
前言
在Linux操作系统中,内存管理子系统扮演着核心角色,而缺页中断(Page Fault)机制则是其实现虚拟内存管理的关键所在。当进程访问尚未映射到物理内存的虚拟地址时,处理器会触发缺页异常,引发操作系统介入处理——或分配物理页框,或从磁盘加载数据,或处理保护违规。这一机制不仅支撑着按需分页、写时复制、内存映射文件等高级特性,更是内存保护与共享的技术基础。
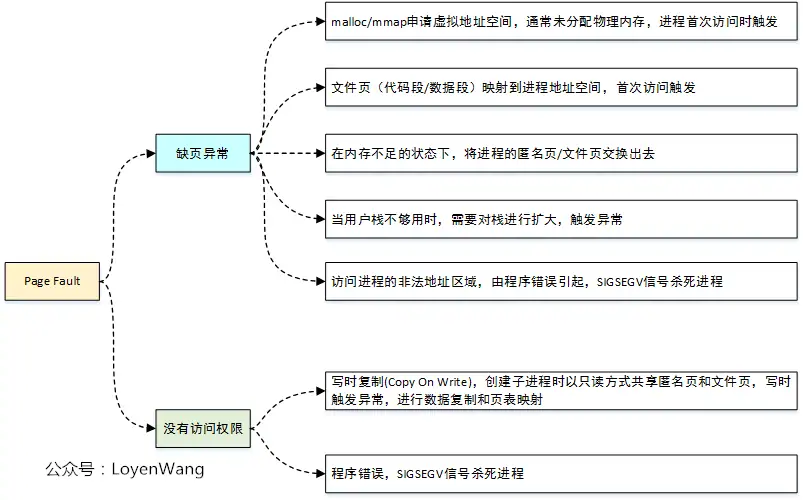
本文将从AArch64架构的特殊性出发,深入分析Linux内核中do_page_fault函数的实现细节,揭示缺页异常处理的完整流程。
AArch64异常处理框架概述
异常级别与向量表
AArch64架构定义了四个异常级别(EL0-EL3),其中EL0为用户模式,EL1为内核模式。当缺页异常发生时,处理器从EL0陷入EL1,保存现场到以下寄存器:
ESR_EL1:异常症状寄存器,包含异常原因代码
FAR_EL1:出错地址寄存器,保存触发异常的虚拟地址
ELR_EL1:异常链接寄存器,保存返回地址
SPSR_EL1:保存的程序状态寄存器

内核根据ESR_EL1中的EC(Exception Class)字段判断异常类型。对于数据访问异常,EC值为0b100101或0b100100(也就是0x25和0x21);对于指令获取异常,EC值为0b100000。(关于ESR_EL1的EC bit的解释,可查看[Android稳定性] 第022篇 [原理篇] kernel panic的死亡信息的由来)

页表格式与地址翻译
AArch64支持48位或52位虚拟地址空间,采用4级页表结构(PGD、PUD、PMD、PTE)。每个页表项大小为8字节,支持以下页面大小:
4KB页:每页4096字节,支持12位页内偏移
16KB页:每页16384字节,支持14位页内偏移
64KB页:每页65536字节,支持16位页内偏移
地址翻译过程采用两阶段机制:Stage 1将虚拟地址(VA)转换为中间物理地址(IPA),Stage 2将IPA转换为物理地址(PA)。在非虚拟化环境中,Stage 1直接输出PA。

缺页异常处理入口:从汇编到C的过渡
异常向量表入口
当处理器触发数据访问异常时,会跳转到异常向量表的对应条目。在arch/arm64/kernel/entry.S中定义了异常向量表:
// arch/arm64/kernel/entry.S
.align 11
SYM_CODE_START(vectors)
kernel_ventry 1, sync // Synchronous EL1t
kernel_ventry 1, irq // IRQ EL1t
// ...
kernel_ventry 0, sync // Synchronous 64-bit EL0
kernel_ventry 0, irq // IRQ 64-bit EL0
// ...
SYM_CODE_END(vectors)
这部分详细可在: aarch64异常模型以及Linux arm64中断处理,在这篇文章中那个详细介绍了异常向量表。
异常处理函数
ARM64把异常分为同步异常和异步异常,通常异步异常指的是中断,同步异常指的是异常。所以本文要讲的缺页异常是走的sync异常向量处理入口。
以el1下的异常为例,当跳转到el1_sync函数时
#define ESR_ELx_EC_SHIFT (26)
#define ESR_ELx_EC_MASK (UL(0x3F) << ESR_ELx_EC_SHIFT)
#define ESR_ELx_EC(esr) (((esr) & ESR_ELx_EC_MASK) >> ESR_ELx_EC_SHIFT) //ESR寄存器右移26bit后取低6位,也就是EC值
asmlinkage void noinstr el1h_64_sync_handler(struct pt_regs *regs)
{
unsigned long esr = read_sysreg(esr_el1);
//printk("---esr:0x%x, at line-%d\n",ESR_ELx_EC(esr),__LINE__);
switch (ESR_ELx_EC(esr)) { ///读取esr_el1的EC域,判断异常类型
case ESR_ELx_EC_DABT_CUR: ///0x25,表示来自当前的异常等级的数据异常
case ESR_ELx_EC_IABT_CUR:
el1_abort(regs, esr); ///数据异常入口
break;
/*
* We don't handle ESR_ELx_EC_SP_ALIGN, since we will have hit a
* recursive exception when trying to push the initial pt_regs.
*/
case ESR_ELx_EC_PC_ALIGN:
el1_pc(regs, esr);
break;
case ESR_ELx_EC_SYS64:
case ESR_ELx_EC_UNKNOWN:
el1_undef(regs);
break;
case ESR_ELx_EC_BREAKPT_CUR:
case ESR_ELx_EC_SOFTSTP_CUR:
case ESR_ELx_EC_WATCHPT_CUR:
case ESR_ELx_EC_BRK64:
el1_dbg(regs, esr);
break;
case ESR_ELx_EC_FPAC:
el1_fpac(regs, esr);
break;
default:
__panic_unhandled(regs, "64-bit el1h sync", esr);
}
}
根据第2.1提到的EC值为0x25或者0x21,所以此处将会走到el1_abort函数进行处理
static void noinstr el1_abort(struct pt_regs *regs, unsigned long esr)
{
unsigned long far = read_sysreg(far_el1); ///从far_el1读取出现异常的虚拟地址
enter_from_kernel_mode(regs);
local_daif_inherit(regs);
do_mem_abort(far, esr, regs); ///异常处理函数
local_daif_mask();
exit_to_kernel_mode(regs);
}
走到do_mem_abort进行处理
缺页异常核心处理函数
do_mem_abort
/************************************************************************************
* 缺页中断处理函数
* 参数:
* far: 出错虚拟地址
* esr: ESR_EL1值
* regs: 异常发生时的堆栈指针
************************************************************************************/
void do_mem_abort(unsigned long far, unsigned int esr, struct pt_regs *regs)
{
const struct fault_info *inf = esr_to_fault_info(esr); ///根据DFSC字段值,查询fault_info表,获取相应的处理函数
unsigned long addr = untagged_addr(far);
if (!inf->fn(far, esr, regs)) ///执行esr_to_fault_info获取的函数
return;
if (!user_mode(regs)) {
pr_alert("Unhandled fault at 0x%016lx\n", addr);
mem_abort_decode(esr);
show_pte(addr);
}
/*
* At this point we have an unrecognized fault type whose tag bits may
* have been defined as UNKNOWN. Therefore we only expose the untagged
* address to the signal handler.
*/
arm64_notify_die(inf->name, regs, inf->sig, inf->code, addr, esr); ///如果没找到相应处理函数,打印出错信息
}
static inline const struct fault_info *esr_to_fault_info(unsigned int esr)
{
return fault_info + (esr & ESR_ELx_FSC); ///根据ESR_ELx_FSC字段,选择处理函数
}
该函数主要是根据传进来的esr获取fault_info信息,从而去调用函数inf->fn。esr & ESR_ELx_FSC就是取ESR寄存器的低6位

static const struct fault_info fault_info[] = {
{ do_bad, SIGKILL, SI_KERNEL, "ttbr address size fault" },
{ do_bad, SIGKILL, SI_KERNEL, "level 1 address size fault" },
{ do_bad, SIGKILL, SI_KERNEL, "level 2 address size fault" },
{ do_bad, SIGKILL, SI_KERNEL, "level 3 address size fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 0 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 1 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 2 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 3 translation fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 8" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 access flag fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 12" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 permission fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 permission fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 permission fault" },
{ do_sea, SIGBUS, BUS_OBJERR, "synchronous external abort" },
{ do_tag_check_fault, SIGSEGV, SEGV_MTESERR, "synchronous tag check fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 18" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 19" },
{ do_sea, SIGKILL, SI_KERNEL, "level 0 (translation table walk)" },
{ do_sea, SIGKILL, SI_KERNEL, "level 1 (translation table walk)" },
//...
}
do_translation_fault: 出现0/1/2/3级页表转换错误时调用
do_page_fault:出现1/2/3级页表访问权限时调用
do_bad:其它错误
...
以do_translation_fault为例,
static int __kprobes do_translation_fault(unsigned long far,
unsigned int esr,
struct pt_regs *regs)
{
unsigned long addr = untagged_addr(far);
// 如果 `addr` 是 `TTBR0` 地址(即用户空间的地址)
if (is_ttbr0_addr(addr))
return do_page_fault(far, esr, regs);
// 该函数处理的是与 **内核空间** 地址相关的异常,如访问非法内核地址等错误
do_bad_area(far, esr, regs);
return 0;
}
由此,我们来到了缺页异常的核心处理函数do_page_fault
do_page_fault
static int __kprobes do_page_fault(unsigned long far, unsigned int esr,
struct pt_regs *regs)
{
const struct fault_info *inf;
struct mm_struct *mm = current->mm;
vm_fault_t fault;
unsigned long vm_flags;
unsigned int mm_flags = FAULT_FLAG_DEFAULT;
unsigned long addr = untagged_addr(far);
if (kprobe_page_fault(regs, esr))
return 0;
/*
* If we're in an interrupt or have no user context, we must not take
* the fault.
*/
///检查异常发生时的路径, 若不合条件,直接跳转no_context,出错处理
if (faulthandler_disabled() || !mm) ///是否关闭缺页中断,是否在中断上下文,是否内核空间,内核进程的mm总是NULL
goto no_context;
if (user_mode(regs))
mm_flags |= FAULT_FLAG_USER;
/*
* vm_flags tells us what bits we must have in vma->vm_flags
* for the fault to be benign, __do_page_fault() would check
* vma->vm_flags & vm_flags and returns an error if the
* intersection is empty
*/
if (is_el0_instruction_abort(esr)) { ///判断是否为低异常等级的指令异常,若为指令异常,说明该地址具有可执行权限
/* It was exec fault */
vm_flags = VM_EXEC;
mm_flags |= FAULT_FLAG_INSTRUCTION;
} else if (is_write_abort(esr)) { ///写内存区错误
/* It was write fault */
vm_flags = VM_WRITE;
mm_flags |= FAULT_FLAG_WRITE;
} else {
/* It was read fault */
vm_flags = VM_READ;
/* Write implies read */
vm_flags |= VM_WRITE;
/* If EPAN is absent then exec implies read */
if (!cpus_have_const_cap(ARM64_HAS_EPAN))
vm_flags |= VM_EXEC;
}
///判断是否为用户空间,是否EL1权限错误,都满足时,表明处于少见的特殊情况,直接报错处理
if (is_ttbr0_addr(addr) && is_el1_permission_fault(addr, esr, regs)) {
if (is_el1_instruction_abort(esr))
///指令错误
die_kernel_fault("execution of user memory",
addr, esr, regs);
///数据异常,搜索异常表
if (!search_exception_tables(regs->pc))
die_kernel_fault("access to user memory outside uaccess routines",
addr, esr, regs);
}
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, addr);
/*
* As per x86, we may deadlock here. However, since the kernel only
* validly references user space from well defined areas of the code,
* we can bug out early if this is from code which shouldn't.
*/
///执行到这里,可以断定缺页异常没有发生在中断上下文,没有发生在内核线程,以及一些特殊情况;接下来检查由于地址空间引发的缺页异常
if (!mmap_read_trylock(mm)) {
if (!user_mode(regs) && !search_exception_tables(regs->pc))
goto no_context;
retry:
mmap_read_lock(mm); ///睡眠,等待锁释放
} else {
/*
* The above mmap_read_trylock() might have succeeded in which
* case, we'll have missed the might_sleep() from down_read().
*/
might_sleep();
#ifdef CONFIG_DEBUG_VM
if (!user_mode(regs) && !search_exception_tables(regs->pc)) {
mmap_read_unlock(mm);
goto no_context;
}
#endif
}
///进一步处理缺页以异常
fault = __do_page_fault(mm, addr, mm_flags, vm_flags, regs);
///有挂起致命信号
/* Quick path to respond to signals */
if (fault_signal_pending(fault, regs)) {
///内核空间
if (!user_mode(regs))
goto no_context;
return 0;
}
if (fault & VM_FAULT_RETRY) {
if (mm_flags & FAULT_FLAG_ALLOW_RETRY) {
mm_flags |= FAULT_FLAG_TRIED;
goto retry;
}
}
//...
}
这个函数略写了,主要调用__do_page_fault
static vm_fault_t __do_page_fault(struct mm_struct *mm, unsigned long addr,
unsigned int mm_flags, unsigned long vm_flags,
struct pt_regs *regs)
{
struct vm_area_struct *vma = find_vma(mm, addr); ///查找失效地址addr对应的vma
if (unlikely(!vma)) ///找不到vma,说明addr还没在进程地址空间中,返回VM_FAULT_BADMAP
return VM_FAULT_BADMAP; //表示该地址无效或不在当前进程的映射范围内。
/*
* Ok, we have a good vm_area for this memory access, so we can handle
* it.
*/
if (unlikely(vma->vm_start > addr)) { ///vm_start>addr,特殊情况(栈,向下增长),检查能否vma扩展到addr,否则报错
if (!(vma->vm_flags & VM_GROWSDOWN))
return VM_FAULT_BADMAP;
if (expand_stack(vma, addr))
return VM_FAULT_BADMAP;
}
/*
* Check that the permissions on the VMA allow for the fault which
* occurred.
*/
if (!(vma->vm_flags & vm_flags)) ///判断vma属性,无权限,直接返回
return VM_FAULT_BADACCESS;
return handle_mm_fault(vma, addr, mm_flags, regs); ///缺页中断处理的核心处理函数
}
通过检查虚拟地址是否有效,是否属于当前进程的映射范围,是否有访问权限等,最终调用 handle_mm_fault() 来执行具体的缺页处理。
handle_mm_fault
vm_fault_t handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags, struct pt_regs *regs)
{
vm_fault_t ret;
// 将当前进程的状态设置为 `TASK_RUNNING`,表明进程已经准备好继续运行
__set_current_state(TASK_RUNNING);
// 统计缺页事件
count_vm_event(PGFAULT);
count_memcg_event_mm(vma->vm_mm, PGFAULT);
/* do counter updates before entering really critical section. */
check_sync_rss_stat(current);
if (!arch_vma_access_permitted(vma, flags & FAULT_FLAG_WRITE,
flags & FAULT_FLAG_INSTRUCTION,
flags & FAULT_FLAG_REMOTE))
return VM_FAULT_SIGSEGV;
/*
* Enable the memcg OOM handling for faults triggered in user
* space. Kernel faults are handled more gracefully.
*/
if (flags & FAULT_FLAG_USER)
mem_cgroup_enter_user_fault();
// 如果访问的虚拟内存区域使用了 大页(hugepage),则调用 `hugetlb_fault()` 来处理此类特定的缺页异常。
if (unlikely(is_vm_hugetlb_page(vma)))
ret = hugetlb_fault(vma->vm_mm, vma, address, flags);
else
ret = __handle_mm_fault(vma, address, flags); // 实际的缺页处理函数,它负责分配物理页面、更新页表等操作
// 处理用户空间的 OOM 情况
if (flags & FAULT_FLAG_USER) {
mem_cgroup_exit_user_fault();
/*
* The task may have entered a memcg OOM situation but
* if the allocation error was handled gracefully (no
* VM_FAULT_OOM), there is no need to kill anything.
* Just clean up the OOM state peacefully.
*/
if (task_in_memcg_oom(current) && !(ret & VM_FAULT_OOM))
mem_cgroup_oom_synchronize(false);
}
// 更新内存管理(MM)统计信息
mm_account_fault(regs, address, flags, ret);
return ret;
}
它负责处理页面故障,并根据不同的情况(如用户空间、内核空间、大页、访问权限等)选择不同的处理路径。它会进行权限检查、内存控制组的管理、以及对大页和常规页故障的处理。最终,它会调用其他函数来修复缺页问题,更新内存管理统计,并返回相应的结果。
__handle_mm_fault
static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
struct vm_fault vmf = { ///构建vma描述结构体
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
unsigned int dirty = flags & FAULT_FLAG_WRITE;
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
vm_fault_t ret;
pgd = pgd_offset(mm, address); ///计算pgd页表项
p4d = p4d_alloc(mm, pgd, address); ///计算p4d页表项,这里等于pgd
if (!p4d)
return VM_FAULT_OOM;
vmf.pud = pud_alloc(mm, p4d, address); ///计算pud页表项
if (!vmf.pud)
return VM_FAULT_OOM;
retry_pud:
// 处理透明大页
if (pud_none(*vmf.pud) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pud(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
pud_t orig_pud = *vmf.pud;
barrier();
if (pud_trans_huge(orig_pud) || pud_devmap(orig_pud)) {
/* NUMA case for anonymous PUDs would go here */
if (dirty && !pud_write(orig_pud)) {
ret = wp_huge_pud(&vmf, orig_pud);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pud_set_accessed(&vmf, orig_pud);
return 0;
}
}
}
vmf.pmd = pmd_alloc(mm, vmf.pud, address); ///计算pmd页表项
if (!vmf.pmd)
return VM_FAULT_OOM;
/* Huge pud page fault raced with pmd_alloc? */
if (pud_trans_unstable(vmf.pud))
goto retry_pud;
if (pmd_none(*vmf.pmd) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pmd(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
vmf.orig_pmd = *vmf.pmd;
barrier();
if (unlikely(is_swap_pmd(vmf.orig_pmd))) {
VM_BUG_ON(thp_migration_supported() &&
!is_pmd_migration_entry(vmf.orig_pmd));
if (is_pmd_migration_entry(vmf.orig_pmd))
pmd_migration_entry_wait(mm, vmf.pmd);
return 0;
}
if (pmd_trans_huge(vmf.orig_pmd) || pmd_devmap(vmf.orig_pmd)) {
if (pmd_protnone(vmf.orig_pmd) && vma_is_accessible(vma))
return do_huge_pmd_numa_page(&vmf);
if (dirty && !pmd_write(vmf.orig_pmd)) {
ret = wp_huge_pmd(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pmd_set_accessed(&vmf);
return 0;
}
}
}
return handle_pte_fault(&vmf); ///进入通用代码处理
}
__handle_mm_fault() 是内核中处理缺页异常的核心函数。它通过逐级查找页表项(PGD、PUD、PMD)来处理不同层级的页故障。如果无法在 PUD 或 PMD 层找到合适的映射,它会继续通过页表项(PTE)处理来解决缺页问题。
handle_pte_fault
///缺页异常通用部分代码
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) {
/*
* Leave __pte_alloc() until later: because vm_ops->fault may
* want to allocate huge page, and if we expose page table
* for an instant, it will be difficult to retract from
* concurrent faults and from rmap lookups.
*/
vmf->pte = NULL;
} else {
/*
* If a huge pmd materialized under us just retry later. Use
* pmd_trans_unstable() via pmd_devmap_trans_unstable() instead
* of pmd_trans_huge() to ensure the pmd didn't become
* pmd_trans_huge under us and then back to pmd_none, as a
* result of MADV_DONTNEED running immediately after a huge pmd
* fault in a different thread of this mm, in turn leading to a
* misleading pmd_trans_huge() retval. All we have to ensure is
* that it is a regular pmd that we can walk with
* pte_offset_map() and we can do that through an atomic read
* in C, which is what pmd_trans_unstable() provides.
*/
if (pmd_devmap_trans_unstable(vmf->pmd))
return 0;
/*
* A regular pmd is established and it can't morph into a huge
* pmd from under us anymore at this point because we hold the
* mmap_lock read mode and khugepaged takes it in write mode.
* So now it's safe to run pte_offset_map().
*/
vmf->pte = pte_offset_map(vmf->pmd, vmf->address); ///计算pte页表项
vmf->orig_pte = *vmf->pte; ///读取pte内容到vmf->orig_pte
/*
* some architectures can have larger ptes than wordsize,
* e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and
* CONFIG_32BIT=y, so READ_ONCE cannot guarantee atomic
* accesses. The code below just needs a consistent view
* for the ifs and we later double check anyway with the
* ptl lock held. So here a barrier will do.
*/
barrier(); ///有的处理器PTE会大于字长,所以READ_ONCE()不能保证原子性,添加内存屏障以保证正确读取了PTE内容
if (pte_none(vmf->orig_pte)) {
pte_unmap(vmf->pte);
vmf->pte = NULL;
}
}
///pte为空
if (!vmf->pte) {
// 判断vma的vm_ops是否存在?如果vm_ops不存在即为匿名映射
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf); ///处理匿名映射
else
return do_fault(vmf); ///文件映射
}
///pte不为空
if (!pte_present(vmf->orig_pte)) ///pte存在,但是不在内存中,从交换分区读回页面
return do_swap_page(vmf);
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma)) ///处理numa调度页面
return do_numa_page(vmf);
vmf->ptl = pte_lockptr(vmf->vma->vm_mm, vmf->pmd);
spin_lock(vmf->ptl);
entry = vmf->orig_pte;
if (unlikely(!pte_same(*vmf->pte, entry))) {
update_mmu_tlb(vmf->vma, vmf->address, vmf->pte);
goto unlock;
}
if (vmf->flags & FAULT_FLAG_WRITE) { ///FAULT_FLAG_WRITE标志,根据ESR_ELx_WnR设置
if (!pte_write(entry))
return do_wp_page(vmf); ///vma可写,pte只读,触发缺页异常,父子进程共享的内存,写时复制
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry); ///访问标志位错误,设置PTE_AF位
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry, ///更新PTE和缓存
vmf->flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vmf->vma, vmf->address, vmf->pte);
} else {
/* Skip spurious TLB flush for retried page fault */
if (vmf->flags & FAULT_FLAG_TRIED)
goto unlock;
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (vmf->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address);
}
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
}
这里就不接下去介绍了,接下去的内容我会在单独的篇章中叙述!
总结
AArch64架构下的缺页异常处理是Linux内存管理系统的核心组成部分,它巧妙地将硬件特性与软件设计相结合。通过对do_page_fault函数的深入分析,我们可以看到Linux内核如何:
分层处理异常:从汇编入口到C语言核心,再到具体处理函数,形成清晰的处理层次
适应多样场景:支持用户空间、内核空间、文件映射、匿名映射等多种场景
优化性能:通过COW、透明大页、并发控制等技术提升系统性能
保证安全性:严格检查访问权限,防止非法内存访问

参考文档
【原创】(十四)Linux内存管理之page fault处理