)。对于其他错误,如果是后台回写(WB_SYNC_NONE),则记录错误并停止;如果是数据完整性回写(WB_SYNC_ALL),则继续处理剩余页,但返回第一个错误。计数控制:
wbc->nr_to_write递减,当减到 0 且为异步模式时停止回写。
总结
write_cache_pages 是内核 writeback 机制的基石,它封装了遍历脏页、处理并发、同步模式、错误记录等通用逻辑,而具体的 I/O 操作则委托给文件系统的 writepage 回调。理解该函数有助于把握从页面缓存到磁盘的完整数据流,并深入理解文件系统与内存管理子系统的交互。
结合之前的 ext4_page_mkwrite 分析,可以形成闭环:
缺页写入:
page_mkwrite准备页面(分配块、可能标记脏)。用户写入:硬件置页表脏位,或通过
set_page_dirty标记页面脏。回写触发:内核调用
write_cache_pages扫描脏页。清除脏标志并调用
writepage:将数据写入磁盘。I/O 完成:清除
PG_writeback,页面变回干净。
这一流程确保了内存映射文件的数据最终持久化。
第二次写访问文件页时
脏页还没有回写时,页描述符已经设置了脏标记,页表项已经设置了脏标记、可写。
这时可以直接写访问文件页,不会发生缺页。
脏页已经回写时,页描述符已经清除了脏标记,页表项已经清除了脏标记,且只读。
这时写访问文件页会发生写时复制缺页异常(访问权限错误缺页)。
备注:写时复制缺页异常后面一篇专门聊聊
write操作的文件页的脏页回写
当用户通过 write() 系统调用向文件写入数据时,内核处理数据的路径与通过内存映射(mmap)写入有显著区别。write() 操作并不依赖于进程的页表映射,而是通过将用户缓冲区中的数据拷贝到内核的 page cache 页面中来完成写入,随后通过设置页面的 PG_dirty 标志来跟踪脏页。
以经典的 ext4 文件系统为例,write 系统调用的大致路径如下:
write写入文件的基本流程
用户态调用:
write(fd, buf, count)内核入口:
ksys_write()→vfs_write()→ 文件系统提供的write方法(如ext4_file_write_iter)。通用写准备:
generic_perform_write()(或类似函数)负责将用户数据写入 page cache。对于要写入的每个页面(按文件偏移计算):
调用
__pagecache_get_page()查找或分配 page cache 页面。如果需要,从磁盘读取现有内容(读缺失时)。
将用户数据从用户空间拷贝到内核页面:
copy_from_user()。关键步骤:拷贝完成后,调用
mark_buffer_dirty()(对于块设备)或直接调用set_page_dirty()来标记该页面为脏。
脏页标记传播:
set_page_dirty()最终会设置页面的PG_dirty标志,并将页面添加到对应地址空间的脏页链表,同时设置 radix tree(现 XArray)的PAGECACHE_TAG_DIRTY标签。写回时机:内核的 pdflush 或后台回写线程(如
wb_workfn)会定期扫描脏页标签,调用write_cache_pages()遍历脏页,并通过文件系统的writepage回调将页面内容写回磁盘。
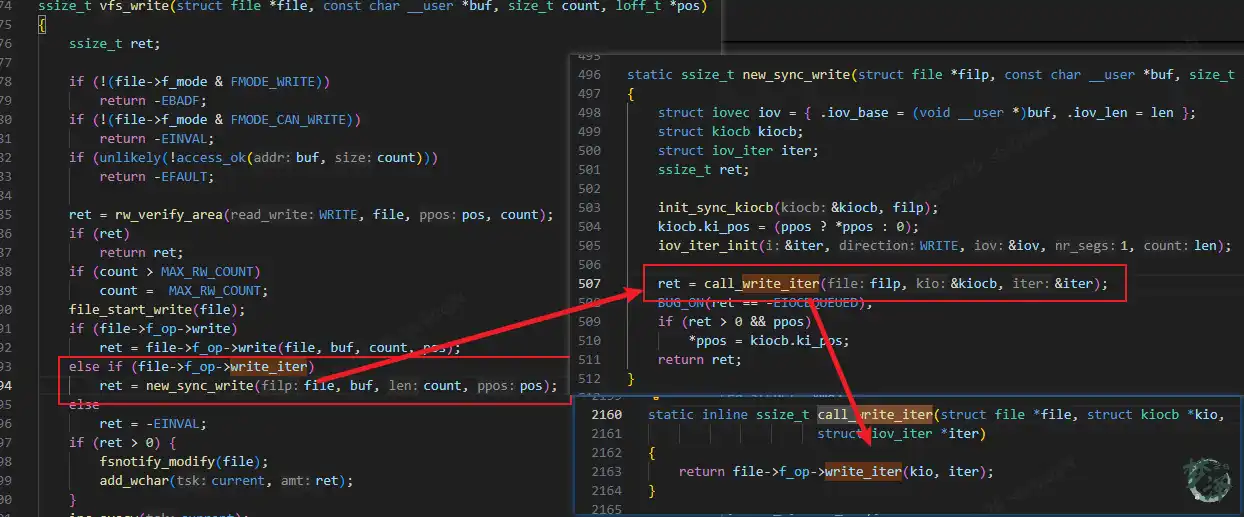
而file->f_op->write_iter函数就是 ext4_file_write_iter
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter, /////// 这个
.iopoll = iomap_dio_iopoll,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
};我们来看看这个函数
static ssize_t
ext4_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct inode *inode = file_inode(iocb->ki_filp);
if (unlikely(ext4_forced_shutdown(EXT4_SB(inode->i_sb))))
return -EIO;
#ifdef CONFIG_FS_DAX
if (IS_DAX(inode))
return ext4_dax_write_iter(iocb, from);
#endif
if (iocb->ki_flags & IOCB_DIRECT)
return ext4_dio_write_iter(iocb, from);
else
return ext4_buffered_write_iter(iocb, from);
}iocb:I/O 控制块,包含文件指针、起始偏移、标志(如IOCB_DIRECT、IOCB_SYNC等)等信息。from:迭代器,描述用户空间的数据缓冲区及其长度。返回值:成功时返回写入的字节数,失败时返回负的错误码。
DAX 模式(直接访问)
#ifdef CONFIG_FS_DAX
if (IS_DAX(inode))
return ext4_dax_write_iter(iocb, from);
#endif如果文件系统启用了 DAX(Direct Access)且该 inode 支持 DAX(通常是通过挂载选项
-o dax或文件属性设置),则调用ext4_dax_write_iter。DAX 特点:绕过 page cache,直接对持久内存设备进行访问(如 NVDIMM)。写入时直接修改存储介质上的数据,无需经过内核缓冲,具有低延迟和高性能,但需要硬件支持。
直接 I/O 模式(O_DIRECT)
if (iocb->ki_flags & IOCB_DIRECT)
return ext4_dio_write_iter(iocb, from);如果用户打开文件时指定了
O_DIRECT标志(对应IOCB_DIRECT),则执行直接 I/O。直接 I/O 特点:数据直接在用户缓冲区和磁盘之间传输,绕过 page cache,避免了内核缓冲的开销和额外的数据拷贝,但要求用户缓冲区对齐(通常为块大小)。这种模式适用于需要用户管理缓存的大型数据库等应用。
缓冲写入模式(默认)
c
else
return ext4_buffered_write_iter(iocb, from);对于普通写入(未指定
O_DIRECT且非 DAX),采用缓冲写入。缓冲写入特点:数据先写入 page cache 中的页面,然后由内核后台线程(如 pdflush)在适当时机写回磁盘。这是最常用的写入方式,具有良好的性能和通用性。
与脏页跟踪的关系:在缓冲写入路径中,内核会将用户数据拷贝到 page cache 页面,然后调用
set_page_dirty标记页面为脏(通过mark_buffer_dirty等)。这些脏页会被后续的回写机制处理,正如我们之前讨论的write_cache_pages所做的那样。
第一次写访问文件页
会首先读文件页到page cache,然后将用户空间写缓冲区数据写到page cache,调用链如下:
ext4_file_write_iter //fs/ext4/file.c
->generic_file_write_iter //mm/filemap.c
->generic_perform_write
->a_ops->write_begin() //写之前处理 分配page cache页 ->iov_iter_copy_from_user_atomic //户空间写缓冲区数据写到page cache页 -> a_ops->write_end() //写之后处理
->block_write_end
->__block_commit_write
->mark_buffer_dirty
if (!TestSetPageDirty(page)) { //设置页描述符脏标记 ->__set_page_dirty //设置页为脏(设置页描述符脏标记)ext4_file_write_iter进入 ext4 的写入入口,根据标志选择缓冲写入(ext4_buffered_write_iter,实际通过generic_file_write_iter)。generic_perform_write是核心函数,它循环处理每一页:调用
a_ops->write_begin(ext4 的实现如ext4_write_begin)来准备页面:可能从磁盘读取现有内容(读缺失)或分配新页,并锁定页面。通过
iov_iter_copy_from_user_atomic将用户数据拷贝到内核页面。调用
a_ops->write_end(如ext4_write_end)完成写入后的处理,其中会调用block_write_end→__block_commit_write→mark_buffer_dirty。
mark_buffer_dirty内部会调用TestSetPageDirty(page),该操作:检查页面是否已被标记为脏(
PG_dirty)。如果未脏,则设置该标志,并将页面添加到对应地址空间的脏页链表,同时设置 radix tree(XArray)的
PAGECACHE_TAG_DIRTY标签,以便后续回写线程能够快速找到脏页。
备注:a_ops就是 address_space_operations 类型的 ext4_aops ,方便大家在跟踪代码时跳转。
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.readahead = ext4_readahead,
.writepage = ext4_writepage,
.writepages = ext4_writepages,
.write_begin = ext4_write_begin, ///// 这里
.write_end = ext4_write_end, ///// 这里
.set_page_dirty = ext4_set_page_dirty,
.bmap = ext4_bmap,
.invalidatepage = ext4_invalidatepage,
.releasepage = ext4_releasepage,
.direct_IO = noop_direct_IO,
.migratepage = buffer_migrate_page,
.is_partially_uptodate = block_is_partially_uptodate,
.error_remove_page = generic_error_remove_page,
.swap_activate = ext4_iomap_swap_activate,
};第一次写访问文件页时,会先通过 write_begin 将页面读入 page cache(如果尚未存在),然后拷贝用户数据,最后通过 mark_buffer_dirty 设置页面的 PG_dirty 标志,从而完成脏页跟踪。
脏页回写
同上一章节mmap映射时的脏页回写
write_cache_pages //mm/page-writeback.c
->clear_page_dirty_for_io
->TestClearPageDirty(page) //清除页描述符脏标记第二次写访问文件页时
脏页回写之前,页描述符脏标志位依然被置位,等待回写, 不需要设置页描述符脏标志位。
脏页回写之后,页描述符脏标志位是清零的,文件写页调用链会设置页描述符脏标志位。
总结
1. 对于 mmap 共享文件页的脏页跟踪
当多个进程通过 mmap 共享映射同一个文件页时,该页可能同时存在于多个进程的页表中。脏页跟踪通过以下方式实现:
首次写触发缺页:进程首次对映射区域执行写操作时,由于页表项不可写(或不存在),触发缺页异常。缺页处理中,内核将文件页读入 page cache(若未存在),并通过
do_set_pte在进程页表中建立映射,设置页表项为可写(pte_mkwrite)并标记软件脏位(pte_mkdirty)。随后,进程实际写入时,硬件会自动置位页表项的硬件脏位(通常与软件脏位合一)。回写前同步脏状态:当内核决定回写该页(如内存回收或周期性回写)时,会调用
clear_page_dirty_for_io。该函数通过反向映射(rmap)遍历所有映射该页的页表项,调用page_mkclean将每个页表项的脏位清除,并将页表项改为只读。同时,如果发现任何页表项原本是脏的,则调用set_page_dirty将页面的PG_dirty标志置位(确保页面被正确标记,尽管此时可能已经脏)。这一过程保证了回写时页面内容不会再被修改。回写完成后再次写:页面回写完成后,
PG_dirty被清除,但页表项仍为只读。当进程再次写入时,会再次触发缺页异常(写保护缺页),进入do_wp_page或文件系统的page_mkwrite回调。在共享映射中,通常直接重用页面,重新设置页表项为可写并标记脏位,页面再次变为脏,如此循环。
关键点:脏页的跟踪依赖于页表项脏位与页面 PG_dirty 标志的协同:页表脏位记录最近写入,而 PG_dirty 确保页面在回写时被正确处理。反向映射机制用于在回写前同步所有映射。
2. 对于 write 接口访问的文件页的脏页跟踪
通过 write 系统调用写入文件时,数据通过内核缓冲(page cache)传递,文件页并不直接映射到任何进程的地址空间。脏页跟踪完全依赖页面描述符的 PG_dirty 标志:
写入时立即标记脏:在缓冲写入路径中,内核通过
generic_perform_write循环处理每一页。对于每个目标页,先调用文件系统的write_begin确保页面存在,然后通过copy_from_user将用户数据拷贝到页面中。最后,在write_end中调用mark_buffer_dirty(或直接set_page_dirty)显式设置页面的PG_dirty标志,并将页面加入地址空间的脏页链表和标签。回写时清除脏标志:当内核回写该页时,
write_cache_pages遍历脏页,对每个页面调用clear_page_dirty_for_io,该函数原子性地清除PG_dirty标志(通过TestClearPageDirty),并准备 I/O。随后调用文件系统的writepage将数据写入磁盘。再次写入时重新标记:回写完成后,页面变为干净。如果再次通过
write写入同一页,上述流程会再次执行,重新设置PG_dirty标志,继续跟踪。
关键点:整个过程中,脏页的跟踪完全由内核主动设置和清除 PG_dirty 标志完成,不涉及页表操作,因为页面从未被映射到用户空间。这种方式简单直接,适用于常规文件 I/O。
两种方式最终都通过统一的回写机制(
write_cache_pages)处理脏页,保证了数据持久化的一致性。
在本文中,我们详细剖析了 Linux 内核如何通过两种不同的机制(write 系统调用与 mmap 内存映射)对文件页进行脏页跟踪——即如何标记哪些页面已被修改、需要写回磁盘。这是数据持久化流程的“第一步”。然而,标记脏页本身并不保证数据安全,真正的持久化需要依赖接下来的脏页回写(Writeback)机制。
脏页回写是内核根据既定策略(如周期性回写、内存压力触发、或用户主动调用 fsync / msync)将脏页内容实际写入底层存储设备的过程。回写路径的核心函数 write_cache_pages 会遍历地址空间中的脏页标签,对每个页面调用文件系统提供的 writepage 回调,最终通过块层将数据下盘。在回写过程中,内核还会通过 clear_page_dirty_for_io 原子性地清除页面的脏标志,并可能通过反向映射同步页表状态(对 mmap 方式),确保回写期间数据不会被意外修改。
下一篇文章将深入剖析脏页回写的完整流程,包括:
回写线程的唤醒与工作方式;
回写控制参数(如
dirty_ratio、dirty_expire_centisecs)如何影响回写行为;文件系统的
writepages批量回写与单个writepage的区别;数据完整性操作(如
fsync)的实现细节。
敬请期待!