
在本章正式内容开始之前,我们依然回顾一下以往的内容:
第一个阶段:Fixmap 固定映射阶段
setup_arch() → early_fixmap_init()
建立 fixmap 区域
通过 fixmap 可以动态建立更多页表项
此时内存管理: memblock(物理内存位图管理)
第二阶段:线性映射阶段
paging_init() → map_memory()
将所有物理内存线性映射到内核虚拟地址空间
映射关系: virt_addr = phys_addr + PAGE_OFFSET
此后,内核就可以通过虚拟地址访问所有的物理内存
第三阶段:Buddy 分配器初始化
mem_init() → free_area_init()
遍历 memblock 获取所有空闲物理内存信息
建立 free_area[] 数据结构
将可用页面加入 buddy 空闲链表
输出: 页面级分配器 ready,可以 alloc_pages()/free_pages()
第四阶段:Slab 分配器初始化
kmem_cache_init
静态变量: boot_kmem_cache, boot_kmem_cache_node
用 buddy 分配页面给第一个 slab
创建核心缓存:建立
kmem_cache和kmem_cache_node的对象缓存构建缓存体系:创建完整的 kmalloc 缓存族
输出:对象级缓存分配器 ready,可以kmalloc
第五阶段:Vmalloc内存分配初始化
vmalloc_init
调用入口:
start_kernel()→mm_init()→vmalloc_init()核心任务:初始化内核的“稀疏”虚拟地址空间管理器,此阶段并非分配物理内存,而是**建立虚拟地址空间的管理框架**,为后
vmalloc()vmap()ioremap()等函数动态建立“非连续”或“特殊”映射做准备。初始化管理结构:
struct vmap_area:用于描述一段已使用或空闲的vmalloc虚拟地址区间。vmap_area_cachep:vmap_area结构体创建一个专用的Slab缓存(此时Slab分配器已就绪)。将整个vmalloc地址空间初始化为一个大的空闲区间,并插入到红黑树
vmap_area_root)和链表free_vmap_area_list)中,以便高效地分配和回收虚拟地址。
建立页表基础:确
init_mm(内核主内存描述符)的页表目录指针pgd)已经涵盖vmalloc区域。实际上,paging_init()阶段建立线性映射的页表时,已经为vmalloc区域预留了顶级页表项,此时主要是完成管理框架的搭建。
各层职责:
Fixmap:保留用于特殊场景的动态映射,提供早期动态创建页表的能力
线性映射:提供物理到虚拟地址的直接转换,内核可以“看见”所有内存
Buddy:管理物理页面,按 2^order 分配连续页面,页面级的物理内存分配器建立
Slab:在Buddy之上,管理小对象缓存,快速分配/释放
Vmalloc初始化:建立虚拟地址空间管理器,为动态映射提供支持
至此,Linux内核内存管理从无到有的核心初始化链条已经清晰。在理解了内核内存管理的基本架构后,我们来关注一个在特定场景下至关重要的扩展组件:CMA
问题的根源
许多硬件设备(如GPU、摄像头、视频编解码器、显示控制器等)在进行DMA(直接内存访问) 操作时,由于硬件设计限制或性能要求,必须使用大块的、物理地址连续的内存。
然而,在传统的Linux内存管理机制下,长期运行的系统会面临严重的内存碎片化问题:
Buddy分配器虽能高效分配2的幂次方个连续页面,但无法抵御外部碎片。
即使系统有总计1GB的空闲内存,可能也无法分配出一个连续的4MB物理块,因为空闲页面被零散地分隔开了。
当然我们之前也提到过Reserved-memory的概念,那是不是我们提前将这部分的内存预留出来,那么在这些设备需要分配内存时就可以有足够的内存进行分配了呢?事实上是可以的!但是存在一个问题,当这些模块不再使用时,这块内存仍然无法被释放掉给其他模块使用,这块内存就浪费掉了。
所以为了解决这个问题,内核提出了(Contiguous Memory Allocator,CMA)的机制。
CMA的设计哲学
CMA提供了一种巧妙的解决方案,其核心思想是:“保留,但平时共享”。
预留内存:在系统启动早期(通常通过设备树或内核命令行参数),物理上预留出一块连续的物理内存区域。
共享使用:在系统正常运行期间,这块预留区域并不闲置。它被标记为
MIGRATE_CMA迁移类型,可以被普通的可移动页面(如用户进程的匿名页、文件页缓存)使用。这意味着CMA区域在日常情况下为系统总内存容量做出了贡献。按需回收:当设备驱动调用
cma_alloc()请求连续内存时,内核会:尝试从CMA区域中分配。
如果区域已被可移动页面占用,则触发页面迁移和内存规整,将这些页面移出CMA区域,搬迁到系统的其他地方。
最终腾出所需的连续物理块,交给设备使用。
此外,CMA 还可以与 DMA 子 系统集成 在一起,使用 DMA 的设备驱动程序无需使用单独的 CMA API。
这里也需要特别申明一点:连续内存分配器(CMA)是一个框架,它允许为物理连续内存管理设置特定于计算机的配置。然后根据该配置分配设备的内存。该框架的主要作用不是分配内存,而是解析和管理内存配置,并充当设备驱动程序和可插拔分配器之间的中介。因此,它不依赖于任何内存分配方法或策略。
CMA的数据结构
struct cma
mm/cma.h
struct cma {
unsigned long base_pfn;
unsigned long count;
unsigned long *bitmap;
unsigned int order_per_bit; /* Order of pages represented by one bit */
struct mutex lock;
#ifdef CONFIG_CMA_DEBUGFS
struct hlist_head mem_head;
spinlock_t mem_head_lock;
#endif
const char *name;
};
extern struct cma cma_areas[MAX_CMA_AREAS];
extern unsigned cma_area_count;
base_pfn:CMA区域物理地址的起始页帧号;count:CMA区域总体的页数;*bitmap:位图,用于描述页的分配情况;表示该页块free,bit 位上为1,表示页块已经分配。页块的大小与 order_per_bit 有关;order_per_bit:位图中每个bit描述的物理页面的order值,其中页面数为2^order值;name:该CMA 区域名称,如果来自 dts 配置的reserved-memory 节点,该属性就是节点名称
cma_areas[MAX_CMA_AREAS]
mm/cma.h
extern struct cma cma_areas[MAX_CMA_AREAS];
extern unsigned cma_area_count;
每个 struct cma 抽象出一个 CMA area,标识一个物理地址连续的 memory area。调用 cma_alloc() 分配连续内存就是从 CMA area 中获得。具体多少个 CMA area 是由系统配置决定的(也就是说内核系统可以配置多个 CMA 区域)
#ifdef CONFIG_CMA_AREAS
#define MAX_CMA_AREAS (1 + CONFIG_CMA_AREAS)
#else
#define MAX_CMA_AREAS (0)
#endif
CONFIG_CMA_AREAS 默认配置为 16 ,即 cma area 这样的连续内存区域,最多支持17个。

这里贴一个loyenWang绘制的图
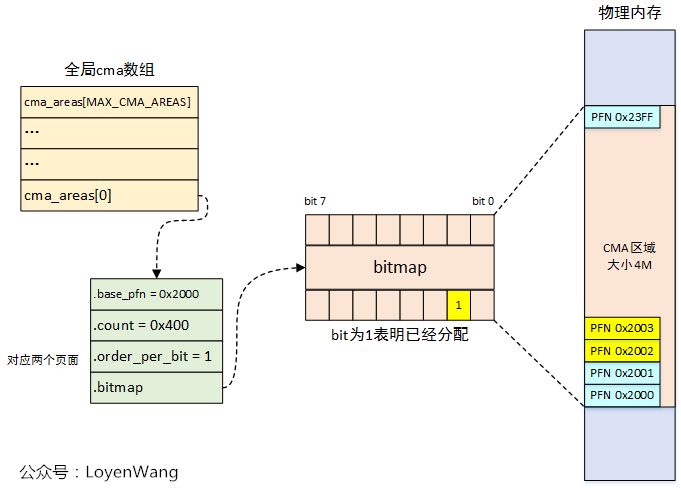
从图中示例得知,该 cma 区域的其实页帧号为 0x2000,共有 0x400个pages,因为 order_per_bit 为1,即bitmap 中每个 bit 位标记连续 2^1 个pages 的状态(0 为空闲,1为已分配)。
房子建好了,但是还空着,要想金屋藏娇,还需要一个CMA配置过程。配置CMA内存区有两种方法,一种是通过dts的reserved memory,另外一种是通过command line参数和内核配置参数。
内核初始化过程中的CMA
CMA的初始化巧妙地穿插在内核启动过程中,是一个横跨多个阶段的协作过程。
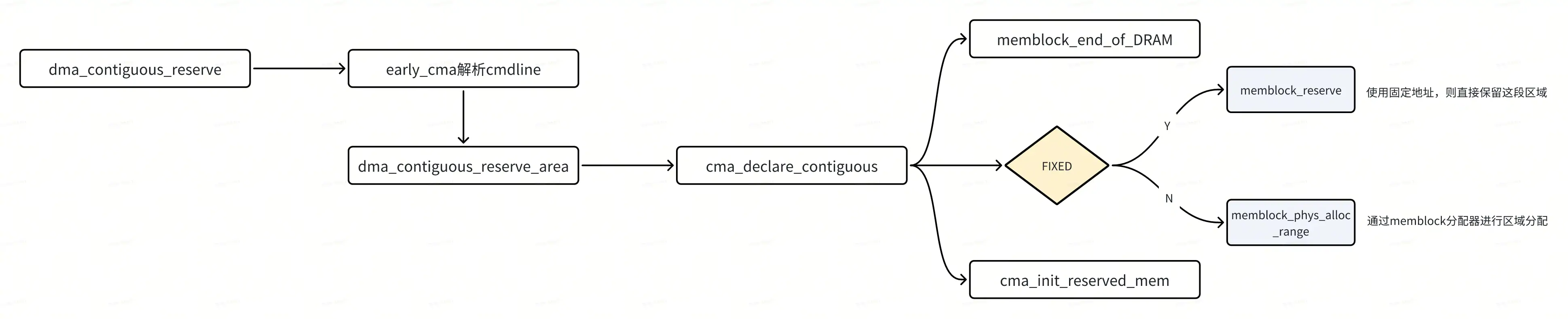
CMA区域的创建
通过cmdline参数创建
start_kernel -> setup_arch -> bootmem_init -> dma_contiguous_reserve
通过
dma_contiguous_reserve()解析设备树或命令行中的cma=参数,确定CMA区域的位置和大小。此时只是计算和保留,不进行实际管理结构初始化。
void __init dma_contiguous_reserve(phys_addr_t limit)
{
phys_addr_t selected_size = 0;
phys_addr_t selected_base = 0;
phys_addr_t selected_limit = limit;
bool fixed = false;
pr_debug("%s(limit %08lx)\n", __func__, (unsigned long)limit);
if (size_cmdline != -1) {
selected_size = size_cmdline;
selected_base = base_cmdline;
selected_limit = min_not_zero(limit_cmdline, limit);
if (base_cmdline + size_cmdline == limit_cmdline)
fixed = true;
} else {
#ifdef CONFIG_CMA_SIZE_SEL_MBYTES
selected_size = size_bytes;
#elif defined(CONFIG_CMA_SIZE_SEL_PERCENTAGE)
selected_size = cma_early_percent_memory();
#elif defined(CONFIG_CMA_SIZE_SEL_MIN)
selected_size = min(size_bytes, cma_early_percent_memory());
#elif defined(CONFIG_CMA_SIZE_SEL_MAX)
selected_size = max(size_bytes, cma_early_percent_memory());
#endif
}
if (selected_size && !dma_contiguous_default_area) {
pr_debug("%s: reserving %ld MiB for global area\n", __func__,
(unsigned long)selected_size / SZ_1M);
dma_contiguous_reserve_area(selected_size, selected_base,
selected_limit,
&dma_contiguous_default_area,
fixed);
}
}
如果内核命令行中指定了CMA参数(如
cma=64M@0x10000000)则完全使用命令行指定的参数:
size_cmdline: 从命令行解析的大小base_cmdline: 从命令行解析的基地址limit_cmdline: 从命令行解析的限制地址
如果
基地址+大小=限制地址,则标记为fixed(固定位置)调用
dma_contiguous_reserve_area()实际预留内存dma_contiguous_default_area是全局的默认CMA区域指针
解析cmdline参数
static int __init early_cma(char *p)
{
if (!p) {
pr_err("Config string not provided\n");
return -EINVAL;
}
size_cmdline = memparse(p, &p);
if (*p != '@')
return 0;
base_cmdline = memparse(p + 1, &p);
if (*p != '-') {
limit_cmdline = base_cmdline + size_cmdline;
return 0;
}
limit_cmdline = memparse(p + 1, &p);
return 0;
}
early_param("cma", early_cma);
没啥好说的,就是解析cmdline中的cma参数
dma_contiguous_reserve_area预留内存
int __init dma_contiguous_reserve_area(phys_addr_t size, phys_addr_t base,
phys_addr_t limit, struct cma **res_cma,
bool fixed)
{
int ret;
ret = cma_declare_contiguous(base, size, limit, 0, 0, fixed,
"reserved", res_cma);
if (ret)
return ret;
/* Architecture specific contiguous memory fixup. */
dma_contiguous_early_fixup(cma_get_base(*res_cma),
cma_get_size(*res_cma));
return 0;
}
cma_declare_contiguous,这是预留cma内存的核心函数,详细的代码这里就不继续分析了,这里记录下 cma_declare_contiguous() 处理过程
通过 memblock_end_of_DRAM() 确认末端地址,防止越界;
确认 cma_area_count 是否达到了最大,如果达到最大数(MAX_CMA_AREAS),则表示 CMA 区域已经达到上限,详细看上面第 1.2 节;
确认地址对齐值 alignment,初始值为 0,后面会根据 PAGE_SIZE 确认页块的大小,按照 4K 计算 alignment 的值为 4M;
对齐确认,先确认base、size、limit 的地址对齐,并纠正;接着需要确认size 页数是否与 order_per_bit 对应的页数对齐;
确认该区域是否已经添加到 memblock reserved 区域;
通过 cma_init_reserved_mem() 进行 cma area 初始化;
int __init cma_init_reserved_mem(phys_addr_t base, phys_addr_t size,
unsigned int order_per_bit,
const char *name,
struct cma **res_cma)
{
struct cma *cma;
/* Sanity checks */
if (cma_area_count == ARRAY_SIZE(cma_areas)) {
pr_err("Not enough slots for CMA reserved regions!\n");
return -ENOSPC;
}
if (!size || !memblock_is_region_reserved(base, size))
return -EINVAL;
/* ensure minimal alignment required by mm core */
if (!IS_ALIGNED(base | size, CMA_MIN_ALIGNMENT_BYTES))
return -EINVAL;
/*
* Each reserved area must be initialised later, when more kernel
* subsystems (like slab allocator) are available.
*/
cma = &cma_areas[cma_area_count];
if (name)
snprintf(cma->name, CMA_MAX_NAME, name);
else
snprintf(cma->name, CMA_MAX_NAME, "cma%d\n", cma_area_count);
cma->base_pfn = PFN_DOWN(base);
cma->count = size >> PAGE_SHIFT;
cma->order_per_bit = order_per_bit;
*res_cma = cma;
cma_area_count++;
totalcma_pages += (size / PAGE_SIZE);
return 0;
}
这段就是cma_area的成员初始化的地方
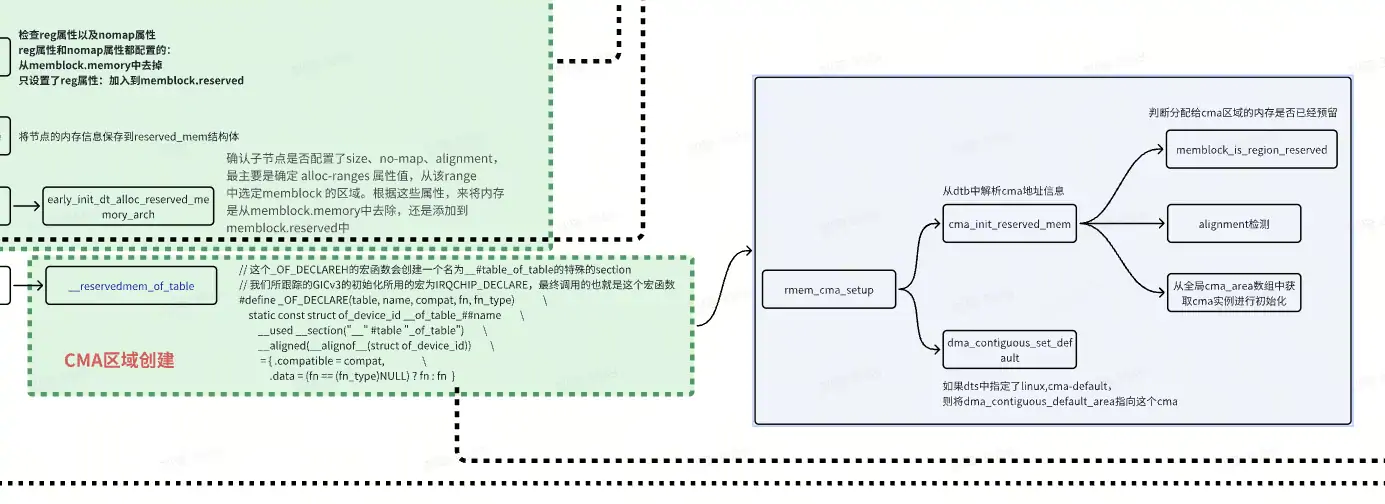
通过DTS对CMA区域进行配置
&reserved_memory {
dump_mem: mem_dump_region {
compatible = "shared-dma-pool";
alloc-ranges = <0x0 0x00000000 0x0 0xffffffff>;
reusable;
size = <0 0x800000>;
};
};
在dtb解析过程中,会调用到rmem_cma_setup函数:
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
static int __init rmem_cma_setup(struct reserved_mem *rmem)
{
unsigned long node = rmem->fdt_node;
bool default_cma = of_get_flat_dt_prop(node, "linux,cma-default", NULL);
struct cma *cma;
int err;
if (size_cmdline != -1 && default_cma) {
pr_info("Reserved memory: bypass %s node, using cmdline CMA params instead\n",
rmem->name);
return -EBUSY;
}
// CMA配置需要reusable,不能no-map
if (!of_get_flat_dt_prop(node, "reusable", NULL) ||
of_get_flat_dt_prop(node, "no-map", NULL))
return -EINVAL;
if (!IS_ALIGNED(rmem->base | rmem->size, CMA_MIN_ALIGNMENT_BYTES)) {
pr_err("Reserved memory: incorrect alignment of CMA region\n");
return -EINVAL;
}
// //CMA创建的核心函数
err = cma_init_reserved_mem(rmem->base, rmem->size, 0, rmem->name, &cma);
if (err) {
pr_err("Reserved memory: unable to setup CMA region\n");
return err;
}
/* Architecture specific contiguous memory fixup. */
dma_contiguous_early_fixup(rmem->base, rmem->size);
//确认该节点是否配置了linux,cma-default这个属性
//如果配置了这个属性,会将刚创建好的cma保存为default cma area
if (default_cma)
dma_contiguous_default_area = cma;
rmem->ops = &rmem_cma_ops;
rmem->priv = cma;
pr_info("Reserved memory: created CMA memory pool at %pa, size %ld MiB\n",
&rmem->base, (unsigned long)rmem->size / SZ_1M);
return 0;
}
如果一个 reserved memory 需要配置为 CMA 内存,则要求节点属性必须配置 reusable,且节点属性不能配置 no-map
在内核中注册 shared-dma-pool 的地方有两处:
kernel/dma/coherent.c
RESERVEDMEM_OF_DECLARE(dma, "shared-dma-pool", rmem_dma_setup);
kernel/dma/contiguous.c
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
如果是dma 内存,则 dts 中不能有 reusable 属性;
如果是cma 内存,则 dts 中必须有reusable,不能有no-map 属性;
开机日志中的CMA日志
[ 0.000000][ T0] OF: reserved mem: 0x00000001fffff000..0x00000001ffffffff (4 KiB) nomap non-reusable debug_kinfo_region
[ 0.000000][ T0] Reserved memory: created DMA memory pool at 0x00000000ff400000, size 8 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node rmtfs_region, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000ff400000..0x00000000ffbfffff (8192 KiB) nomap non-reusable rmtfs_region
[ 0.000000][ T0] Reserved memory: created CMA memory pool at 0x00000000fec00000, size 8 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node mem_dump_region, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000fec00000..0x00000000ff3fffff (8192 KiB) map reusable mem_dump_region
[ 0.000000][ T0] Reserved memory: created CMA memory pool at 0x00000000fdc00000, size 16 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node qseecom_ta_region, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000fdc00000..0x00000000febfffff (16384 KiB) map reusable qseecom_ta_region
[ 0.000000][ T0] Reserved memory: created CMA memory pool at 0x00000000fcc00000, size 16 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node va_md_mem_region, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000fcc00000..0x00000000fdbfffff (16384 KiB) map reusable va_md_mem_region
[ 0.000000][ T0] Reserved memory: created CMA memory pool at 0x00000000fac00000, size 32 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node linux,cma, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000fac00000..0x00000000fcbfffff (32768 KiB) map reusable linux,cma
[ 0.000000][ T0] Reserved memory: created CMA memory pool at 0x00000000f5000000, size 92 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node secure_display_region, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000f5000000..0x00000000fabfffff (94208 KiB) map reusable secure_display_region
[ 0.000000][ T0] Reserved memory: created DMA memory pool at 0x00000000f4800000, size 8 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node memshare_region, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000f4800000..0x00000000f4ffffff (8192 KiB) nomap non-reusable memshare_region
[ 0.000000][ T0] Reserved memory: created CMA memory pool at 0x00000000f3400000, size 20 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node qseecom_region, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000f3400000..0x00000000f47fffff (20480 KiB) map reusable qseecom_region
[ 0.000000][ T0] Reserved memory: created CMA memory pool at 0x00000000ed800000, size 92 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node non_secure_display_region, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000ed800000..0x00000000f33fffff (94208 KiB) map reusable non_secure_display_region
[ 0.000000][ T0] Reserved memory: created CMA memory pool at 0x00000000ed000000, size 8 MiB
[ 0.000000][ T0] OF: reserved mem: initialized node adsp_region, compatible id shared-dma-pool
[ 0.000000][ T0] OF: reserved mem: 0x00000000ed000000..0x00000000ed7fffff (8192 KiB) map reusable adsp_region
[ 0.000000][ T0] OF: reserved mem: 0x0000000080000000..0x00000000805fffff (6144 KiB) nomap non-reusable hyp_region@80000000
[ 0.000000][ T0] OF: reserved mem: 0x0000000080700000..0x00000000807fffff (1024 KiB) nomap non-reusable xblboot_region@80700000
[ 0.000000][ T0] OF: reserved mem: 0x0000000080880000..0x0000000080883fff (16 KiB) nomap non-reusable reserved_region@80880000
[ 0.000000][ T0] OF: reserved mem: 0x0000000080884000..0x0000000080893fff (64 KiB) nomap non-reusable minidump_uefixbl_region@80884000
[ 0.000000][ T0] OF: reserved mem: 0x0000000080900000..0x0000000080afffff (2048 KiB) nomap non-reusable smem@80900000
[ 0.000000][ T0] OF: reserved mem: 0x0000000080b00000..0x0000000080bfffff (1024 KiB) nomap non-reusable cpucp_fw_region@80b00000
[ 0.000000][ T0] OF: reserved mem: 0x0000000080c00000..0x0000000081afffff (15360 KiB) nomap non-reusable cdsp_secure_heap_region@80c00000
[ 0.000000][ T0] OF: reserved mem: 0x0000000085200000..0x0000000085dfffff (12288 KiB) map non-reusable splash_region
[ 0.000000][ T0] OF: reserved mem: 0x0000000085e00000..0x0000000085efffff (1024 KiB) map non-reusable dfps_data_region
[ 0.000000][ T0] OF: reserved mem: 0x0000000086500000..0x00000000866fffff (2048 KiB) nomap non-reusable wlan_region@86500000
[ 0.000000][ T0] OF: reserved mem: 0x0000000086700000..0x0000000088cfffff (38912 KiB) nomap non-reusable adsp_region@86700000
[ 0.000000][ T0] OF: reserved mem: 0x0000000088d00000..0x000000008aafffff (30720 KiB) nomap non-reusable cdsp_region@88d00000
[ 0.000000][ T0] OF: reserved mem: 0x000000008ab00000..0x000000008b1fffff (7168 KiB) nomap non-reusable video_region@8ab00000
[ 0.000000][ T0] OF: reserved mem: 0x000000008b200000..0x000000008b20ffff (64 KiB) nomap non-reusable ipa_fw_region@8b200000
[ 0.000000][ T0] OF: reserved mem: 0x000000008b210000..0x000000008b219fff (40 KiB) nomap non-reusable ipa_gsi_region@8b210000
[ 0.000000][ T0] OF: reserved mem: 0x000000008b21a000..0x000000008b21bfff (8 KiB) nomap non-reusable gpu_microcode_region@8b21a000
[ 0.000000][ T0] OF: reserved mem: 0x000000008b800000..0x000000009b7fffff (262144 KiB) nomap non-reusable mpsswlan_region@8b800000
[ 0.000000][ T0] OF: reserved mem: 0x00000000c0000000..0x00000000c00fffff (1024 KiB) nomap non-reusable tz_stat_region@c0000000
[ 0.000000][ T0] OF: reserved mem: 0x00000000c0100000..0x00000000c12fffff (18432 KiB) nomap non-reusable tags_region@c0100000
[ 0.000000][ T0] OF: reserved mem: 0x00000000c1300000..0x00000000c17fffff (5120 KiB) nomap non-reusable qtee_region@c1300000
[ 0.000000][ T0] OF: reserved mem: 0x00000000c1800000..0x00000000c574ffff (64832 KiB) nomap non-reusable trusted_apps_region@c1800000
[ 0.000000][ T0] OF: reserved mem: 0x00000000d0000000..0x00000000d01fffff (2048 KiB) map non-reusable ramoops@d0000000
CMA内存整合到buddy系统
在创建完CMA区域后,该内存区域成了保留区域,如果单纯给驱动使用,显然会造成内存的浪费,因此内存管理模块会将CMA区域添加到Buddy System中,用于可移动页面的分配和管理。CMA区域是通过cma_init_reserved_areas接口来添加到Buddy System中的。
start_kernel()
├── setup_arch() // 架构相关初始化
│ └── dma_contiguous_reserve() // 阶段1:CMA物理内存预留
│ └── dma_contiguous_reserve_area()
│ └── cma_declare_contiguous()
│
├── mm_init() // 内存管理初始化
│ ├── mem_init() // 内存初始化
│ │ └── free_area_init() // 阶段3:Buddy分配器初始化
│ └── kmem_cache_init() // 阶段4:Slab分配器初始化
│
└── arch_call_rest_init()
└── rest_init()
└── kernel_init()
└── do_basic_setup()
└── do_initcalls() // 执行所有初始化调用
到do_initcalls后,cma_init_reserved_areas开始启动
static int __init cma_init_reserved_areas(void)
{
int i;
for (i = 0; i < cma_area_count; i++)
cma_activate_area(&cma_areas[i]);
return 0;
}
core_initcall(cma_init_reserved_areas);
cma_activate_area是核心函数
static void __init cma_activate_area(struct cma *cma)
{
unsigned long base_pfn = cma->base_pfn, pfn;
struct zone *zone;
// 分配一个位图来跟踪CMA区域内每个页面的分配状态
cma->bitmap = bitmap_zalloc(cma_bitmap_maxno(cma), GFP_KERNEL);
if (!cma->bitmap)
goto out_error;
/*
* alloc_contig_range() requires the pfn range specified to be in the
* same zone. Simplify by forcing the entire CMA resv range to be in the
* same zone.
*/
// CMA区域必须完全位于同一个内存管理区(zone)中
// 因为`alloc_contig_range()`要求操作在单个zone内
WARN_ON_ONCE(!pfn_valid(base_pfn));
zone = page_zone(pfn_to_page(base_pfn));
for (pfn = base_pfn + 1; pfn < base_pfn + cma->count; pfn++) {
WARN_ON_ONCE(!pfn_valid(pfn));
if (page_zone(pfn_to_page(pfn)) != zone)
goto not_in_zone;
}
for (pfn = base_pfn; pfn < base_pfn + cma->count;
pfn += pageblock_nr_pages)
// 遍历所有的pfn,初始化CMA页面块
init_cma_reserved_pageblock(pfn_to_page(pfn));
spin_lock_init(&cma->lock);
#ifdef CONFIG_CMA_DEBUGFS
INIT_HLIST_HEAD(&cma->mem_head);
spin_lock_init(&cma->mem_head_lock);
#endif
return;
not_in_zone:
//...
init_cma_reserved_pageblock() 的关键操作
#ifdef CONFIG_CMA
/* Free whole pageblock and set its migration type to MIGRATE_CMA. */
void __init init_cma_reserved_pageblock(struct page *page)
{
unsigned i = pageblock_nr_pages;
struct page *p = page;
do {
// 清除PageReserved标志位,这些页面之前被memblock标记为reserved
// 只有清除了,后续buddy才能管理这些页面
__ClearPageReserved(p);
set_page_count(p, 0);
} while (++p, --i);
// 将整个pageblock的迁移类型设置为MIGRATE_CMA
set_pageblock_migratetype(page, MIGRATE_CMA);
set_page_refcounted(page);
// 释放页面到Buddy系统
__free_pages(page, pageblock_order);
adjust_managed_page_count(page, pageblock_nr_pages);
page_zone(page)->cma_pages += pageblock_nr_pages;
}
#endif
这个函数将一个完整的pageblock(通常是多个连续页面):
从预留状态释放
标记为CMA迁移类型
MIGRATE_CMA页面:可以被普通的内存分配使用
但可以在需要时被迁移走
添加到Buddy系统的空闲列表中
更新内存管理统计信息
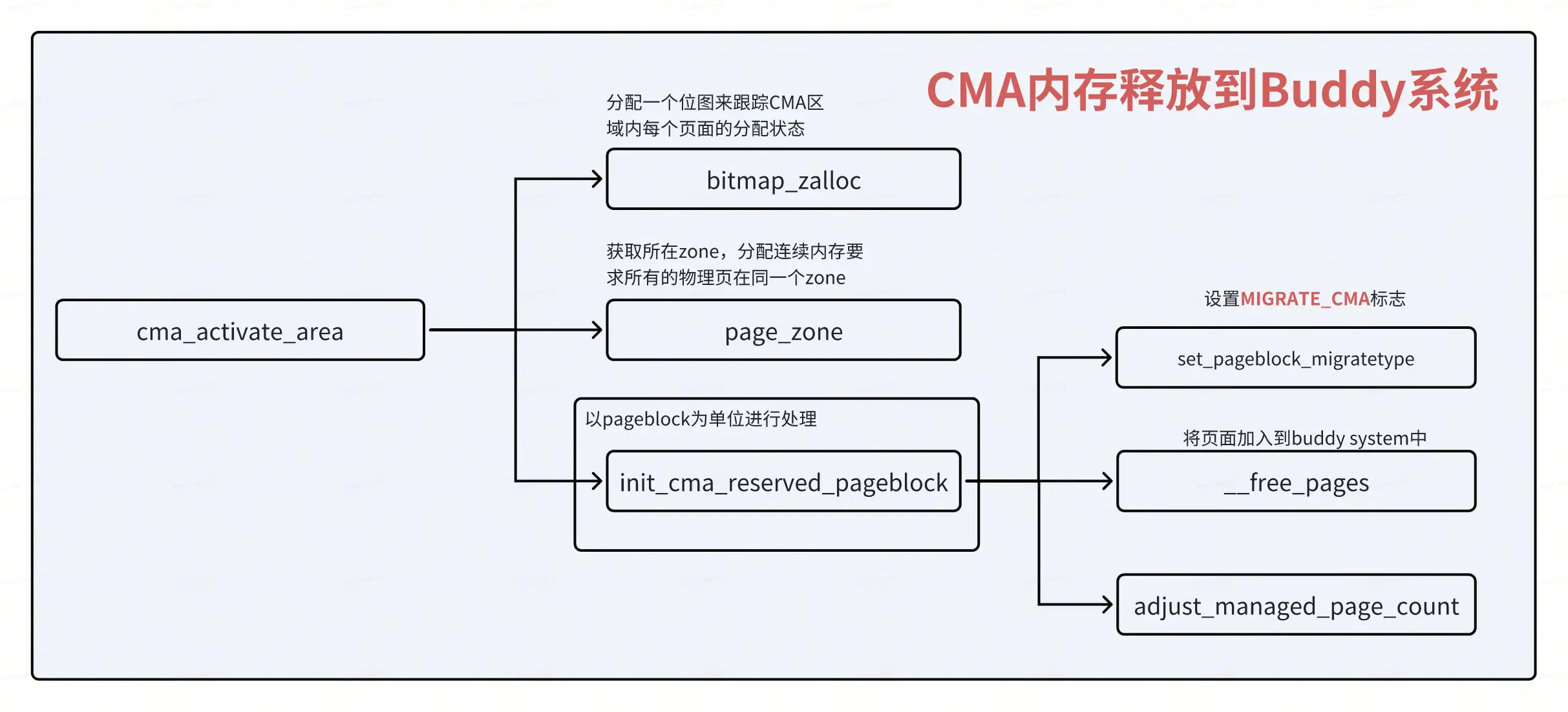
页面的状态变迁
物理内存被识别
memblock.reserved标记CMA区域
init_cma_reserved_pageblock()调用
页面从reserved → free (MIGRATE_CMA)
Buddy系统可以分配这些页面
CMA内存的申请与释放
上面阐述了CMA 分配器中核心数组 cma_areas 的创建过程,这一章节着重剖析 CMA 分配器的分配、释放流程,对应接口是 cma_alloc() 函数、cma_release() 函数
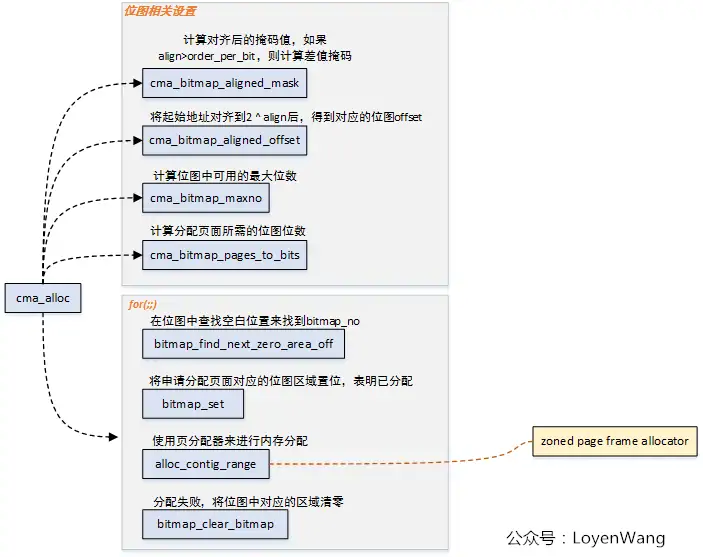
cma_alloc分配内存
struct page *cma_alloc(struct cma *cma, unsigned long count,
unsigned int align, bool no_warn)
{
return __cma_alloc(cma, count, align, GFP_KERNEL |
(no_warn ? __GFP_NOWARN : 0));
}
调用 __cma_alloc
struct page *__cma_alloc(struct cma *cma, unsigned long count,
unsigned int align, gfp_t gfp_mask)
{
unsigned long mask, offset;
unsigned long pfn = -1;
unsigned long start = 0;
unsigned long bitmap_maxno, bitmap_no, bitmap_count;
unsigned long i;
struct page *page = NULL;
int ret = -ENOMEM;
int num_attempts = 0;
int max_retries = 5;
const char *name = cma ? cma->name : NULL;
// trace打点
trace_cma_alloc_start(name, count, align);
if (WARN_ON_ONCE((gfp_mask & GFP_KERNEL) == 0 ||
(gfp_mask & ~(GFP_KERNEL|__GFP_NOWARN|__GFP_NORETRY)) != 0))
goto out;
if (!cma || !cma->count || !cma->bitmap)
goto out;
pr_debug("%s(cma %p, count %lu, align %d)\n", __func__, (void *)cma,
count, align);
if (!count)
goto out;
// 计算对齐后的掩码值,如果align>order_per_bit,则计算差值掩码
mask = cma_bitmap_aligned_mask(cma, align);
//先找到base pfn按照align之后的偏移,进而找到对应的bitmap中的bit偏移
offset = cma_bitmap_aligned_offset(cma, align);
//根据cmd->count获取bitmap中的bit实际最大位置
bitmap_maxno = cma_bitmap_maxno(cma);
//与maxno有点不同,count需要先按照1<<order_per_bit对齐后,再确认bit最大值
bitmap_count = cma_bitmap_pages_to_bits(cma, count);
// 要求cma->count必须按照cma->order_per_bit对齐进行配置,且不能超过最大内存
if (bitmap_count > bitmap_maxno)
goto out;
for (;;) {
spin_lock_irq(&cma->lock);
1.
/**
*从cma->bitmap 中寻找连续bitmap_count个为0的bit区域,并返回bitmap no
* 注意参数start是相对于cma->bitmap的offset,起始为0,如果找不到目标区域,start会重新
* 进行计算,见for循环结尾处理
*/
bitmap_no = bitmap_find_next_zero_area_off(cma->bitmap,
bitmap_maxno, start, bitmap_count, mask,
offset);
if (bitmap_no >= bitmap_maxno) {
if ((num_attempts < max_retries) && (ret == -EBUSY)) {
spin_unlock_irq(&cma->lock);
if (fatal_signal_pending(current) ||
(gfp_mask & __GFP_NORETRY))
break;
/*
* Page may be momentarily pinned by some other
* process which has been scheduled out, e.g.
* in exit path, during unmap call, or process
* fork and so cannot be freed there. Sleep
* for 100ms and retry the allocation.
*/
start = 0;
ret = -ENOMEM;
schedule_timeout_killable(msecs_to_jiffies(100));
num_attempts++;
continue;
} else {
spin_unlock_irq(&cma->lock);
break;
}
}
//将查找到的连续bit设置为1,表示内存被分配占用
bitmap_set(cma->bitmap, bitmap_no, bitmap_count);
/*
* It's safe to drop the lock here. We've marked this region for
* our exclusive use. If the migration fails we will take the
* lock again and unmark it.
*/
spin_unlock_irq(&cma->lock);
//计算准备分配的内存的起始页的页号
pfn = cma->base_pfn + (bitmap_no << cma->order_per_bit);
mutex_lock(&cma_mutex);
//分配从起始页开始的连续count个页,分配的migrate type为MIGRATE_CMA类型
ret = alloc_contig_range(pfn, pfn + count, MIGRATE_CMA, gfp_mask);
mutex_unlock(&cma_mutex);
if (ret == 0) {
page = pfn_to_page(pfn);
break;
}
cma_clear_bitmap(cma, pfn, count);
if (ret != -EBUSY)
break;
pr_debug("%s(): memory range at %p is busy, retrying\n",
__func__, pfn_to_page(pfn));
trace_cma_alloc_busy_retry(cma->name, pfn, pfn_to_page(pfn),
count, align);
/* try again with a bit different memory target */
start = bitmap_no + mask + 1;
}
/*
* CMA can allocate multiple page blocks, which results in different
* blocks being marked with different tags. Reset the tags to ignore
* those page blocks.
*/
if (page) {
for (i = 0; i < count; i++)
page_kasan_tag_reset(nth_page(page, i));
}
if (ret && !(gfp_mask & __GFP_NOWARN)) {
pr_err_ratelimited("%s: %s: alloc failed, req-size: %lu pages, ret: %d\n",
__func__, cma->name, count, ret);
cma_debug_show_areas(cma);
}
pr_debug("%s(): returned %p\n", __func__, page);
out:
trace_cma_alloc_finish(name, pfn, page, count, align);
if (page) {
count_vm_event(CMA_ALLOC_SUCCESS);
cma_sysfs_account_success_pages(cma, count);
} else {
count_vm_event(CMA_ALLOC_FAIL);
if (cma)
cma_sysfs_account_fail_pages(cma, count);
}
return page;
}
分配总结
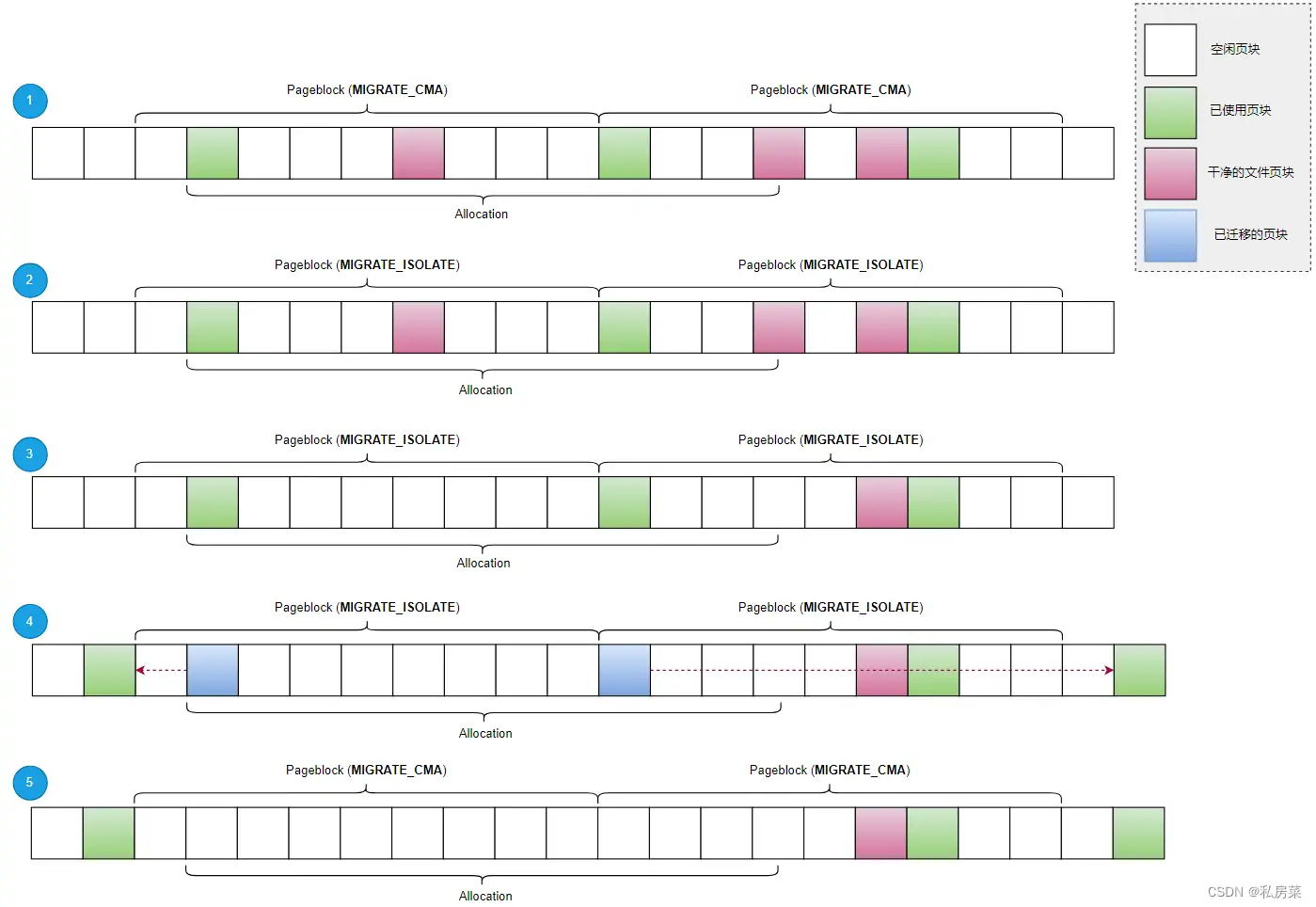
将 cma 分配过程通过 5 张图阐述总结,核心逻辑都在 alloc_contig_range() 函数中:
图1, 此时 CMA 的内存正在被非 cma 驱动使用,其中绿色表示普通页面,紫色表示干净的文件页,此时内存还是 MIGRATE_CMA 类型;
图2, 调用 start_isolate_page_range() 函数,将预分配区域的页块进行隔离,migrate type 改成 MIGRATE_ISOLATE,以防止其他进程从此区域中分配内存;
图3、图4, 调用 __alloc_contig_migrate_range() 函数,将隔离区域进行迁移。图3 是将干净的文件页块进行回收,调用 shrink_page_list() 函数;图4 是将无法回收的内存进行迁移,调用migrate_pages()函数;
图5, 在执行完 __alloc_contig_migrate_range() 函数之后,会将预分配区域的内存都从 free_area中移除,清除 PageBuddy 的印记,并将之前隔离的页块重新设成 MIGRATE_CMA;
如果上面都正确完成,在 cma_alloc() 中会将起始 pfn 转换成 struct page 指针,返回给调用者。
cma_release释放内存
/**
* cma_release() - release allocated pages
* @cma: Contiguous memory region for which the allocation is performed.
* @pages: Allocated pages.
* @count: Number of allocated pages.
*
* This function releases memory allocated by alloc_cma().
* It returns false when provided pages do not belong to contiguous area and
* true otherwise.
*/
bool cma_release(struct cma *cma, const struct page *pages,
unsigned long count)
{
unsigned long pfn;
if (!cma_pages_valid(cma, pages, count))
return false;
pr_debug("%s(page %p, count %lu)\n", __func__, (void *)pages, count);
pfn = page_to_pfn(pages);
VM_BUG_ON(pfn + count > cma->base_pfn + cma->count);
free_contig_range(pfn, count);
cma_clear_bitmap(cma, pfn, count);
trace_cma_release(cma->name, pfn, pages, count);
return true;
}
cma_relase相比较于cma_alloc简单需要,主要就是调用free_contig_range进行页面回收
void free_contig_range(unsigned long pfn, unsigned long nr_pages)
{
unsigned long count = 0;
for (; nr_pages--; pfn++) {
struct page *page = pfn_to_page(pfn);
count += page_count(page) != 1;
__free_page(page);
}
WARN(count != 0, "%lu pages are still in use!\n", count);
}
就是利用buddy分配器的 __free_page 释放页面
演示DEMO
CMA区域创建日志
[ 0.000000] cma: Reserved 256 MiB at 0x000000006ec00000
DEMO驱动加载日志
[ 1.002543] cma_demo: loaded. /dev/cma_demo cma=0x9f15758
demo代码
demo驱动代码
// SPDX-License-Identifier: GPL-2.0
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/miscdevice.h>
#include <linux/mm.h>
#include <linux/uaccess.h>
#include <linux/mutex.h>
#include <linux/highmem.h>
#include <linux/vmalloc.h>
#include <linux/dma-map-ops.h>
#include <linux/cma.h> /* cma_alloc/cma_release */
#include <linux/highmem.h> // kmap_local_page
//#include <linux/dma-contiguous.h> /* dev_get_cma_area() */
#include "cma_uapi.h"
#define DRV_NAME "cma_demo"
struct cma_demo_ctx {
struct device *dev;
struct cma *cma;
struct page *base_page; /* first page of contiguous block */
size_t size; /* bytes */
unsigned long count; /* pages */
phys_addr_t phys; /* physical address of base_page */
struct mutex lock;
};
static struct cma_demo_ctx g;
static void cma_demo_free_locked(struct cma_demo_ctx *ctx)
{
if (!ctx->base_page)
return;
cma_release(ctx->cma, ctx->base_page, ctx->count);
ctx->base_page = NULL;
ctx->count = 0;
ctx->size = 0;
ctx->phys = 0;
}
static long cma_demo_ioctl(struct file *f, unsigned int cmd, unsigned long arg)
{
if (_IOC_TYPE(cmd) != CMA_DEMO_MAGIC)
return -ENOTTY;
switch (cmd) {
case CMA_DEMO_IOCTL_ALLOC: {
struct cma_demo_alloc req;
size_t size;
unsigned long count;
struct page *p;
if (copy_from_user(&req, (void __user *)arg, sizeof(req)))
return -EFAULT;
if (!req.size)
return -EINVAL;
size = PAGE_ALIGN((size_t)req.size);
count = size >> PAGE_SHIFT;
mutex_lock(&g.lock);
if (g.base_page) {
mutex_unlock(&g.lock);
return -EBUSY;
}
if (!g.cma) {
mutex_unlock(&g.lock);
return -ENODEV;
}
/*
* align = 0 => no special alignment beyond page
* gfp = GFP_KERNEL is fine for demo
*/
p = cma_alloc(g.cma, count, 0, GFP_KERNEL);
if (!p) {
mutex_unlock(&g.lock);
return -ENOMEM;
}
g.base_page = p;
g.count = count;
g.size = size;
g.phys = page_to_phys(p);
req.size = size;
req.phys = (u64)g.phys;
mutex_unlock(&g.lock);
if (copy_to_user((void __user *)arg, &req, sizeof(req)))
return -EFAULT;
pr_info(DRV_NAME ": cma_alloc %zu bytes (%lu pages), phys=%pa\n",
size, count, &g.phys);
return 0;
}
case CMA_DEMO_IOCTL_FREE:
mutex_lock(&g.lock);
cma_demo_free_locked(&g);
mutex_unlock(&g.lock);
pr_info(DRV_NAME ": freed\n");
return 0;
case CMA_DEMO_IOCTL_INFO: {
struct cma_demo_info info;
mutex_lock(&g.lock);
info.size = g.size;
info.phys = (u64)g.phys;
mutex_unlock(&g.lock);
if (copy_to_user((void __user *)arg, &info, sizeof(info)))
return -EFAULT;
return 0;
}
default:
return -ENOTTY;
}
}
static int cma_demo_mmap(struct file *f, struct vm_area_struct *vma)
{
size_t vsize = vma->vm_end - vma->vm_start;
unsigned long pfn;
int ret = 0;
mutex_lock(&g.lock);
if (!g.base_page) {
mutex_unlock(&g.lock);
return -ENXIO;
}
if (vsize > g.size) {
mutex_unlock(&g.lock);
return -EINVAL;
}
pfn = page_to_pfn(g.base_page);
/* 映射连续物理页到用户态 */
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
ret = remap_pfn_range(vma, vma->vm_start, pfn, vsize, vma->vm_page_prot);
mutex_unlock(&g.lock);
return ret;
}
static ssize_t cma_demo_read(struct file *f, char __user *buf,
size_t len, loff_t *ppos)
{
size_t done = 0;
mutex_lock(&g.lock);
if (!g.base_page) {
mutex_unlock(&g.lock);
return -ENXIO;
}
if (*ppos >= g.size) {
mutex_unlock(&g.lock);
return 0;
}
if (len > g.size - *ppos)
len = g.size - *ppos;
while (done < len) {
size_t pos = (size_t)(*ppos + done);
size_t page_idx = pos >> PAGE_SHIFT;
size_t in_page = pos & (PAGE_SIZE - 1);
size_t chunk = PAGE_SIZE - in_page;
void *kaddr;
if (chunk > (len - done))
chunk = len - done;
kaddr = kmap_local_page(g.base_page + page_idx);
if (copy_to_user(buf + done, (u8 *)kaddr + in_page, chunk)) {
kunmap_local(kaddr);
mutex_unlock(&g.lock);
return -EFAULT;
}
kunmap_local(kaddr);
done += chunk;
}
*ppos += done;
mutex_unlock(&g.lock);
return (ssize_t)done;
}
static ssize_t cma_demo_write(struct file *f, const char __user *buf,
size_t len, loff_t *ppos)
{
size_t done = 0;
mutex_lock(&g.lock);
if (!g.base_page) {
mutex_unlock(&g.lock);
return -ENXIO;
}
if (*ppos >= g.size) {
mutex_unlock(&g.lock);
return -ENOSPC;
}
if (len > g.size - *ppos)
len = g.size - *ppos;
while (done < len) {
size_t pos = (size_t)(*ppos + done);
size_t page_idx = pos >> PAGE_SHIFT;
size_t in_page = pos & (PAGE_SIZE - 1);
size_t chunk = PAGE_SIZE - in_page;
void *kaddr;
if (chunk > (len - done))
chunk = len - done;
kaddr = kmap_local_page(g.base_page + page_idx);
if (copy_from_user((u8 *)kaddr + in_page, buf + done, chunk)) {
kunmap_local(kaddr);
mutex_unlock(&g.lock);
return -EFAULT;
}
kunmap_local(kaddr);
done += chunk;
}
*ppos += done;
mutex_unlock(&g.lock);
return (ssize_t)done;
}
static const struct file_operations cma_demo_fops = {
.owner = THIS_MODULE,
.unlocked_ioctl = cma_demo_ioctl,
.read = cma_demo_read,
.write = cma_demo_write,
.mmap = cma_demo_mmap,
.llseek = default_llseek,
};
static struct miscdevice cma_demo_misc = {
.minor = MISC_DYNAMIC_MINOR,
.name = "cma_demo",
.fops = &cma_demo_fops,
.mode = 0666,
};
static int __init cma_demo_init(void)
{
int ret;
mutex_init(&g.lock);
/* miscdevice 自带的 this_device 可用来找默认 CMA area */
ret = misc_register(&cma_demo_misc);
if (ret)
return ret;
g.dev = cma_demo_misc.this_device;
/*
* 取 CMA area:如果你的内核启用了默认 CMA,这里通常能拿到默认区域
* 若返回 NULL,说明没有可用 CMA area(例如没开 CMA 或没预留)
*/
g.cma = dev_get_cma_area(g.dev);
pr_info(DRV_NAME ": loaded. /dev/%s cma=0x%x\n", cma_demo_misc.name, g.cma);
return 0;
}
static void __exit cma_demo_exit(void)
{
mutex_lock(&g.lock);
cma_demo_free_locked(&g);
mutex_unlock(&g.lock);
misc_deregister(&cma_demo_misc);
pr_info(DRV_NAME ": unloaded\n");
}
module_init(cma_demo_init);
module_exit(cma_demo_exit);
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("Pure CMA alloc/free + mmap demo");
demo应用层代码
#define _GNU_SOURCE
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include "cma_uapi.h"
static void die(const char *msg)
{
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
exit(1);
}
static int open_dev(const char *path)
{
int fd = open(path, O_RDWR);
if (fd < 0) die("open");
return fd;
}
static void cmd_info(const char *dev)
{
int fd = open_dev(dev);
struct cma_demo_info info;
if (ioctl(fd, CMA_DEMO_IOCTL_INFO, &info) != 0) die("ioctl INFO");
printf("INFO size=%llu phys=0x%llx\n",
(unsigned long long)info.size,
(unsigned long long)info.phys);
close(fd);
}
static void cmd_alloc(const char *dev, size_t bytes)
{
int fd = open_dev(dev);
struct cma_demo_alloc a = {0};
a.size = bytes;
if (ioctl(fd, CMA_DEMO_IOCTL_ALLOC, &a) != 0) die("ioctl ALLOC");
printf("ALLOC ok size=%llu phys=0x%llx\n",
(unsigned long long)a.size,
(unsigned long long)a.phys);
close(fd);
}
static void cmd_free(const char *dev)
{
int fd = open_dev(dev);
if (ioctl(fd, CMA_DEMO_IOCTL_FREE) != 0) die("ioctl FREE");
printf("FREE ok\n");
close(fd);
}
static void cmd_write_pattern(const char *dev, size_t offset, size_t len, unsigned pat)
{
int fd = open_dev(dev);
if (lseek(fd, (off_t)offset, SEEK_SET) < 0) die("lseek");
uint8_t *buf = malloc(len);
if (!buf) { errno = ENOMEM; die("malloc"); }
for (size_t i = 0; i < len; i++)
buf[i] = (uint8_t)((pat + i) & 0xff);
ssize_t w = write(fd, buf, len);
if (w < 0) die("write");
if ((size_t)w != len) {
fprintf(stderr, "write short: %zd/%zu\n", w, len);
exit(2);
}
printf("WRITE ok offset=%zu len=%zu pattern_start=0x%02x\n", offset, len, pat & 0xff);
free(buf);
close(fd);
}
#if 1
static void cmd_write_string(const char *dev, size_t offset, int add_null, int argc, char **argv, int start_i)
{
int fd = open_dev(dev);
if (lseek(fd, (off_t)offset, SEEK_SET) < 0) die("lseek");
/* 把 argv[start_i..] 用空格拼接成一个字符串 */
size_t total = 0;
for (int i = start_i; i < argc; i++) {
total += strlen(argv[i]);
if (i != argc - 1) total += 1; /* space */
}
if (add_null) total += 1; /* '\0' */
uint8_t *buf = malloc(total);
if (!buf) { errno = ENOMEM; die("malloc"); }
size_t pos = 0;
for (int i = start_i; i < argc; i++) {
size_t n = strlen(argv[i]);
memcpy(buf + pos, argv[i], n);
pos += n;
if (i != argc - 1) buf[pos++] = ' ';
}
if (add_null) buf[pos++] = '\0';
ssize_t w = write(fd, buf, total);
if (w < 0) die("write");
if ((size_t)w != total) {
fprintf(stderr, "write short: %zd/%zu\n", w, total);
exit(2);
}
printf("WSTR ok offset=%zu len=%zu%s\n", offset, total, add_null ? " (with \\0)" : "");
free(buf);
close(fd);
}
static void cmd_read_string(const char *dev, size_t offset, size_t len)
{
int fd = open_dev(dev);
if (lseek(fd, (off_t)offset, SEEK_SET) < 0) die("lseek");
uint8_t *buf = malloc(len + 1);
if (!buf) { errno = ENOMEM; die("malloc"); }
ssize_t r = read(fd, buf, len);
if (r < 0) die("read");
buf[r] = '\0';
printf("RSTR ok offset=%zu got=%zd\n", offset, r);
printf("STRING: \"");
for (ssize_t i = 0; i < r; i++) {
unsigned char c = buf[i];
if (c >= 32 && c <= 126) putchar(c);
else putchar('.');
}
printf("\"\n");
free(buf);
close(fd);
}
#endif
static void cmd_read_dump(const char *dev, size_t offset, size_t len, int hex)
{
int fd = open_dev(dev);
if (lseek(fd, (off_t)offset, SEEK_SET) < 0) die("lseek");
uint8_t *buf = malloc(len);
if (!buf) { errno = ENOMEM; die("malloc"); }
ssize_t r = read(fd, buf, len);
if (r < 0) die("read");
printf("READ ok offset=%zu got=%zd\n", offset, r);
if (hex) {
size_t n = (size_t)r;
for (size_t i = 0; i < n; i++) {
if (i % 16 == 0) printf("%08zx: ", offset + i);
printf("%02x ", buf[i]);
if (i % 16 == 15 || i == n - 1) printf("\n");
}
}
free(buf);
close(fd);
}
static void cmd_mmaprw_verify(const char *dev, size_t len, unsigned pat)
{
int fd = open_dev(dev);
struct cma_demo_info info;
if (ioctl(fd, CMA_DEMO_IOCTL_INFO, &info) != 0) die("ioctl INFO");
if (!info.size) {
fprintf(stderr, "No buffer allocated (INFO size=0)\n");
exit(2);
}
size_t map_len = len ? len : (size_t)info.size;
if (map_len > (size_t)info.size) {
fprintf(stderr, "mmap len too big: %zu > %llu\n", map_len, (unsigned long long)info.size);
exit(2);
}
uint8_t *p = mmap(NULL, map_len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (p == MAP_FAILED) die("mmap");
for (size_t i = 0; i < map_len; i++)
p[i] = (uint8_t)((pat + i) & 0xff);
for (size_t i = 0; i < map_len; i++) {
uint8_t exp = (uint8_t)((pat + i) & 0xff);
if (p[i] != exp) {
fprintf(stderr, "MMAP verify fail at %zu got=0x%02x expect=0x%02x\n",
i, p[i], exp);
munmap(p, map_len);
close(fd);
exit(3);
}
}
printf("MMAPRW verify OK len=%zu pattern_start=0x%02x\n", map_len, pat & 0xff);
munmap(p, map_len);
close(fd);
}
static void usage(const char *prog)
{
fprintf(stderr,
"Usage:\n"
" %s [-d /dev/cma_demo] info\n"
" %s [-d /dev/cma_demo] alloc <bytes>\n"
" %s [-d /dev/cma_demo] free\n"
" %s [-d /dev/cma_demo] write <offset> <len> [pattern_start]\n"
" %s [-d /dev/cma_demo] read <offset> <len> [--hex]\n"
" %s [-d /dev/cma_demo] mmaprw [len] [pattern_start]\n"
" %s [-d /dev/cma_demo] wstr <offset> [--null] <string...>\n"
" %s [-d /dev/cma_demo] rstr <offset> <len>\n"
"\n"
"Examples:\n"
" %s alloc 4194304\n"
" %s info\n"
" %s write 0 256 0x11\n"
" %s read 0 64 --hex\n"
" %s wstr 0 --null hello world\n"
" %s rstr 0 64\n"
" %s mmaprw 1048576 0x22\n"
" %s free\n",
prog, prog, prog, prog, prog, prog, prog, prog,
prog, prog, prog, prog, prog, prog, prog, prog
);
exit(1);
}
int main(int argc, char **argv)
{
const char *dev = "/dev/cma_demo";
int argi = 1;
if (argc < 2) usage(argv[0]);
if (!strcmp(argv[argi], "-d")) {
if (argc < 4) usage(argv[0]);
dev = argv[argi + 1];
argi += 2;
}
if (argi >= argc) usage(argv[0]);
const char *cmd = argv[argi++];
if (!strcmp(cmd, "info")) {
cmd_info(dev);
} else if (!strcmp(cmd, "alloc")) {
if (argi >= argc) usage(argv[0]);
size_t bytes = (size_t)strtoull(argv[argi], NULL, 0);
cmd_alloc(dev, bytes);
} else if (!strcmp(cmd, "free")) {
cmd_free(dev);
} else if (!strcmp(cmd, "write")) {
if (argi + 1 >= argc) usage(argv[0]);
size_t off = (size_t)strtoull(argv[argi++], NULL, 0);
size_t len = (size_t)strtoull(argv[argi++], NULL, 0);
unsigned pat = 0;
if (argi < argc) pat = (unsigned)strtoul(argv[argi++], NULL, 0);
cmd_write_pattern(dev, off, len, pat);
#if 1
} else if (!strcmp(cmd, "wstr")) {
if (argi >= argc) usage(argv[0]);
size_t off = (size_t)strtoull(argv[argi++], NULL, 0);
int add_null = 0;
if (argi < argc && !strcmp(argv[argi], "--null")) {
add_null = 1;
argi++;
}
if (argi >= argc) usage(argv[0]); /* need string parts */
cmd_write_string(dev, off, add_null, argc, argv, argi);
} else if (!strcmp(cmd, "rstr")) {
if (argi + 1 >= argc) usage(argv[0]);
size_t off = (size_t)strtoull(argv[argi++], NULL, 0);
size_t len = (size_t)strtoull(argv[argi++], NULL, 0);
cmd_read_string(dev, off, len);
#endif
} else if (!strcmp(cmd, "read")) {
if (argi + 1 >= argc) usage(argv[0]);
size_t off = (size_t)strtoull(argv[argi++], NULL, 0);
size_t len = (size_t)strtoull(argv[argi++], NULL, 0);
int hex = 0;
if (argi < argc && !strcmp(argv[argi], "--hex")) hex = 1;
cmd_read_dump(dev, off, len, hex);
} else if (!strcmp(cmd, "mmaprw")) {
size_t len = 0;
unsigned pat = 0;
if (argi < argc) len = (size_t)strtoull(argv[argi++], NULL, 0);
if (argi < argc) pat = (unsigned)strtoul(argv[argi++], NULL, 0);
cmd_mmaprw_verify(dev, len, pat);
} else {
usage(argv[0]);
}
return 0;
}申请cma内存过程
DEMO应用层程序申请cma内存16M
[root@virt-machine ~]#./cma_cli alloc 16777216我在cma_alloc处加了断点,可以看到此时的cma_area的内存区域是这样的
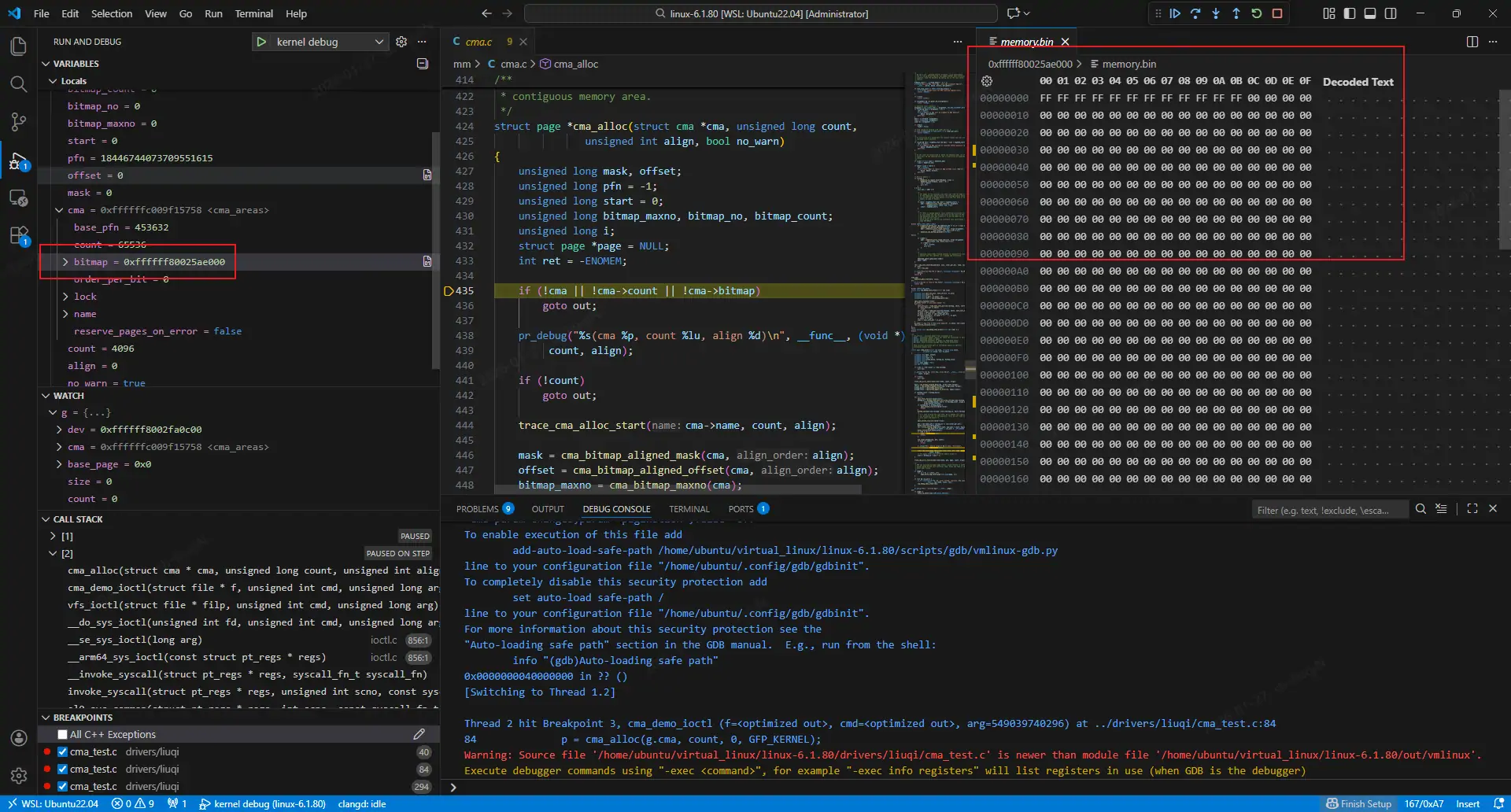
cma_alloc 走到bitmap_set
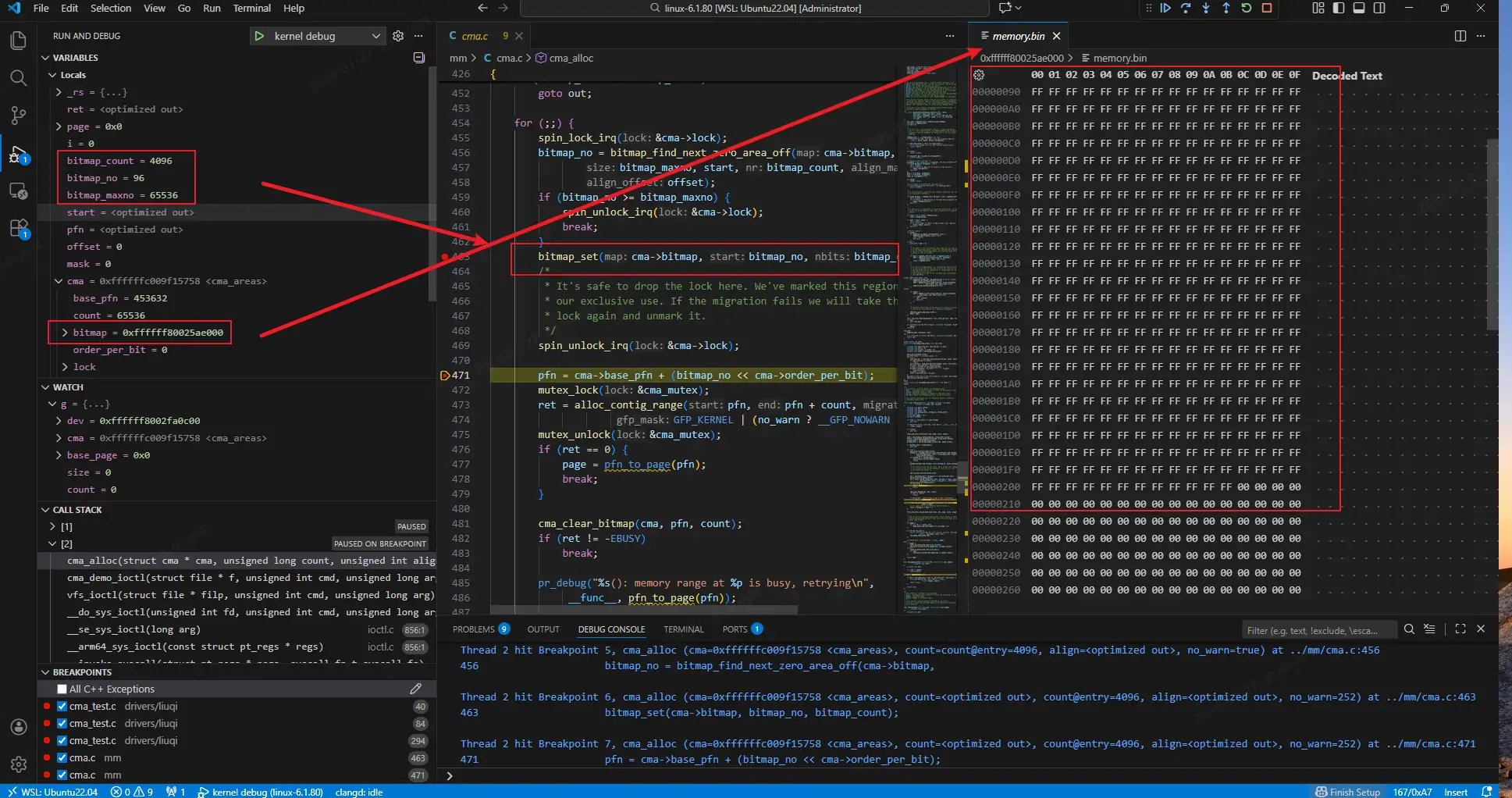
申请内存成功
[root@virt-machine ~]#./cma_cli alloc 16777216
[ 479.264083] cma_demo: cma_alloc 16777216 bytes (4096 pages), phys=0x000000006ec60000
ALLOC ok size=16777216 phys=0x6ec60000
写数据到CMA内存中
[root@virt-machine ~]#./cma_cli wstr 0 hello world
WSTR ok offset=0 len=11
从CMA内存中读取数据
[root@virt-machine ~]#./cma_cli rstr 0 32
RSTR ok offset=0 got=32
STRING: "hello world....................."
[root@virt-machine ~]#./cma_cli read 0 32 --hex
READ ok offset=0 got=32
00000000: 68 65 6c 6c 6f 20 77 6f 72 6c 64 00 00 00 00 00
00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00