
使用Linux ramdump parser工具解析后,我们通常是可以得到解析出来的logcat日志的,那工具是如何从memory dump中解析出logcat的呢?
插件入口
插件是通过register_parser注册的,然后自动执行插件的parse函数。所以logcat也不例外。
parsers/logcat.py
@register_parser('--logcat', 'Extract logcat logs from ramdump ')
class Logcat(RamParser):
LOGCAT_BIN = "logcat.bin"
def __init__(self, *args):
super(Logcat, self).__init__(*args)
self.f_path_offset = self.ramdump.field_offset('struct file', 'f_path')
self.dentry_offset = self.ramdump.field_offset('struct path', 'dentry')
self.d_iname_offset = self.ramdump.field_offset('struct dentry', 'd_iname')
self.limit_size = int("0x20000000", 16)
self.vma_list = []通过register_parser注册插件,插件参数为:--logcat,默认解析。
注册好后,自动调用parse函数执行解析。
def parse(self):
if self.ramdump.logcat_limit_time == 0:
self.__parse()
else:
from func_timeout import func_timeout
print_out_str("Limit logcat parser running time to {}s".format(self.ramdump.logcat_limit_time))
func_timeout(self.ramdump.logcat_limit_time, self.__parse)这里有一ramdump.logcat_limit_time的参数,这个参数是从执行参数传入的,默认一般不设置,所以为0
parser.add_option('', '--logcat_limit_time_sec',
dest='logcat_limit_time', type='int', default=0,
help='Defined the max time logcat parse running')然后调用__parse()函数
解析函数__parse
def __parse(self):
try:
try:
taskinfo = UTaskLib(self.ramdump).get_utask_info("logd") # 调用UtaskLib的接口获取logd的taskinfo
except ProcessNotFoundExcetion:
print_out_str("logd process is not started")
return
propertyParser = Properties(self.ramdump) # 调用Properties获取property的解析器
ver = -1
try:
# generate system/vendor properties to Properties.txt
propertyParser.parse() # 执行property解析
for name, value in propertyParser.proplist:
if name == "ro.build.version.sdk" or name == "ro.vndk.version": # 获取两个属性值
ver = int(value)
except:
ver = -1
print_out_str("Current sdk version is "+ str(ver)) # 获取sdk版本号
if ver >= 31: # Android S # 我们现在的版本一般都>31,故分析这边
from parsers.logcat_v3 import Logcat_v3 # 调用logcat_v3脚本继续执行
logcat = Logcat_v3(self.ramdump, taskinfo) # 初始化logcat_v3解析器
try:
is_success = logcat.parse() # 解析logcat
except Exception as e:
is_success = False
print_out_str("logcat_v3 parser failed " + str(e))
traceback.print_exc()
if is_success:
print_out_str("logcat_v3 parse logcat success")
return
try:
from parsers.logcat_v3 import Logcat_vma
logcat = Logcat_vma(self.ramdump, taskinfo)
is_success = logcat.parse()
except Exception as e:
is_success = False
print_out_str("logcat_vma parser failed" + str(e))
traceback.print_exc()
if is_success:
print_out_str("logcat_vma parse logcat success")
else:
# generate logcat.bin when both logcat_v3 and logcat_vma parse failed
self.generate_logcat_bin(taskinfo)
elif self.is_LE_process(taskinfo):
print_out_str("LE ramdump")
from parsers.logcat_m import Logcat_m
#parser to supprot Android M
logcat = Logcat_m(self.ramdump, taskinfo)
logcat.parse()
elif self.is_openwrt_process(taskinfo):
print_out_str("Openwrt ramdump")
from parsers.logcat_openwrt import Logcat_openwrt
#parser to supprot openwrt platform
logcat = Logcat_openwrt(self.ramdump, taskinfo)
logcat.parse()
else:
self.generate_logcat_bin(taskinfo)
except Exception as result:
print_out_str(str(result))
traceback.print_exc()这个函数虽然不长,但是调用各种函数还是比较复杂的,故本小节分子章节分别叙述。
获取logd的taskinfo
taskinfo = UTaskLib(self.ramdump).get_utask_info("logd")
TODO:这里插个眼,LRDP2下一篇文章会去了解UtaskLib的实现,本章这里先默认调这个接口就能够获得logd的taskinfo
获取Properties
propertyParser = Properties(self.ramdump)
ver = -1
try:
# generate system/vendor properties to Properties.txt
propertyParser.parse()
for name, value in propertyParser.proplist:
if name == "ro.build.version.sdk" or name == "ro.vndk.version":
ver = int(value)
except:
ver = -1TODO:这里插个眼,LRDP2接下去的文章会去了解Properties的实现,本章这里先默认调这个接口就能够获得相关的prop属性。
logcat_v3解析
if ver >= 31: # Android S
from parsers.logcat_v3 import Logcat_v3
logcat = Logcat_v3(self.ramdump, taskinfo)
try:
is_success = logcat.parse()
except Exception as e:
is_success = False
print_out_str("logcat_v3 parser failed " + str(e))
traceback.print_exc()
if is_success:
print_out_str("logcat_v3 parse logcat success")
return
try:
from parsers.logcat_v3 import Logcat_vma
logcat = Logcat_vma(self.ramdump, taskinfo)
is_success = logcat.parse()
except Exception as e:
is_success = False
print_out_str("logcat_vma parser failed" + str(e))
traceback.print_exc()
if is_success:
print_out_str("logcat_vma parse logcat success")
else:
# generate logcat.bin when both logcat_v3 and logcat_vma parse failed
self.generate_logcat_bin(taskinfo)logcat_v3初始化
class Logcat_v3(Logcat_base):
def __init__(self, ramdump, taskinfo):
super().__init__(ramdump, taskinfo)logcat_v3解析
def parse(self):
self.read_dmesg() # 读取dmesg,通过接口extract_lockless_dmesg获取,之前一篇讲过
self.wall_to_mono_found, self.wall_to_monotonic_tv_sec, self.wall_to_monotonic_tv_nsec = self.findCorrection()
logbuf_addrs = self.get_logbuffer_addr()
for __logbuf_addr in logbuf_addrs:
logchunk_list_addr = __logbuf_addr + 0x60
try:
self.process_chunklist_and_save(logchunk_list_addr)
except Exception as e:
print(str(e))
traceback.print_exc()
if self.is_success:
print_out_str("logbuf_addr = 0x%x" %(__logbuf_addr))
break
return self.is_successfindCorrection
findCorrection: 从内存中提取日志时间校正值,这段计算校正值的原理,个人确实一头雾水
def findCorrection(self):
sec = 0
nsec = 0
found = False
correction_addr = 0
bss_addrs = self.find_bss_addrs()
for bss_start, bss_end in bss_addrs:
idx = 0
bss_size = bss_end - bss_start
while idx < bss_size:
if self.is_equal(bss_start + idx, 8, 3) and \
self.is_equal(bss_start + idx + 8*2, 8, 7) and \
self.is_equal(bss_start + idx + 8*4, 8, 5) and \
self.is_equal(bss_start + idx + 8*6, 8, 4):
correction_addr = bss_start + idx - 40
sec = self.read_bytes(correction_addr, 4)
nsec = self.read_bytes(correction_addr + 4, 4)
found = True
break
idx += 8
if found:
break
if found:
print_out_str(("Found &LogBuffer::Correction=0x%x LogBuffer::Correction=%ld.%ld")
% (correction_addr, sec, nsec))
else:
print_out_str("&LogBuffer::Correction not found")
return found, sec, nsec从代码逻辑来看,是从bss段里3 7 5 4 的这个段,找到后这个地址往前偏移40就可以得到correction_addr。
作者对这块不是很了解,linux kernel代码里在何处写入这个修正值,如果有知道的可以评论交流!
get_logbuffer_addr
def get_logbuffer_addr(self):
stack_offset = self.ramdump.field_offset('struct task_struct', 'stack') # 获取task_struct的成员stack的偏移
stack_addr = self.ramdump.read_word(self.logd_task + stack_offset) # 得到logd的stack_addr
pt_regs_size = self.ramdump.sizeof('struct pt_regs') # 获取pt_regs的size
pt_regs_addr = self.ramdump.thread_size + stack_addr - pt_regs_size # logd的stack_addr + 8192 - pt_regs的size
user_regs_addr = pt_regs_addr + self.ramdump.field_offset('struct pt_regs', 'user_regs')
#find x22 register value
x22_r_addr = self.ramdump.array_index(user_regs_addr, 'unsigned long', 22)
x22_value = self.ramdump.read_word(x22_r_addr)
x22_logbuf_addr = self.read_bytes(x22_value + 0x88, self.addr_length)
logbuf_addrs = []
if x22_logbuf_addr and x22_logbuf_addr != 0: # for logd orginal code
logbuf_addrs.append(x22_logbuf_addr)
print_out_str("logbuf_addr from x22 = 0x%x" %(x22_logbuf_addr))
x21_r_addr = self.ramdump.array_index(user_regs_addr, 'unsigned long', 21)
x21_value = self.ramdump.read_word(x21_r_addr)
x21_logbuf_addr = self.read_bytes(x21_value + 0x88, self.addr_length)
if x21_logbuf_addr and x21_logbuf_addr != 0:
logbuf_addrs.append(x21_logbuf_addr)
print_out_str("logbuf_addr from x21 = 0x%x" %(x21_logbuf_addr))
x23_r_addr = self.ramdump.array_index(user_regs_addr, 'unsigned long', 23)
x23_value = self.ramdump.read_word(x23_r_addr)
x23_logbuf_addr = self.read_bytes(x23_value + 0x88, self.addr_length)
if x23_logbuf_addr or x23_logbuf_addr == 0:
logbuf_addrs.append(x23_logbuf_addr)
print_out_str("logbuf_addr from x23 = 0x%x" %(x23_logbuf_addr))
return logbuf_addrs下面是几个需要注意的知识点:
pt_regs的地址
从代码来看pt_regs的地址计算公式为:stack_addr+thread_size-pt_regs_size
当进程通过系统调用或异常陷入内核时,CPU 会自动将寄存器压入内核栈顶,形成 pt_regs。内核栈从高地址向低地址增长,pt_regs 保存在栈顶
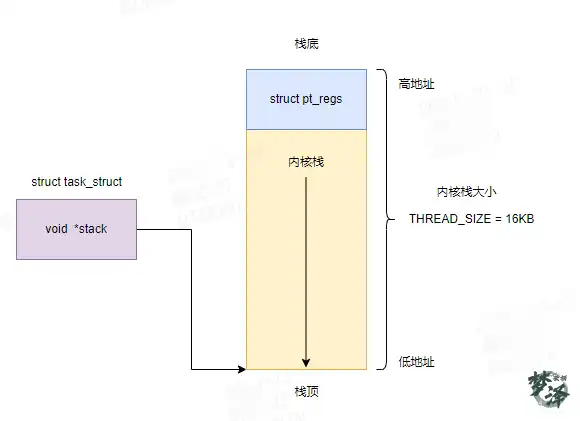
看上面这张图会更清晰一点!
接下来,让我们继续深入探索logcat_v3解析器的核心——process_chunklist_and_save函数,看看它究竟是如何从logd的内存中提取出一条条日志的。
process_chunklist_and_save——遍历日志缓冲区
当拿到logchunk_list_addr(即std::list<SerializedLogChunk>的地址)后,解析工作正式进入数据读取阶段。这个函数的目标是遍历每个日志ID(main、radio、events...),遍历每个日志块(SerializedLogChunk),读取原始数据,并最终解析成可读的LogEntry。
python
复制
下载
def process_chunklist_and_save(self, logchunk_list_addr):
log_id = 0
threads = []
with futures.ThreadPoolExecutor(8) as executor:
while log_id <= self.LOG_ID_MAX:
is_binary = (log_id == self.LOG_ID_EVENTS) or (log_id == self.LOG_ID_STATS) or (log_id == self.LOG_ID_SECURITY)
# 计算当前log_id对应的list头地址(std::list<SerializedLogChunk>)
_addr = logchunk_list_addr + log_id * 0x18
first_node_addr = self.read_bytes(_addr + self.addr_length, self.addr_length)
list_count = self.read_bytes(_addr + self.addr_length *2, self.addr_length)
if not list_count or list_count <= 0:
log_id += 1
continue
# 读取缓冲区最大大小(用于后续判断是否超大)
tail_node_addr = self.read_bytes(_addr, self.addr_length)
current_node = tail_node_addr + self.addr_length * 2
_data_size = self.read_bytes(current_node + self.addr_length, self.addr_length)
self.maxSize[log_id] = _data_size * 4 # 每个chunk按页对齐?这里可能是估算总大小
print_out_str(f"Log_id:{log_id} buffer size set to {self.maxSize[log_id]/1024:.1f} KB")
huge_buffersize = False
if self.maxSize[log_id] > self.LIMIT_LOGD_BUFFER_SZIE:
huge_buffersize = True
print_out_str(f" !!! WARN: Log_id:{log_id} buffer size over than "
f"{self.LIMIT_LOGD_BUFFER_SZIE/1024:.0f} kb, will only parser last 2 chunks")
next_node_addr = first_node_addr
self.sizeUsed[log_id] = 0
section = 0
while (section < list_count):
# 如果缓冲区超大,只解析最后两个chunk
if huge_buffersize:
if section < list_count - 2:
section = section + 1
next_node_addr = self.read_bytes(next_node_addr + self.addr_length, self.addr_length)
continue
current_node = next_node_addr + self.addr_length * 2 # 跳过list节点内的prev/next,指向SerializedLogChunk
write_offset = self.read_bytes(current_node + 0x10, 4) # write_offset_,已写入的数据长度
write_active = self.read_bytes(current_node + 0x18, 1) # write_active_,0表示已压缩,1表示未压缩
_data = None
if write_active == 0: # 压缩块
if self.zstd:
compressed_log_addr = current_node + 0x28
_data_addr = self.read_bytes(compressed_log_addr, self.addr_length)
_data_size = self.read_bytes(compressed_log_addr + self.addr_length, self.addr_length)
_data = self.read_binary(_data_addr, _data_size)
self.sizeUsed[log_id] = self.sizeUsed[log_id] + _data_size
else: # 未压缩块
_data_addr = self.read_bytes(current_node, self.addr_length)
_data_size = self.read_bytes(current_node + self.addr_length, self.addr_length)
self.sizeUsed[log_id] = self.sizeUsed[log_id] + write_offset
_data = self.read_binary(_data_addr, write_offset)
if _data:
# 提交到线程池解析
future = executor.submit(self.process_work_chunk, _data, log_id, section, is_binary, write_active)
threads.append(future)
section = section + 1
next_node_addr = self.read_bytes(next_node_addr + self.addr_length, self.addr_length)
log_id = log_id + 1
# 收集所有线程的解析结果
loglist = {}
for future in futures.as_completed(threads):
log_id, section, ret = future.result()
if not ret:
continue
if log_id in loglist:
sections = loglist[log_id]
else:
sections = {}
loglist[log_id] = sections
sections[section] = ret
self.save_log_to_file(loglist)这段代码逻辑清晰,但有几个关键点值得注意:
std::list<SerializedLogChunk>的内存布局:在64位系统中,std::list的每个节点通常包含prev、next指针(各8字节)以及节点数据(即SerializedLogChunk对象)。因此,给定list头地址,通过head+8得到第一个节点地址,节点地址+16得到SerializedLogChunk对象的起始地址。这正是代码中next_node_addr + self.addr_length*2的由来。SerializedLogChunk的结构:从代码中读取的字段可以推测出其大致布局:offset 0x00:
data指针(8字节)offset 0x08:
data_size(8字节)offset 0x10:
write_offset_(4字节)offset 0x18:
write_active_(1字节)offset 0x28:
compressed_log指针(8字节)和compressed_log_size(8字节)
这基本符合Android源码中SerializedLogChunk的定义。
多线程加速:使用8个线程的线程池并行解析每个chunk,大大缩短解析时间。
超大缓冲区处理:如果某个日志缓冲区大小超过40MB,则只解析最后两个chunk。这是为了避免处理过旧的数据,因为通常我们只关心最近的日志。
解析工作线程——process_work_chunk
每个线程调用process_work_chunk来处理一个chunk的数据。它根据是否压缩、是否是二进制日志,调用相应的解析函数。
def process_work_chunk(self, _data, log_id, section, is_binary, write_active):
if write_active == 0: # 需要解压
if not self.zstd:
return log_id, section, None
try:
_data = self.zstd.ZstdDecompressor().decompress(_data)
except:
print_out_str("decompress caused error on logid:section(%d:%d), size(%d)" %(log_id, section, len(_data)))
_data = None
ret = None
if _data:
try:
if is_binary:
ret = self.process_binary_log_and_save(_data)
else:
ret = self.process_log_and_save(_data, log_id)
except:
traceback.print_exc()
return log_id, section, ret普通日志解析——process_log_and_save
普通日志(main、radio、system等)的格式相对简单:每个日志条目由一个固定长度的头部和变长的消息体组成。
def process_log_and_save(self, _data, log_id):
ret = []
pos = 0
while pos < len(_data):
if pos + self.SIZEOF_LOG_ENTRY > len(_data):
break
# 解包头部:uid(4), pid(4), tid(4), sequence(8), tv_sec(4), tv_nsec(4), msg_len(2), priority(1)
logEntry = struct.unpack('<IIIQIIHB', _data[pos:pos+self.SIZEOF_LOG_ENTRY+1])
pos = pos + self.SIZEOF_LOG_ENTRY + 1 + self.extra_offset
uid, pid, tid, sequence, tv_sec, tv_nsec, msg_len, priority = logEntry
if msg_len is None or msg_len < 1:
break
msg = _data[pos:pos+msg_len-1] # 消息末尾可能有一个结束符,减去1
msgList = msg.decode('ascii', 'ignore').split('\0')
pos = pos + msg_len - 1
if len(msgList) < 2:
continue
try:
if log_id == self.LOG_ID_KERNEL:
entry = LogEntry_Dmesg()
entry.mono_format = self.wall_to_mono_found
entry.set_rtc_time(tv_sec, tv_nsec, self.wall_to_monotonic_tv_sec, self.wall_to_monotonic_tv_nsec)
else:
entry = LogEntry()
entry.tv_sec = tv_sec
entry.tv_nsec = tv_nsec
entry.pid = pid
entry.uid = uid
entry.tid = tid
entry.prior = priority
entry.tag = cleanupString(msgList[0].strip())
entry.set_msg(msgList[1])
entry.tz_minuteswest = self.tz_minuteswest
ret.append(entry)
except Exception:
traceback.print_exc()
return ret日志头部格式与Android的log_entry结构一致。注意消息体是以tag\0message形式存储的,所以用split('\0')分割。
二进制日志解析——process_binary_log_and_save
二进制日志(events、stats、security)的格式复杂一些,因为它需要解析嵌套的事件数据。
def process_binary_log_and_save(self, _data):
ret = []
pos = 0
while pos < len(_data):
# 头部同样有uid,pid,tid等,但无priority字段
logEntry = struct.unpack('<IIIQIIH', _data[pos : pos + self.SIZEOF_LOG_ENTRY])
pos = pos + self.SIZEOF_LOG_ENTRY + self.extra_offset
uid, pid, tid, sequence, tv_sec, tv_nsec, msg_len = logEntry
# 接着是tag索引(4字节)
tagidx = struct.unpack('<I', _data[pos : pos + self.SIZEOF_HEADER_T])[0]
pos = pos + self.SIZEOF_HEADER_T
# 解析事件数据
evt_type, tmpmsg, length = self.get_evt_data(_data, pos)
pos = pos + length
if evt_type == -1:
break
if evt_type != self.EVENT_TYPE_LIST:
# 简单类型(int/long/string/float)直接构造条目
entry = LogEntry()
entry.is_binary = True
entry.tv_sec = tv_sec
entry.tv_nsec = tv_nsec
entry.pid = pid
entry.uid = uid
entry.tid = tid
entry.prior = self.ANDROID_LOG_INFO
entry.tag = str(tagidx)
entry.set_msg(tmpmsg)
entry.tz_minuteswest = self.tz_minuteswest
ret.append(entry)
continue
# 如果是列表类型,则需要递归解析列表中的每个元素
list_t = struct.unpack('<BB', _data[pos : pos + self.SIZEOF_EVT_LIST_T])
pos = pos + self.SIZEOF_EVT_LIST_T
evt_type = list_t[0]
evt_cnt = list_t[1]
i = 0
msg = ""
while i < evt_cnt:
evt_type, tmpmsg, length = self.get_evt_data(_data, pos)
if evt_type == -1:
break
pos = pos + length
msg = msg + tmpmsg
if i < evt_cnt -1:
msg = msg + ","
i = i+1
entry = LogEntry()
entry.is_binary = True
entry.tv_sec = tv_sec
entry.tv_nsec = tv_nsec
entry.pid = pid
entry.uid = uid
entry.tid = tid
entry.prior = self.ANDROID_LOG_INFO
entry.tag = str(tagidx)
entry.set_msg("[" + msg + "]")
entry.tz_minuteswest = self.tz_minuteswest
ret.append(entry)
return retget_evt_data函数根据事件类型解析出对应的值,例如int类型占5字节(1字节类型+4字节值),string类型前5字节记录长度,后面跟着字符串数据。这些细节与Android的log_event定义完全吻合。
保存文件与去重——save_log_to_file
所有chunk解析完成后,得到的是一个按log_id和section组织的LogEntry列表。save_log_to_file负责将这些条目写入对应的文件。
def save_log_to_file(self, loglist):
if not loglist or len(loglist) == 0:
return
if not self.is_success:
self.is_success = True
for log_id in loglist.keys():
if log_id == self.LOG_ID_KERNEL and self.wall_to_mono_found:
continue # 内核日志将特殊处理
sections = loglist[log_id]
if not sections:
continue
filename = self.get_output_filename(log_id)
log_file = self.ramdump.open_file(filename)
write_head = False
for section in sorted(sections.keys()):
if sections[section] and len(sections[section]) >= 0:
if not write_head:
head = "{} log buffer used: {}k Max size:{}k\n".format(
self.LOG_NAME[log_id],
round(self.sizeUsed[log_id]/1024,1),
round(self.maxSize[log_id]/1024,1))
log_file.write(head)
write_head = True
head="--------- beginning of {} section: {}\n".format(
self.LOG_NAME[log_id], str(section))
log_file.write(head)
for item in sections[section]:
log_file.write(str(item))
# 如果找到了时间校正值,则需要合并内核日志与dmesg
if not self.wall_to_mono_found:
return
dmesgDict = []
if self.LOG_ID_KERNEL in loglist.keys():
sections = loglist[self.LOG_ID_KERNEL]
if sections:
for section in sorted(sections.keys()):
dmesgDict.extend(sections[section])
filename = self.get_output_filename(self.LOG_ID_KERNEL)
log_file = self.ramdump.open_file(filename)
if len(dmesgDict) > 0:
head = "{} log buffer used: {}k Max size:{}k\n".format(
self.LOG_NAME[self.LOG_ID_KERNEL],
round(self.sizeUsed[self.LOG_ID_KERNEL]/1024,1),
round(self.maxSize[self.LOG_ID_KERNEL]/1024,1))
log_file.write(head)
if len(self.dmesg_list) <= 0:
for item in dmesgDict:
log_file.write(str(item))
else:
self.combine_dmesg(dmesgDict, log_file)对于普通日志,直接按section顺序写入即可。对于内核日志,由于logd中也可能记录内核日志(通过LOG_ID_KERNEL),而我们在read_dmesg中已经提取了dmesg环形缓冲区的日志,两者可能有重叠。因此需要调用combine_dmesg进行智能合并。
内核日志合并——combine_dmesg
合并的核心思想是:将logd中的内核日志与dmesg中的日志按单调时间排序,如果时间接近(1ms内)且内容相似(一个字符串包含另一个),则认为是同一条日志,只保留dmesg中的版本(因为dmesg更原始,格式更统一)。最终按时间顺序输出所有条目。
def combine_dmesg(self, dmesgDict, log_file):
same_log_count = 0
log_added_count = 0
keys = sorted(self.dmesg_list) # dmesg中的单调时间列表
dmesg_time_start = keys[0]
index = 0
for item in dmesgDict:
if item.mono_time() < dmesg_time_start:
log_file.write(str(item))
else:
should_delete = []
while index < len(keys):
mono_time = keys[index]
s_pid = self.dmesg_list[mono_time][0]
s_line = self.dmesg_list[mono_time][1]
entry = LogEntry_Dmesg()
entry.mono_format = self.wall_to_mono_found
entry.set_mono_time(mono_time, self.wall_to_monotonic_tv_sec, self.wall_to_monotonic_tv_nsec)
entry.pid = s_pid
entry.uid = 0
entry.tid = s_pid
entry.set_msg(cleanupString(s_line))
entry.tz_minuteswest = self.tz_minuteswest
cmpval = item.__cmp__(entry) # 自定义比较:时间和内容
if cmpval > 0: # logd条目时间晚于dmesg条目,先输出dmesg
log_added_count += 1
index += 1
log_file.write(str(entry))
should_delete.append(mono_time)
continue
elif cmpval == 0: # 完全相同,跳过logd条目
index += 1
same_log_count += 1
should_delete.append(mono_time)
continue
else: # logd条目时间早于dmesg条目,输出logd条目
log_file.write(str(item))
break
for time in should_delete:
del self.dmesg_list[time]
# 输出剩余的dmesg日志
for mono_time in self.dmesg_list:
s_pid = self.dmesg_list[mono_time][0]
s_line = self.dmesg_list[mono_time][1]
entry = LogEntry_Dmesg()
entry.mono_format = self.wall_to_mono_found
entry.set_mono_time(mono_time, self.wall_to_monotonic_tv_sec, self.wall_to_monotonic_tv_nsec)
entry.pid = s_pid
entry.uid = 0
entry.tid = s_pid
entry.set_msg(cleanupString(s_line))
entry.tz_minuteswest = self.tz_minuteswest
log_added_count += 1
log_file.write(str(entry))
print_out_str("Total dmesg log count %d, same count %d, added count %d" %
(len(self.dmesg_list), same_log_count, log_added_count))这种去重机制确保了最终的内核日志文件既包含了dmesg的完整内容,又补充了logd中可能独有的内核日志(例如通过logd记录的一些用户空间相关日志),同时避免了重复。
如果logcat_v3失败:回退到Logcat_vma
Android不同版本、不同厂商的内核可能修改了logd的内存布局,导致通过寄存器定位log buffer的方法失效。此时解析器会尝试另一种方法——Logcat_vma,它通过扫描logd进程的所有可读写虚拟内存区域(VMA),寻找符合std::list<SerializedLogChunk>特征的数据结构。
Logcat_vma继承自Logcat_base,核心区别在于内存读取方式和定位log buffer的方法。
获取VMA数据:
def get_vmas_with_rw(self):
for vma in self.taskinfo.vmalist:
if vma.flags & 0b11 != 0b11:
continue
item = {}
item["vmstart"] = vma.vm_start
item["size"] = vma.vm_end - vma.vm_start
item["data"] = super().read_binary(item["vmstart"], item["size"])
self.vmas.append(item)它将logd进程中所有可读写(rw)的VMA的完整内容读入内存,然后后续的read_bytes和read_binary都从这些内存块中查找,避免反复读取ramdump。
定位list头:
def find_log_chunklist_addr(self, vma):
vma_size = vma["size"]
vma_data = vma["data"]
offset = 0
while offset < vma_size:
if self.is_log_chunklist_addr(vma_data, offset):
log_id = 1
while log_id <= self.LOG_ID_MAX:
if not self.is_log_chunklist_addr(vma_data, offset+0x18*log_id):
return 0
log_id = log_id + 1
break
offset = offset + 4
return offset if offset < vma_size else 0验证chunk有效性:
def is_log_chunk_addr(self, addr):
data_addr = self.read_bytes(addr, self.addr_length)
write_offset = self.read_bytes(addr + 0x10, 4)
write_active = self.read_bytes(addr + 0x18, 1)
data_size = self.read_bytes(addr + self.addr_length, self.addr_length)
compress_data_addr = self.read_bytes(addr + 0x28, self.addr_length)
compress_data_size = self.read_bytes(addr + 0x28 + self.addr_length, self.addr_length)
if (write_active == 1 and data_addr != 0 and data_size !=0 and
write_offset !=0 and write_offset < data_size):
return True
elif (write_active == 0 and compress_data_addr != 0 and compress_data_size !=0 and
write_offset !=0 and compress_data_size < write_offset):
return True
return False通过对chunk内关键字段的检查,判断是否是一个合法的日志块。一旦找到正确的log buffer基址,后续的解析流程与Logcat_v3完全一样。
最后的防线:generate_logcat_bin
如果上述两种方法都失败,说明我们无法从内存中结构化解析logcat日志。这时,工具会退而求其次,直接将logd进程的整个可读内存区域dump下来,保存为一个名为logcat.bin的二进制文件,供开发者日后使用更底层的手段分析。
def generate_logcat_bin(self, taskinfo):
filename = "{}-{}.bin".format(self.LOGCAT_BIN, datetime.datetime.now().strftime("%Y%m%d_%H%M%S"))
out_file = self.ramdump.open_file(filename)
# 遍历logd进程的所有vma,将可读的内存区域写入文件
for vma in taskinfo.vmalist:
if vma.vm_start < vma.vm_end and vma.flags & 0b100: # readable
data = self.ramdump.read_cstring(vma.vm_start, vma.vm_end - vma.vm_start)
if data:
out_file.write(data)
print_out_str("Generated raw logcat binary: {}".format(filename))这个文件虽然不能直接阅读,但可以用十六进制编辑器或strings命令查看,也许能从中提取出有用的信息。
总结
通过logcat_v3和logcat_vma两套解析方案,工具能够应对大多数Android设备的内存布局变化,成功从ramdump中还原出logcat日志。整个过程涉及进程内存读取、数据结构逆向、多线程解析、日志去重等技术点,充分体现了ramdump parser工具的灵活性和强大功能。
本文重点剖析了logcat_v3的实现细节,从定位log buffer,到解析日志块,再到合并内核日志,每一步都力求清晰。希望读者能从中了解到Android logcat在内存中的存储方式,以及离线解析工具背后的工作原理。