
本章源码遵循如下的约定:
1.芯片架构:ARM64
2.内核版本:linux-6.1.138
3.CONFIG_SMP=y
前言
随着对称多处理器(SMP)架构的普及,系统获得了前所未有的并行计算能力,但同时也面临着严峻的数据同步挑战。在单 CPU 时代,并发问题主要来源于进程调度带来的执行流交错;而在 SMP 系统中,程序真正地在多个处理器上同时执行,对共享数据的竞争变得无处不在。更复杂的是,为了缓解内存访问延迟,每个 CPU 都配备了私有缓存(如 L1 cache)以及共享的末级缓存(如 L2 cache),当某个 CPU 修改一个全局变量时,缓存一致性协议必须通知其他 CPU 使其对应的缓存行失效,这一过程会引入可观的开销,甚至成为性能瓶颈。
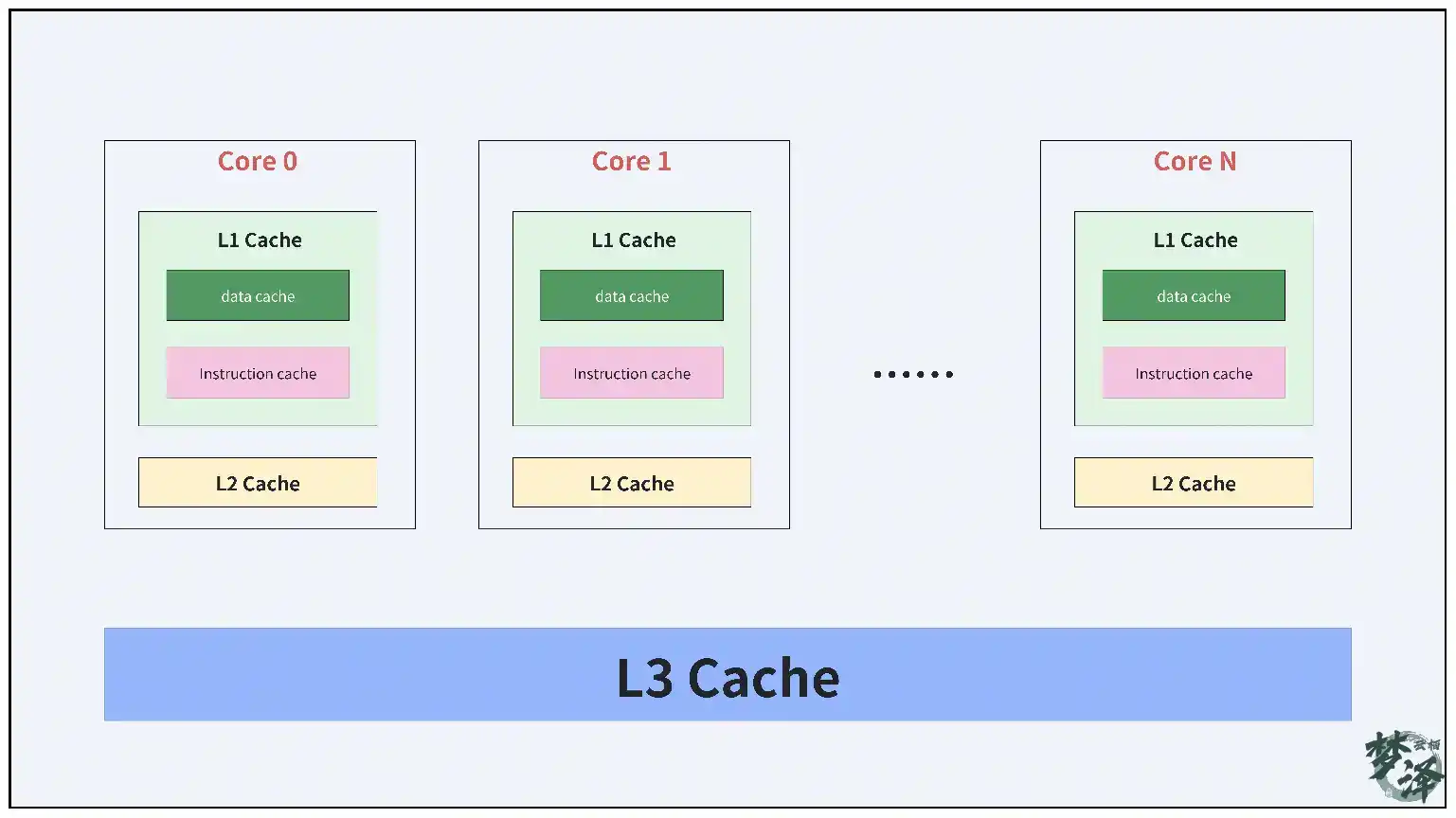
为了从根本上避免多 CPU 对同一数据的竞争,Linux 内核引入了 per‑CPU 变量机制。该机制为每个处理器在内存中保留一份独立的变量副本,每个 CPU 仅操作属于自己的那份副本,从而彻底消除了缓存同步和锁竞争的开销。当然,per‑CPU 变量并非万能,它只适用于那些在逻辑上天然是 CPU 私有的数据——在整个生命周期中,每个 CPU 的副本均由该 CPU 独占使用。
除了当前处理器之外,没有其他处理器可以接触到这个per-CPU变量副本,因此不存在并发访问问题,所以当前处理器可以在不用锁的情况下访问per-CPU变量。但是内核抢占会影响到per-CPU变量,因此在操作per-CPU变量时都会禁止内核抢占。
per-cpu变量,可以在编译时声明,也可以在系统运行时动态生成。
核心的数据结构
struct pcpu_alloc_info
struct pcpu_group_info {
int nr_units; /* aligned # of units */
unsigned long base_offset; /* base address offset */
unsigned int *cpu_map; /* unit->cpu map, empty
* entries contain NR_CPUS */
};
struct pcpu_alloc_info {
size_t static_size;
size_t reserved_size;
size_t dyn_size;
size_t unit_size;
size_t atom_size;
size_t alloc_size;
size_t __ai_size; /* internal, don't use */
int nr_groups; /* 0 if grouping unnecessary */
struct pcpu_group_info groups[];
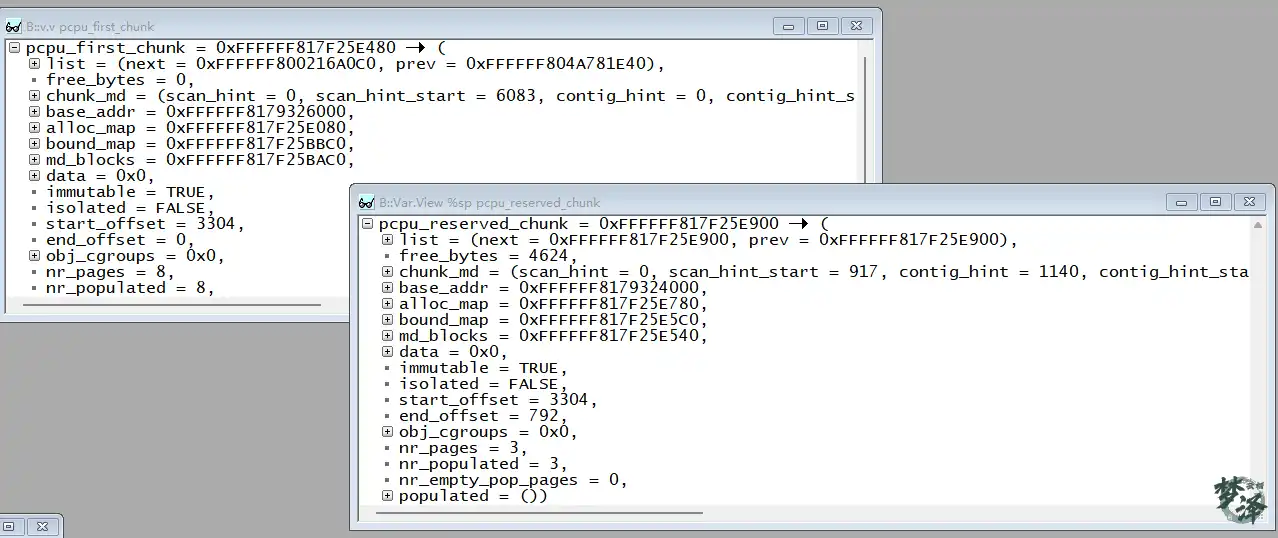
};该结构体描述整个 per-CPU 内存区域的整体布局和分配参数,是内核在初始化 per-CPU 内存时使用的信息载体。
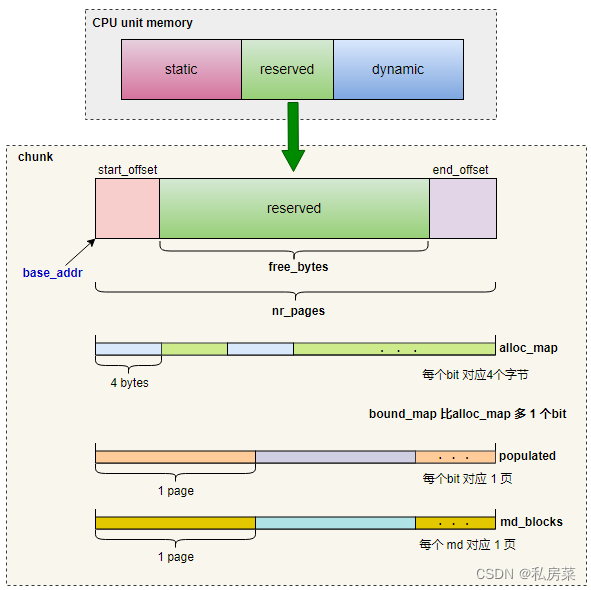
struct pcpu_chunk
struct pcpu_chunk {
#ifdef CONFIG_PERCPU_STATS
int nr_alloc; /* # of allocations */
size_t max_alloc_size; /* largest allocation size */
#endif
struct list_head list; /* linked to pcpu_slot lists */
int free_bytes; /* free bytes in the chunk */
struct pcpu_block_md chunk_md;
void *base_addr; /* base address of this chunk */
unsigned long *alloc_map; /* allocation map */
unsigned long *bound_map; /* boundary map */
struct pcpu_block_md *md_blocks; /* metadata blocks */
void *data; /* chunk data */
bool immutable; /* no [de]population allowed */
bool isolated; /* isolated from active chunk
slots */
int start_offset; /* the overlap with the previous
region to have a page aligned
base_addr */
int end_offset; /* additional area required to
have the region end page
aligned */
#ifdef CONFIG_MEMCG_KMEM
struct obj_cgroup **obj_cgroups; /* vector of object cgroups */
#endif
int nr_pages; /* # of pages served by this chunk */
int nr_populated; /* # of populated pages */
int nr_empty_pop_pages; /* # of empty populated pages */
unsigned long populated[]; /* populated bitmap */
};
struct pcpu_chunk 是 Linux 内核 per-CPU 内存分配器的核心数据结构,代表一个连续的内存块(chunk),用于管理分配给各 CPU 的内存单元。每个 chunk 内部划分为多个固定大小的单元(unit),每个单元对应一个 CPU 的私有副本。chunk 通过位图管理空闲空间、分配状态以及内存页的填充状态。下面按字段顺序逐一解析。
struct pcpu_chunk 的设计体现了 per-CPU 内存分配器的几个关键思想:
分块管理:将大块连续虚拟地址划分为多个 chunk,每个 chunk 独立管理。
位图辅助:通过
alloc_map和bound_map实现细粒度的空闲空间跟踪,populated位图管理物理页映射。分层元数据:
chunk_md和md_blocks构成两级元数据,加速大块空闲区域的查找。对齐与填充:
start_offset和end_offset确保 chunk 边界与页对齐,便于页表操作。扩展性:通过条件编译支持统计和内存 cgroup,同时提供
data指针和状态标志应对特殊场景。
struct pcpu_block_md
struct pcpu_block_md {
int scan_hint; /* scan hint for block */
int scan_hint_start; /* block relative starting
position of the scan hint */
int contig_hint; /* contig hint for block */
int contig_hint_start; /* block relative starting
position of the contig hint */
int left_free; /* size of free space along
the left side of the block */
int right_free; /* size of free space along
the right side of the block */
int first_free; /* block position of first free */
int nr_bits; /* total bits responsible for */
};该结构体是 per-CPU 内存分配器(percpu allocator)中“块元数据”的核心,用于描述一个固定大小的位图块(block)的空闲情况。
所有位置(start 字段)均以位为单位,相对于该块起始的偏移。
这些元数据帮助分配器在扫描位图时快速跳过已用区域,定位到合适的空闲空间,提高分配效率。
per-CPU内存分布
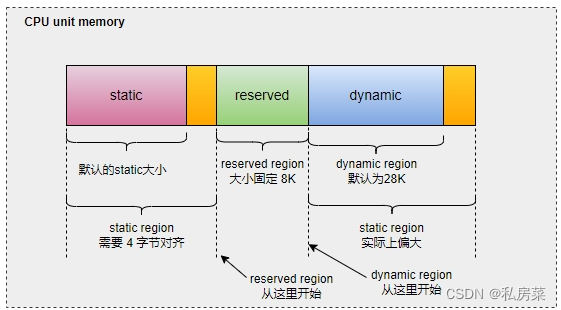
这张图是 cpu unit 的内存分配情况,其中:
static 的原始大小是 __per_cpu_end - __per_cpu_start;
reserved 固定大小是由宏 PERCPU_MODULE_RESERVE 指定,系统默认为 8K;
dynamic 原始大小是用宏 PERCPU_DYNAMIC_RESERVE 指定,系统默认为 28K;
static + reserved + dynamic 总大小经过 向上页对齐 之后就是 cpu unit 的大小;
从上面三个区域原始尺寸可知,cpu unit 经过页对齐后是否有多出来内存,主要看 static 原始大小是否页对齐,如果 static 不是页对齐,那么系统会多申请一些内存, 多出来的这部分就是图中两个 黄色区域 。 其中大部分会归到 dynamic 区域,因此 dynamic 区域尺寸会比原始尺寸大;
static region 实际大小可能会偏大,因为原始尺寸需要按照 PCPU_MIN_ALLOC_SIZE (4字节) 对齐,这就是图中第一个黄色部分;
reserved region 起始位置是从 static 按 PCPU_MIN_ALLOC_SIZE 对齐后的位置开始计算,区域大小固定;
dynamic region 会在原始尺寸的基础上加上另一个 黄色区域 ;
备注:本节摘自 Linux内存管理(十六):percpu 分配器——基本原理 第3节
per-CPU的初始化
在系统启动的早期,start_kernel 会调用 setup_per_cpu_areas() 来完成 per-cpu 内存的初始化。这一步为所有 per-cpu 变量(包括未来模块要用的)奠定了物理内存基础。
asmlinkage __visible void __init __no_sanitize_address start_kernel(void)
{
//...
setup_nr_cpu_ids();
setup_per_cpu_areas();
//...
}在 setup_per_cpu_areas() 之前会调用 setup_nr_cpu_ids() 函数,配置全局变量 nr_cpu_ids ,用以记录系统支持的 CPU core 数量,需要结合 boot_cpu_init() 进行确认。
对于 cpu 有 8 个核,则该 nr_cpu_ids 为 8。
void __init setup_nr_cpu_ids(void)
{
set_nr_cpu_ids(find_last_bit(cpumask_bits(cpu_possible_mask), NR_CPUS) + 1);
}
setup_per_cpu_areas
通过setup_per_cpu_areas函数来实现为系统中的每个CPU产生一份变量的副本,而且会对per-CPU的动态分配机制进行初始化。
void __init setup_per_cpu_areas(void)
{
unsigned long delta;
unsigned int cpu;
int rc;
/*
* Always reserve area for module percpu variables. That's
* what the legacy allocator did.
*/
rc = pcpu_embed_first_chunk(PERCPU_MODULE_RESERVE, PERCPU_DYNAMIC_RESERVE,
PAGE_SIZE, NULL, NULL);
if (rc < 0)
panic("Failed to initialize percpu areas.");
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu)
__per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu];
}它主要完成以下工作:
调用
pcpu_embed_first_chunk分配物理内存pcpu_embed_first_chunk(PERCPU_MODULE_RESERVE, PERCPU_DYNAMIC_RESERVE, PAGE_SIZE, NULL, NULL);该函数会在内存中分配一块连续的物理地址空间,用于存放所有 CPU 的 per-cpu 数据副本。
参数
PERCPU_MODULE_RESERVE表示需要为内核模块中定义的静态 per-cpu 变量预留一段空间。这部分预留区域位于内核静态 per-cpu 区域之后,确保模块的 per-cpu 变量能够被放在一个固定的、可寻址的范围内。PERCPU_DYNAMIC_RESERVE则为动态分配的 per-cpu 变量预留空间。分配成功后,全局指针
pcpu_base_addr指向整个 per-cpu 映射区域的起始地址,pcpu_unit_offsets[]数组记录了每个 CPU 的数据块相对于该起始地址的偏移量。
计算运行时 CPU 偏移量
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start; for_each_possible_cpu(cpu) __per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu];__per_cpu_start是链接脚本中定义的符号,表示内核静态 per-cpu 数据段(.data..percpu)的起始虚拟地址。delta表示实际分配的 per-cpu 区域起始地址与链接地址之间的差值。由于内核在链接时并不知道 per-cpu 区域最终会被映射到何处,因此需要这个偏移量来修正符号地址。对于每个可能的 CPU,其 per-cpu 数据块的起始地址相对于
pcpu_base_addr的偏移由pcpu_unit_offsets[cpu]给出。将该偏移加上delta就得到了每个 CPU 的数据块相对于内核静态 per-cpu 链接地址的偏移,这个值最终被存入__per_cpu_offset[cpu]。运行时,访问 per-cpu 变量时,CPU 通过
__my_cpu_offset()获取当前 CPU 对应的偏移值(通常保存在专用寄存器中),再与变量的链接地址相加,即可得到属于该 CPU 的变量副本的真实地址。
比如作者手上的这台设备的 pcpu_base_addr 和 __per_cpu_start
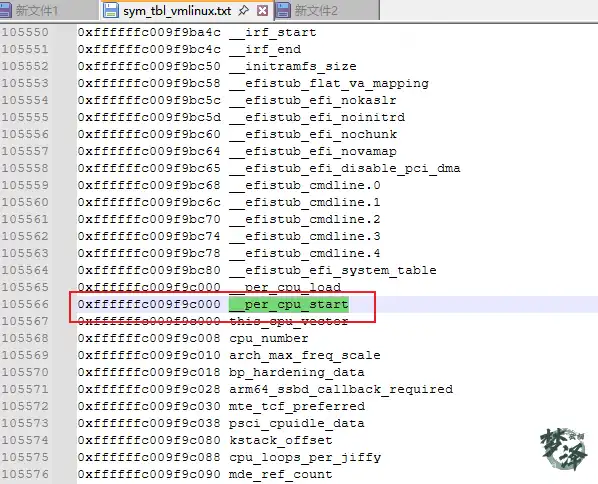
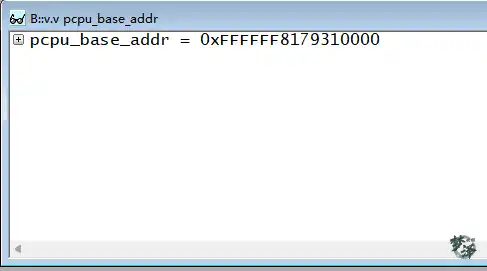
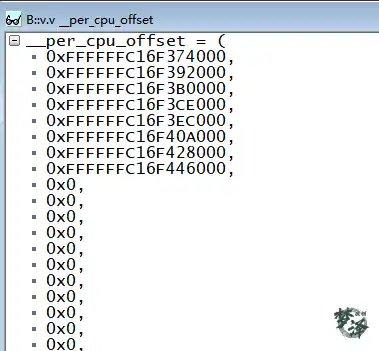
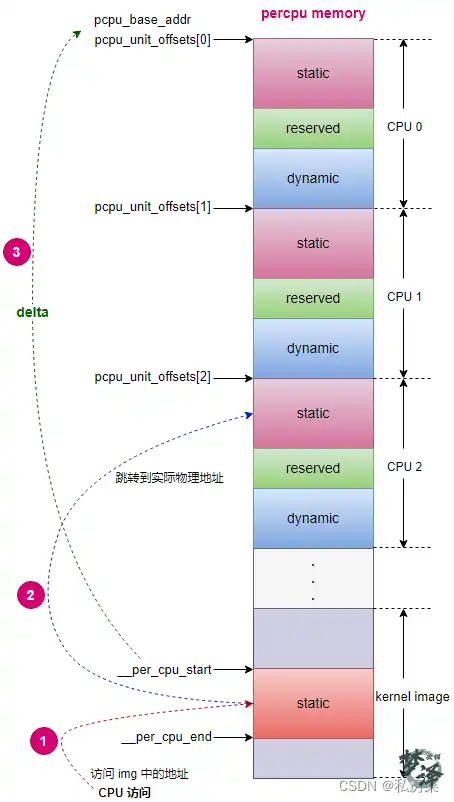
上用静态变量举例,来说明 pcpu_unit_offsets[]和__per_cpu_offset[] 两个数组。
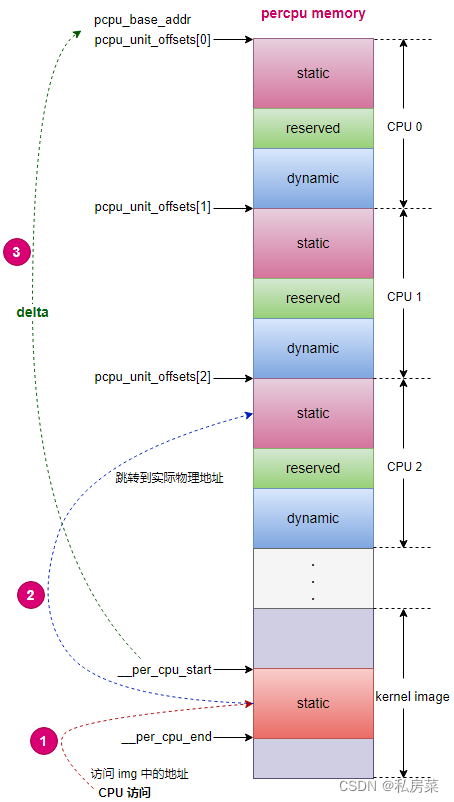
在物理内存中存在两块内存: kernel image 和 percpu;
对于静态变量,存在于kernel image 的 .data..percpu 段,在内存初始化初期会对这部分内存映射,当 CPU 访问某个 percpu 静态变量的时候,读取的地址归根结底是这 kernel image 中的 .data..percpu 段的某个变量的物理地址,如图中箭头 1 所示。该section 的起始物理地址为 __per_cpu_start ;
但实际上变量的实际内容在 percpu memory 段,这就是percpu 机制,当某 CPU(例如 cpu2) 想访问percpu 变量,实际需要到该 CPU (例如 cpu2) 所在的 percpu unit 中获取,如图中箭头 2 所示。
percpu memory 的起始地址为 pcpu_base_addr,为了方便管理系统创建了一个数组,即 pcpu_unit_offsets 数组,数组中存放的是每个 CPU 的 percpu unit 的起始地址相对于 pcpu_base_addr 的偏移量。
pcpu_base_addr - __per_cpu_start = delta ,这就是 .data.percpu 段的percpu 变量与实际 cpu unit 内存差值,如图中箭头 3 所示。
pcpu_embed_first_chunk
pcpu_embed_first_chunk 是 Linux 内核中用于初始化 per-cpu 数据区域的底层函数之一,它采用“嵌入”(embed)方式分配第一块 per-cpu 内存。该函数被 setup_per_cpu_areas 调用,为所有 CPU 分配连续的物理内存,并将内核静态定义的 per-cpu 变量数据复制到每个 CPU 的副本中,同时为模块预留空间和动态分配预留空间
int __init pcpu_embed_first_chunk(size_t reserved_size, size_t dyn_size,
size_t atom_size,
pcpu_fc_cpu_distance_fn_t cpu_distance_fn,
pcpu_fc_cpu_to_node_fn_t cpu_to_nd_fn)
{
void *base = (void *)ULONG_MAX;
void **areas = NULL;
struct pcpu_alloc_info *ai;
size_t size_sum, areas_size;
unsigned long max_distance;
int group, i, highest_group, rc = 0;
ai = pcpu_build_alloc_info(reserved_size, dyn_size, atom_size,
cpu_distance_fn);
if (IS_ERR(ai))
return PTR_ERR(ai);
size_sum = ai->static_size + ai->reserved_size + ai->dyn_size;
areas_size = PFN_ALIGN(ai->nr_groups * sizeof(void *));
areas = memblock_alloc(areas_size, SMP_CACHE_BYTES);
if (!areas) {
rc = -ENOMEM;
goto out_free;
}
/* allocate, copy and determine base address & max_distance */
highest_group = 0;
for (group = 0; group < ai->nr_groups; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
unsigned int cpu = NR_CPUS;
void *ptr;
for (i = 0; i < gi->nr_units && cpu == NR_CPUS; i++)
cpu = gi->cpu_map[i];
BUG_ON(cpu == NR_CPUS);
/* allocate space for the whole group */
ptr = pcpu_fc_alloc(cpu, gi->nr_units * ai->unit_size, atom_size, cpu_to_nd_fn);
if (!ptr) {
rc = -ENOMEM;
goto out_free_areas;
}
/* kmemleak tracks the percpu allocations separately */
kmemleak_ignore_phys(__pa(ptr));
areas[group] = ptr;
base = min(ptr, base);
if (ptr > areas[highest_group])
highest_group = group;
}
max_distance = areas[highest_group] - base;
max_distance += ai->unit_size * ai->groups[highest_group].nr_units;
/* warn if maximum distance is further than 75% of vmalloc space */
if (max_distance > VMALLOC_TOTAL * 3 / 4) {
pr_warn("max_distance=0x%lx too large for vmalloc space 0x%lx\n",
max_distance, VMALLOC_TOTAL);
#ifdef CONFIG_NEED_PER_CPU_PAGE_FIRST_CHUNK
/* and fail if we have fallback */
rc = -EINVAL;
goto out_free_areas;
#endif
}
/*
* Copy data and free unused parts. This should happen after all
* allocations are complete; otherwise, we may end up with
* overlapping groups.
*/
for (group = 0; group < ai->nr_groups; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
void *ptr = areas[group];
for (i = 0; i < gi->nr_units; i++, ptr += ai->unit_size) {
if (gi->cpu_map[i] == NR_CPUS) {
/* unused unit, free whole */
pcpu_fc_free(ptr, ai->unit_size);
continue;
}
/* copy and return the unused part */
memcpy(ptr, __per_cpu_load, ai->static_size);
pcpu_fc_free(ptr + size_sum, ai->unit_size - size_sum);
}
}
/* base address is now known, determine group base offsets */
for (group = 0; group < ai->nr_groups; group++) {
ai->groups[group].base_offset = areas[group] - base;
}
pr_info("Embedded %zu pages/cpu s%zu r%zu d%zu u%zu\n",
PFN_DOWN(size_sum), ai->static_size, ai->reserved_size,
ai->dyn_size, ai->unit_size);
pcpu_setup_first_chunk(ai, base);
goto out_free;
out_free_areas:
for (group = 0; group < ai->nr_groups; group++)
if (areas[group])
pcpu_fc_free(areas[group],
ai->groups[group].nr_units * ai->unit_size);
out_free:
pcpu_free_alloc_info(ai);
if (areas)
memblock_free(areas, areas_size);
return rc;
}函数参数说明
reserved_size:为内核模块的静态 per-cpu 变量预留的空间大小(对应PERCPU_MODULE_RESERVE)。dyn_size:为动态分配的 per-cpu 变量预留的空间大小(对应PERCPU_DYNAMIC_RESERVE)。atom_size:分配时的原子粒度,通常为 PAGE_SIZE 或缓存行大小,用于对齐。cpu_distance_fn:可选的回调函数,用于评估 CPU 之间的“距离”,以决定如何分组(NUMA 感知)。cpu_to_nd_fn:可选的回调函数,将 CPU 编号转换为 NUMA 节点 ID。
主要流程分解
构建分配信息(pcpu_build_alloc_info)
ai = pcpu_build_alloc_info(reserved_size, dyn_size, atom_size, cpu_distance_fn);
static struct pcpu_alloc_info * __init __flatten pcpu_build_alloc_info(
size_t reserved_size, size_t dyn_size,
size_t atom_size,
pcpu_fc_cpu_distance_fn_t cpu_distance_fn)
{
static int group_map[NR_CPUS] __initdata;
static int group_cnt[NR_CPUS] __initdata;
static struct cpumask mask __initdata;
// 静态变量总大小,从 __per_cpu_start ~ __per_cpu_end
const size_t static_size = __per_cpu_end - __per_cpu_start;
int nr_groups = 1, nr_units = 0;
size_t size_sum, min_unit_size, alloc_size;
int upa, max_upa, best_upa; /* units_per_alloc */
int last_allocs, group, unit;
unsigned int cpu, tcpu;
struct pcpu_alloc_info *ai;
unsigned int *cpu_map;
/* this function may be called multiple times */
memset(group_map, 0, sizeof(group_map));
memset(group_cnt, 0, sizeof(group_cnt));
cpumask_clear(&mask);
// //计算每个cpu所占有的percpu内存空间,
// 包括: 静态空间 + 预留空间 + 动态空间
/* calculate size_sum and ensure dyn_size is enough for early alloc */
size_sum = PFN_ALIGN(static_size + reserved_size +
max_t(size_t, dyn_size, PERCPU_DYNAMIC_EARLY_SIZE));
// 实际的动态空间,相当于上面size_sum是按照页对齐的,三者和多出来的部分最终都算到了dyn_size中
dyn_size = size_sum - static_size - reserved_size;
/*
* Determine min_unit_size, alloc_size and max_upa such that
* alloc_size is multiple of atom_size and is the smallest
* which can accommodate 4k aligned segments which are equal to
* or larger than min_unit_size.
*/
//理论上每个cpu unit的大小是按照size_sum,
//但系统设计要求每个cpu unit的大小,不能小于PCPU_MIN_UNIT_SIZE (32KB)
min_unit_size = max_t(size_t, size_sum, PCPU_MIN_UNIT_SIZE);
/* determine the maximum # of units that can fit in an allocation */
// 每次实际从内存分配器获取的连续内存块大小,按 atom_size 向上取整
alloc_size = roundup(min_unit_size, atom_size);
upa = alloc_size / min_unit_size;
while (alloc_size % upa || (offset_in_page(alloc_size / upa)))
upa--;
max_upa = upa;
cpumask_copy(&mask, cpu_possible_mask);
/* group cpus according to their proximity */
// 该循环将所有可能的 CPU 按距离函数分组:同组的 CPU 之间距离为 LOCAL_DISTANCE
for (group = 0; !cpumask_empty(&mask); group++) {
/* pop the group's first cpu */
cpu = cpumask_first(&mask);
group_map[cpu] = group;
group_cnt[group]++;
cpumask_clear_cpu(cpu, &mask);
for_each_cpu(tcpu, &mask) {
if (!cpu_distance_fn ||
(cpu_distance_fn(cpu, tcpu) == LOCAL_DISTANCE &&
cpu_distance_fn(tcpu, cpu) == LOCAL_DISTANCE)) {
group_map[tcpu] = group;
group_cnt[group]++;
cpumask_clear_cpu(tcpu, &mask);
}
}
}
nr_groups = group;
/*
* Wasted space is caused by a ratio imbalance of upa to group_cnt.
* Expand the unit_size until we use >= 75% of the units allocated.
* Related to atom_size, which could be much larger than the unit_size.
*/
last_allocs = INT_MAX;
best_upa = 0;
for (upa = max_upa; upa; upa--) {
int allocs = 0, wasted = 0;
if (alloc_size % upa || (offset_in_page(alloc_size / upa)))
continue;
for (group = 0; group < nr_groups; group++) {
int this_allocs = DIV_ROUND_UP(group_cnt[group], upa);
allocs += this_allocs;
wasted += this_allocs * upa - group_cnt[group];
}
/*
* Don't accept if wastage is over 1/3. The
* greater-than comparison ensures upa==1 always
* passes the following check.
*/
if (wasted > num_possible_cpus() / 3)
continue;
/* and then don't consume more memory */
if (allocs > last_allocs)
break;
last_allocs = allocs;
best_upa = upa;
}
BUG_ON(!best_upa);
upa = best_upa;
/* allocate and fill alloc_info */
// 计算总单元数并分配 alloc_info 结构
for (group = 0; group < nr_groups; group++)
nr_units += roundup(group_cnt[group], upa);
ai = pcpu_alloc_alloc_info(nr_groups, nr_units);
if (!ai)
return ERR_PTR(-ENOMEM);
cpu_map = ai->groups[0].cpu_map;
for (group = 0; group < nr_groups; group++) {
ai->groups[group].cpu_map = cpu_map;
cpu_map += roundup(group_cnt[group], upa);
}
// 填充 alloc_info 的基本字段
ai->static_size = static_size;
ai->reserved_size = reserved_size;
ai->dyn_size = dyn_size;
ai->unit_size = alloc_size / upa;
ai->atom_size = atom_size;
ai->alloc_size = alloc_size;
// 填充每个组的详细信息
for (group = 0, unit = 0; group < nr_groups; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
/*
* Initialize base_offset as if all groups are located
* back-to-back. The caller should update this to
* reflect actual allocation.
*/
gi->base_offset = unit * ai->unit_size;
for_each_possible_cpu(cpu)
if (group_map[cpu] == group)
gi->cpu_map[gi->nr_units++] = cpu;
gi->nr_units = roundup(gi->nr_units, upa);
unit += gi->nr_units;
}
BUG_ON(unit != nr_units);
return ai;
}pcpu_build_alloc_info 通过分析 CPU 拓扑、对齐要求和内存大小,设计出一套最优的 percpu 内存分配方案:
将 CPU 按距离分组,使同组 CPU 共享一个内存块,减少跨节点访问。
调整单元大小和分配块大小,平衡内存利用率和分配次数。
输出一个详细的分配信息结构,指导后续的 percpu 内存区域建立。
计算总大小与分配 areas 数组
size_sum = ai->static_size + ai->reserved_size + ai->dyn_size;
areas_size = PFN_ALIGN(ai->nr_groups * sizeof(void *));
areas = memblock_alloc(areas_size, SMP_CACHE_BYTES);size_sum是每个 CPU 单元中实际有效数据的大小(不含填充对齐部分)。areas是一个指针数组,用于保存每个组分配到的内存基地址,数组长度按页对齐分配,使用memblock_alloc(启动初期内存分配器)。
为每个组分配物理内存
for (group = 0; group < ai->nr_groups; group++) {
...
ptr = pcpu_fc_alloc(cpu, gi->nr_units * ai->unit_size, atom_size, cpu_to_nd_fn);
areas[group] = ptr;
base = min(ptr, base);
...
}遍历每个组,调用
pcpu_fc_alloc为整个组分配一段连续物理内存(大小为组内单元数 * unit_size)。分配时可能考虑 NUMA 节点(通过
cpu_to_nd_fn获取 CPU 所在节点)。记录所有分配地址中的最小地址
base(即所有组内存的起始基址),以及地址最高的组(用于计算最大距离)。
复制静态数据
for (group = 0; group < ai->nr_groups; group++) {
for (i = 0; i < gi->nr_units; i++, ptr += ai->unit_size) {
if (gi->cpu_map[i] == NR_CPUS) {
pcpu_fc_free(ptr, ai->unit_size); // 未使用的单元(空洞),整块释放
continue;
}
memcpy(ptr, __per_cpu_load, ai->static_size); // 复制内核静态数据
pcpu_fc_free(ptr + size_sum, ai->unit_size - size_sum); // 释放单元尾部未使用的填充部分
}
}对于每个组内的每个单元(每个单元对应一个 CPU 或一个空洞):
如果是空洞(
cpu_map[i] == NR_CPUS),表示该单元没有对应的 CPU,因此整块释放。否则,将内核静态 per-cpu 数据(从符号
__per_cpu_load开始,大小为static_size)复制到该单元的开头。然后释放该单元中超出
size_sum的尾部填充部分(因为unit_size可能大于size_sum,多余部分用于对齐,现在可以归还)。
调用 pcpu_setup_first_chunk 完成最终设置
这是核心设置函数,将其作为单独一节剖析说明
pcpu_setup_first_chunk
pcpu_setup_first_chunk 函数是 Linux 内核 percpu 内存初始化流程中的第二步,它在 pcpu_build_alloc_info 生成分配信息后调用,根据该信息和分配的物理/虚拟地址,建立实际的 percpu 第一块内存区域(first chunk)。该函数负责:
校验输入参数的有效性;
分配并填充内部映射表(如
unit_map、unit_off);根据
ai中的分组信息计算每个 CPU 对应的单元偏移;初始化 percpu 块(chunk)管理结构;
设置全局 percpu 状态变量(如
pcpu_base_addr、pcpu_first_chunk等)。
函数原型与输入
void __init pcpu_setup_first_chunk(const struct pcpu_alloc_info *ai,
void *base_addr)ai:由pcpu_build_alloc_info构建的分配信息结构,包含静态大小、保留大小、动态大小、单元大小、分组信息等。base_addr:percpu 第一块区域的起始虚拟地址(线性映射地址),由调用者提供(例如__per_cpu_load或从 memblock 分配的物理内存的虚拟地址)。返回值:无,但会设置一系列全局 percpu 变量,并创建第一个 percpu 块。
局部变量定义与辅助宏
size_t size_sum = ai->static_size + ai->reserved_size + ai->dyn_size;
// ... 其他变量
#define PCPU_SETUP_BUG_ON(cond) ...size_sum是一个 CPU 单元的总需求大小(静态+保留+动态)。PCPU_SETUP_BUG_ON是一个条件检查宏,如果条件成立,则打印错误信息、dumpai内容并触发 BUG,用于在初始化阶段捕获致命错误。
输入校验(sanity checks)
一系列 PCPU_SETUP_BUG_ON 检查,确保 ai 和 base_addr 满足基本要求:
nr_groups > 0:至少有一个组。static_size > 0(SMP 下):必须有静态 percpu 变量。__per_cpu_start页对齐。base_addr非空且页对齐。unit_size >= size_sum且页对齐,且不小于PCPU_MIN_UNIT_SIZE。unit_size是PCPU_BITMAP_BLOCK_SIZE的倍数(用于位图管理)。dyn_size >= PERCPU_DYNAMIC_EARLY_SIZE且非零。reserved_size按最小分配粒度对齐。位图块大小与页大小的对齐关系合理(两者之一必须是另一个的倍数)。
调用
pcpu_verify_alloc_info(ai)验证分组信息的一致性(如 CPU 映射不重复、不越界等)。
这些检查确保后续操作的安全性。
分配内部映射表
alloc_size = ai->nr_groups * sizeof(group_offsets[0]);
group_offsets = memblock_alloc(alloc_size, SMP_CACHE_BYTES);
...
group_sizes = memblock_alloc(...);
unit_map = memblock_alloc(nr_cpu_ids * sizeof(unit_map[0]), ...);
unit_off = memblock_alloc(nr_cpu_ids * sizeof(unit_off[0]), ...);使用
memblock_alloc在早期内存分配器(boot阶段)中分配四个数组:group_offsets:每个组在虚拟地址空间中的基偏移(相对于base_addr)。group_sizes:每个组占用的总大小(nr_units * unit_size)。unit_map:将 CPU 编号映射到全局单元编号(unit index)。unit_off:每个 CPU 对应的单元在虚拟地址空间中的偏移(相对于base_addr)。
这些数组是全局 percpu 系统的核心数据结构,后续用于快速定位每个 CPU 的 percpu 数据区。
初始化 unit_map 并遍历分组填充映射
for (cpu = 0; cpu < nr_cpu_ids; cpu++)
unit_map[cpu] = UINT_MAX;
pcpu_low_unit_cpu = pcpu_high_unit_cpu = NR_CPUS;将
unit_map初始化为无效值UINT_MAX。pcpu_low_unit_cpu和pcpu_high_unit_cpu分别记录偏移最小和最大的 CPU,用于后续可能的范围优化。
接下来遍历所有组:
for (group = 0, unit = 0; group < ai->nr_groups; group++, unit += i) {
const struct pcpu_group_info *gi = &ai->groups[group];
group_offsets[group] = gi->base_offset;
group_sizes[group] = gi->nr_units * ai->unit_size;
for (i = 0; i < gi->nr_units; i++) {
cpu = gi->cpu_map[i];
if (cpu == NR_CPUS)
continue; // 空洞单元(对齐预留),不映射到真实 CPU
// 检查 CPU 合法性
PCPU_SETUP_BUG_ON(cpu >= nr_cpu_ids);
PCPU_SETUP_BUG_ON(!cpu_possible(cpu));
PCPU_SETUP_BUG_ON(unit_map[cpu] != UINT_MAX); // 不能重复映射
unit_map[cpu] = unit + i; // 全局单元编号
unit_off[cpu] = gi->base_offset + i * ai->unit_size; // 单元偏移
// 记录最低/最高偏移的 CPU
if (pcpu_low_unit_cpu == NR_CPUS ||
unit_off[cpu] < unit_off[pcpu_low_unit_cpu])
pcpu_low_unit_cpu = cpu;
if (pcpu_high_unit_cpu == NR_CPUS ||
unit_off[cpu] > unit_off[pcpu_high_unit_cpu])
pcpu_high_unit_cpu = cpu;
}
}这里
unit是全局单元计数器,i是该组内的单元索引。每个组中可能有空洞(cpu_map[i] = NR_CPUS),这些单元不分配给任何 CPU,但占据空间。对于每个有效的 CPU,记录其全局单元号和虚拟偏移。
最终
pcpu_nr_units = unit记录总单元数。
检查所有可能的 CPU 都有映射
for_each_possible_cpu(cpu)
PCPU_SETUP_BUG_ON(unit_map[cpu] == UINT_MAX);确保每个可能的 CPU 都被分配了一个有效的单元。
保存全局配置变量
pcpu_nr_groups = ai->nr_groups;
pcpu_group_offsets = group_offsets;
pcpu_group_sizes = group_sizes;
pcpu_unit_map = unit_map;
pcpu_unit_offsets = unit_off;
pcpu_unit_pages = ai->unit_size >> PAGE_SHIFT;
pcpu_unit_size = pcpu_unit_pages << PAGE_SHIFT; // 实际单元大小(页对齐)
pcpu_atom_size = ai->atom_size;
pcpu_chunk_struct_size = struct_size(chunk, populated,
BITS_TO_LONGS(pcpu_unit_pages));将局部数组指针赋给全局变量,供后续使用。
计算并保存单元大小(页数、字节数)、原子分配粒度、chunk 结构大小(包含位图数组)。
设置 chunk 管理槽位
pcpu_sidelined_slot = __pcpu_size_to_slot(pcpu_unit_size) + 1;
pcpu_free_slot = pcpu_sidelined_slot + 1;
pcpu_to_depopulate_slot = pcpu_free_slot + 1;
pcpu_nr_slots = pcpu_to_depopulate_slot + 1;
pcpu_chunk_lists = memblock_alloc(pcpu_nr_slots * sizeof(pcpu_chunk_lists[0]),
SMP_CACHE_BYTES);
...
for (i = 0; i < pcpu_nr_slots; i++)
INIT_LIST_HEAD(&pcpu_chunk_lists[i]);percpu 分配器使用多个 slot 来管理不同状态的 chunk(例如空闲、待清理等)。这里计算出特殊 slot 的索引并分配链表数组。
对齐静态区域并调整动态大小
static_size = ALIGN(ai->static_size, PCPU_MIN_ALLOC_SIZE);
dyn_size = ai->dyn_size - (static_size - ai->static_size);静态区域需要按最小分配粒度对齐,以便后续预留区域对齐。对齐后可能会增加一些大小,这些增加的部分从动态区域中扣除,保持总大小不变。
创建第一个 chunk
tmp_addr = (unsigned long)base_addr + static_size;
map_size = ai->reserved_size ?: dyn_size;
chunk = pcpu_alloc_first_chunk(tmp_addr, map_size);pcpu_alloc_first_chunk是一个辅助函数,用于创建一个 chunk,起始地址为tmp_addr,大小为map_size,并初始化其内部位图等。如果
reserved_size非零,则第一个 chunk 用于保留区域;否则第一个 chunk 直接用于动态区域。
if (ai->reserved_size) {
pcpu_reserved_chunk = chunk; // 将第一个 chunk 设为保留 chunk
tmp_addr = (unsigned long)base_addr + static_size + ai->reserved_size;
map_size = dyn_size;
chunk = pcpu_alloc_first_chunk(tmp_addr, map_size); // 再创建一个动态 chunk
}如果有保留区域,则需要两个 chunk:一个保留,一个动态。保留 chunk 保存后,再为动态区域创建一个新 chunk。
pcpu_first_chunk = chunk; // 指向动态区域 chunk(如果没有保留区域,则指向第一个 chunk)
pcpu_nr_empty_pop_pages = pcpu_first_chunk->nr_empty_pop_pages;
pcpu_chunk_relocate(pcpu_first_chunk, -1); // 将 chunk 放入合适的 slot
pcpu_nr_populated += PFN_DOWN(size_sum); // 统计已 populate 的页数
pcpu_stats_chunk_alloc();
trace_percpu_create_chunk(base_addr);
pcpu_base_addr = base_addr; // 保存基地址设置全局变量 pcpu_base_addr,至此 chunk 配置完成。
分析到这里,其实我们可以看到,虽然pcpu_setup_first_chunk函数名是first chunk,但是实际上会创建两个chunk。
第一个 chunk(由
pcpu_alloc_first_chunk创建):起始地址 =
base_addr + static_size(静态区之后)。大小 =
reserved_size(如果reserved_size > 0)或dyn_size(如果没有保留区)。如果
reserved_size > 0,这个 chunk 被赋值给pcpu_reserved_chunk,作为保留 chunk。
第二个 chunk(仅在
reserved_size > 0时创建):起始地址 = 保留区之后:
base_addr + static_size + reserved_size。大小 =
dyn_size。这个 chunk 被赋值给
pcpu_first_chunk,作为动态 chunk。
函数名中的“first chunk”指的是整个第一块 percpu 内存区域(即静态区 + 保留区 + 动态区),该区域可能被拆分成多个 chunk 来管理,但逻辑上仍属于初始化阶段的第一块内存。最终 pcpu_first_chunk 总是指向服务动态分配的那个 chunk,而 pcpu_reserved_chunk 指向保留 chunk。
总结
setup_per_cpu_areas 可以把它理解成:把 percpu 虚拟空间搭起来 + 把静态模板复制到per CPU + 把动态分配器(chunk)初始化好。
阶段 A:算大小与对齐(layout 参数)
它会得到并统一这些关键量(概念上):
static_size = __per_cpu_end - __per_cpu_start
→ 静态 per-cpu 变量模板区大小reserved_size
→ early boot 预留给动态 percpu 分配的空间(避免早期碎片)unit_size
→ 每个 CPU 的 unit 总大小(static + reserved + dynamic + 对齐/填充)atom_size/alloc_align等
→ 内部分配粒度与对齐约束(决定 bitmap 的粒度、block 的拆分方式)
这一步在代码里看到的很多“round_up/align/pow2”都属于这个阶段。
阶段 B:构造 pcpu_alloc_info(布局蓝图)
pcpu_alloc_info 解决两件事:
CPU 怎么分组(group)(通常跟 NUMA/拓扑有关)
每个 CPU 的 unit 在 percpu 虚拟空间里放在哪(offset)
最终产出最关键的东西之一就是:
pcpu_unit_offsets[cpu]
它会保证:
每个 CPU 的 unit 布局一致(同样的 static/reserved/dynamic 切分)
访问公式成立:
addr = pcpu_base_addr + pcpu_unit_offsets[cpu] + obj_offset
阶段 C:分配 percpu 虚拟空间并建立 first chunk
这一步会:
得到
pcpu_base_addr(percpu 虚拟空间的 base)创建并初始化
pcpu_first_chunk
pcpu_first_chunk是 percpu 动态分配器的第一个 arena:它管理一段“offset 空间”,这段 offset 同时对应所有 CPU unit 的动态区。
阶段 D:建立 reserved chunk(早期预留区)
然后会从 first chunk 里“切”出早期预留部分,建立:
pcpu_reserved_chunk
它的目标是:
early boot 的 percpu 动态分配尽量落在 reserved 区里
避免把后续常规 dynamic 区弄碎(也避免早期阶段依赖复杂回收)
阶段 E:把静态模板复制到每个 CPU 的 static 区
也就是把:
[__per_cpu_start, __per_cpu_end)的模板内容
复制到每个 CPU unit 对应位置:
unit_base(cpu) + static_offset
这样 DEFINE_PER_CPU() 的变量从此对所有 CPU 都“就位”。
阶段 F:让 arch 能“快速访问 percpu”(arm64 的 TPIDR_EL1)
最后会把每 CPU 的 percpu base(unit_base)用于 arch 侧设置:
arm64:把当前 CPU 的
unit_base写到TPIDR_EL1
之后this_cpu_ptr()就变成:mrs tpidr_el1+add offset
我们要申明一点的是,chunk 管“offset 空间”,不是管某个 CPU
当 alloc_percpu() 时:
分配器返回一个
obj_offset这个 offset 在 所有 CPU unit 上都有效
所以每 CPU 都在
unit_base(cpu) + obj_offset有一份对象
小实验
实验步骤:
定义一个 percpu 变量
给每个 CPU 写入不同的值
打印每个 CPU 上这个变量的地址
打印每个 CPU 上这个变量的值
这样可以直接观察:
不同 CPU 的地址差异
unit offset 的规律
percpu 变量的布局
// percpu_test.c
#include "linux/printk.h"
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/percpu.h>
#include <linux/smp.h>
#include <linux/cpu.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("percpu-test");
MODULE_DESCRIPTION("percpu memory layout test");
/* 定义一个 per-cpu 变量 */
DEFINE_PER_CPU(int, percpu_var);
DEFINE_PER_CPU(int, percpu_var2);
static int __init percpu_test_init(void)
{
int cpu;
pr_info("percpu_test: module loaded\n");
pr_info("__per_cpu_start: %px\n", __per_cpu_start);
pr_info("__per_cpu_end: %px\n", __per_cpu_end);
pr_info("pcpu_base_addr: %px\n", pcpu_base_addr);
pr_info("percpu_test: printing percpu addresses and values\n");
for_each_possible_cpu(cpu) {
int *addr;
int val;
addr = &per_cpu(percpu_var, cpu);
val = per_cpu(percpu_var, cpu);
pr_info("percpu_var - CPU %d: addr=%px value=%d\n", cpu, addr, val);
int *addr2;
int val2;
addr2 = &per_cpu(percpu_var2, cpu);
val2 = per_cpu(percpu_var2, cpu);
pr_info("percpu_var2 - CPU %d: addr=%px value=%d\n", cpu, addr2, val2);
}
/* 给每个 CPU 写入不同的值 */
for_each_possible_cpu(cpu) {
int *addr;
int val;
addr = &per_cpu(percpu_var, cpu);
val = per_cpu(percpu_var, cpu);
per_cpu(percpu_var, cpu) = cpu * 100;
}
pr_info("percpu_test: printing percpu addresses and values\n");
for_each_possible_cpu(cpu) {
int *addr;
int val;
addr = &per_cpu(percpu_var, cpu);
val = per_cpu(percpu_var, cpu);
pr_info("percpu_var - CPU %d: addr=%px value=%d\n", cpu, addr, val);
}
return 0;
}
static void __exit percpu_test_exit(void)
{
pr_info("percpu_test: module unloaded\n");
}
module_init(percpu_test_init);
module_exit(percpu_test_exit);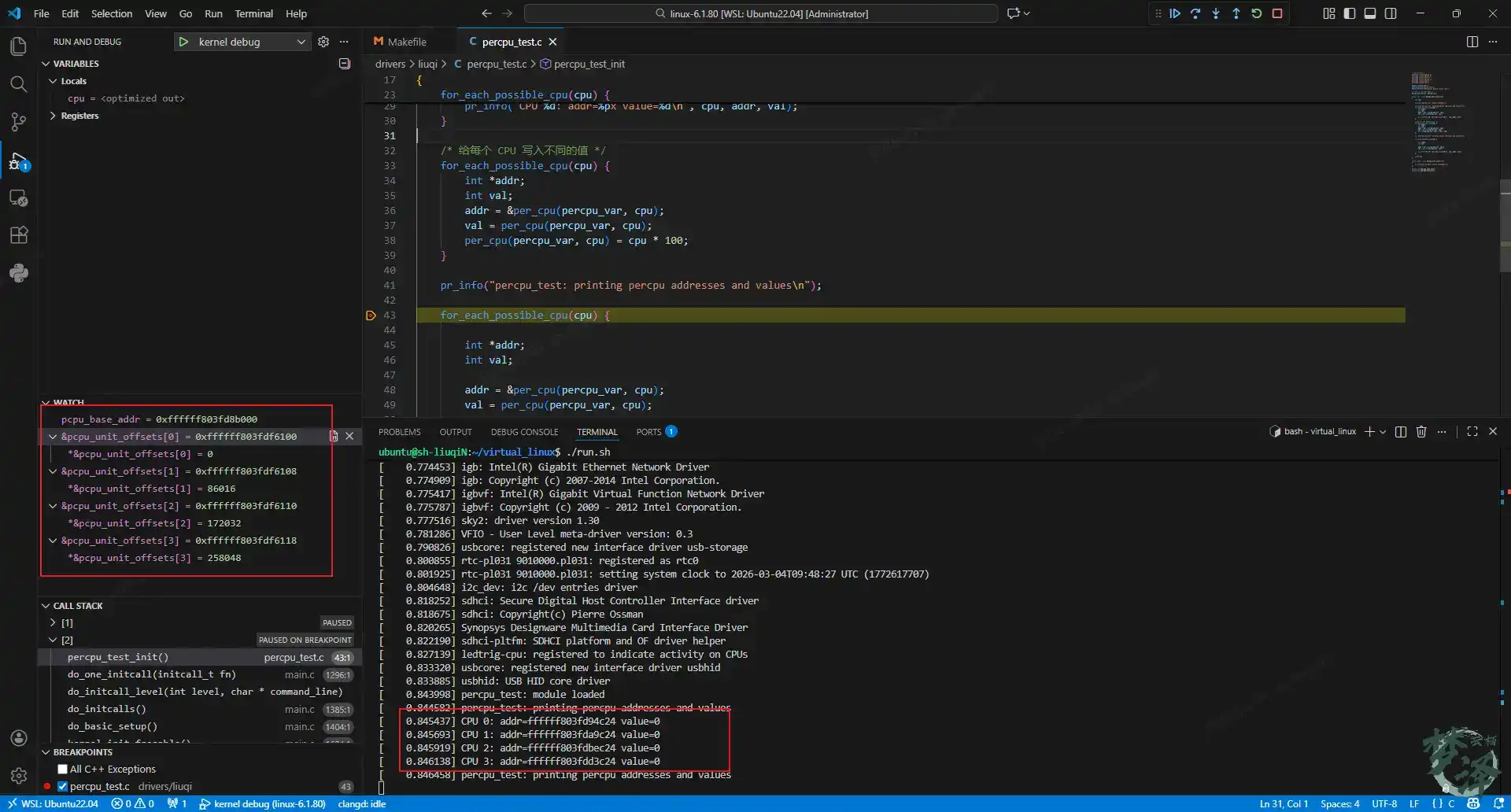
在 Linux 内核中,每个 per-CPU 变量(如本案例中的 percpu_var )在特定 CPU 上的地址是通过 编译时基地址 加上 该 CPU 的 per-CPU 数据区偏移量 计算得到的
每个 CPU 的区域相对于 CPU0 区域的偏移量被记录在一个全局数组 __per_cpu_offset[] 中。 pcpu_unit_offsets 数组就是这个偏移量数组
&pcpu_unit_offsets[0]=0xffffff803fdf6100
*(&pcpu_unit_offsets[0])=0
&pcpu_unit_offsets[1]=0xffffff803fdf6108
*(&pcpu_unit_offsets[1])=0x15000
&pcpu_unit_offsets[2]=0xffffff803fdf6110
*(&pcpu_unit_offsets[2])=0x2a000=0x15000*2
&pcpu_unit_offsets[3]=0xffffff803fdf6118
*(&pcpu_unit_offsets[3])=0x3f000=0x15000*3宏 per_cpu(percpu_var, cpu) 展开后的地址计算逻辑为
addr = (unsigned long)(&percpu_var) + __per_cpu_offset[cpu];其中 &percpu_var 就是 CPU0 上的地址(即编译时基地址,编译时已确定)。因此:
CPU1
percpu_var地址 =0xffffff803fd94c24+0x15000=0xffffff803fda9c24✅CPU2
percpu_var地址 =0xffffff803fd94c24+0x2a000=0xffffff803fdbec24✅CPU3
percpu_var地址 =0xffffff803fd94c24+0x3f000=0xffffff803fdd3c24✅
这个计算结果也和输出的日志保持一致!而且当我们定义了一个percpu_var变量后,直接读取可以看到这个变量在per-CPU中都被初始化为了0。
从上图的pcpu_base_addr = 0xffffff803fd8b000,又怎么理解呢?

[ 0.878314] __per_cpu_start: ffffffc009af0000
[ 0.878565] __per_cpu_end: ffffffc009afbb28
[ 0.878771] pcpu_base_addr: ffffff803fd8b000
[ 0.878993] percpu_test: printing percpu addresses and values
[ 0.879350] percpu_var - CPU 0: addr=ffffff803fd94c24 value=0
[ 0.879659] percpu_var2 - CPU 0: addr=ffffff803fd94c28 value=0对于变量percpu_var:
变量对于per cpu基地址的偏移为:0xffffff803fd94c24 - 0xffffff803fd8b000(pcpu_base_addr) = 0x9c24
变量percpu_var在各cpu上的地址
计算公式:
addr = pcpu_base_addr + pcpu_unit_offsets[cpu] + 偏移(0x9c24)
CPU0: pcpu_base_addr + 0 + 0x9c24 = 0xffffff803fd94c24
CPU1: pcpu_base_addr + 0x15000 + 0x9c24 = 0xffffff803fda9c24
CPU2: pcpu_base_addr + 0x2a000 + 0x9c24 = 0xffffff803fdbec24
CPU3: pcpu_base_addr + 0x3f000 + 0x9c24 = 0xffffff803fdd3c24
对于变量percpu_var2:
变量对于per cpu基地址的偏移为:0xffffff803fd94c28 - 0xffffff803fd8b000(pcpu_base_addr) = 0x9c28
变量percpu_var在各cpu上的地址
计算公式:
addr = pcpu_base_addr + pcpu_unit_offsets[cpu] + 偏移(0x9c28)
CPU0: pcpu_base_addr + 0 + 0x9c28 = 0xffffff803fd94c28
CPU1: pcpu_base_addr + 0x15000 + 0x9c28 = 0xffffff803fda9c28
CPU2: pcpu_base_addr + 0x2a000 + 0x9c28 = 0xffffff803fdbec28
CPU3: pcpu_base_addr + 0x3f000 + 0x9c28 = 0xffffff803fdd3c28
percpu_var2 在 CPU0 上的地址为 ffffff803fd94c28,比 percpu_var 高 4 字节,符合 int 类型大小,说明两个变量在模块的 percpu 段内是连续存放的。
然后每个per-CPU percpu_var变量分别赋值的输出结果
[ 0.844582] percpu_test: printing percpu addresses and values
[ 0.845437] CPU 0: addr=ffffff803fd94c24 value=0
[ 0.845693] CPU 1: addr=ffffff803fda9c24 value=0
[ 0.845919] CPU 2: addr=ffffff803fdbec24 value=0
[ 0.846138] CPU 3: addr=ffffff803fdd3c24 value=0
[ 0.846458] percpu_test: printing percpu addresses and values
[ 0.902621] CPU 0: addr=ffffff803fd94c24 value=0
[ 0.919498] CPU 1: addr=ffffff803fda9c24 value=100
[ 0.931415] CPU 2: addr=ffffff803fdbec24 value=200
[ 0.940844] CPU 3: addr=ffffff803fdd3c24 value=300在下一篇文章中,我们将聊聊我们提到的静态per-CPU,模块per-CPU以及动态per-CPU变量的概念!
敬请期待!
参考文档
https://justinwei.blog.csdn.net/article/details/134292241