
从之前系列的文章中,我们已经初步完成了对Linux内存管理中的各种基础知识,包含各种内存分配器的初始化逻辑以及调用原理的分析。从本章开始,我们将剖析内存管理的核心动态机制——内存回收。在现代操作系统中,内存作为稀缺资源需要高效管理,而内存回收机制正是确保系统在有限物理内存下能够持续运行的关键。
当系统内存不足时,内核必须决定哪些页面可以释放以供新分配使用。这就引出了两个核心问题:如何识别"冷"页面(较少使用的页面)?如何高效地回收这些页面而不影响系统性能? Linux内核通过LRU(Least Recently Used,最近最少使用)链表与页面老化机制提供了一个精妙的解决方案。
本章将深入解析传统LRU链表的设计实现,包括:
LRU链表的多层架构(active/inactive链表)
页面如何在LRU链表间移动的算法逻辑
页面引用位的检测与老化处理
与kswapd回收守护进程的协同工作机制
理解传统LRU机制不仅有助于我们掌握Linux内存回收的基本原理,更为后续分析其演进版本——MGLRU机制奠定了坚实的基础。让我们从LRU链表的基础数据结构开始,逐步揭开内存回收的神秘面纱。
备注:本文基于linux-5.15的内核
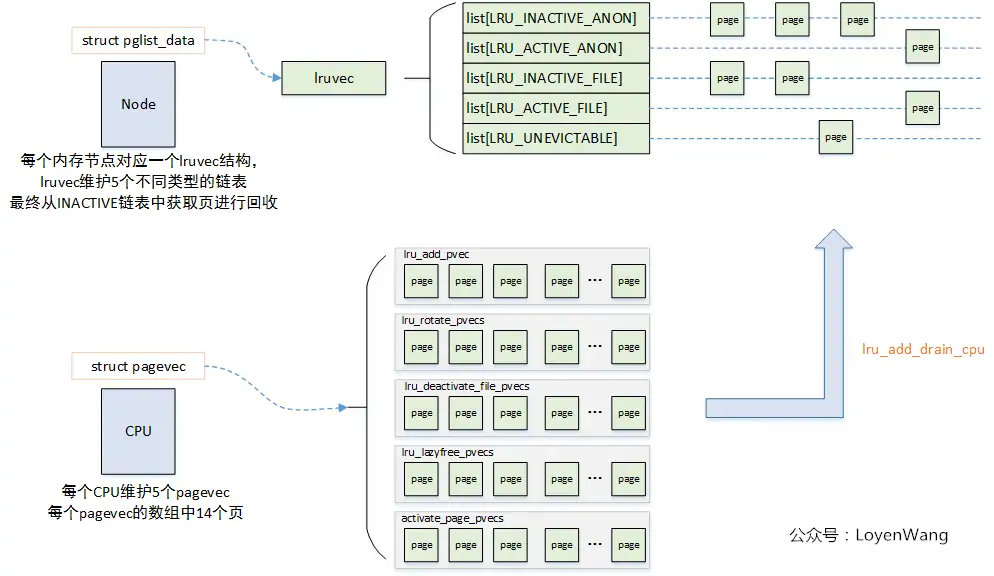
LRU数据结构
在Linux内核中,LRU机制的核心数据结构体现在内存区域(zone)的struct lruvec中。每个内存节点(node)都维护着多个LRU链表,这些链表按照页面类型和活跃程度进行分类管理。让我们先来看看这些关键的数据结构:
struct lruvec {
///LRU链表数组,每个内存节点都有5种类型LRU链表
struct list_head lists[NR_LRU_LISTS];
/* per lruvec lru_lock for memcg */
spinlock_t lru_lock;
/*
* These track the cost of reclaiming one LRU - file or anon -
* over the other. As the observed cost of reclaiming one LRU
* increases, the reclaim scan balance tips toward the other.
*/
unsigned long anon_cost;
unsigned long file_cost;
/* Non-resident age, driven by LRU movement */
atomic_long_t nonresident_age;
/* Refaults at the time of last reclaim cycle */
unsigned long refaults[ANON_AND_FILE];
/* Various lruvec state flags (enum lruvec_flags) */
unsigned long flags;
#ifdef CONFIG_MEMCG
struct pglist_data *pgdat;
#endif
};
核心成员解析:
lists[NR_LRU_LISTS]
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
LRU链表系统由五条核心链表组成,它们分别管理不同类型的页面:
匿名页链表(处理进程堆栈、堆等无文件背景的页面)
LRU_INACTIVE_ANON:非活跃匿名页链表LRU_ACTIVE_ANON:活跃匿名页链表
文件页链表(处理有文件背景的页面,如代码段、映射文件等)
LRU_INACTIVE_FILE:非活跃文件页链表LRU_ACTIVE_FILE:活跃文件页链表
特殊链表
LRU_UNEVICTABLE:不可回收页面链表(如mlock锁定的页面)
这种分类设计体现了内核的内存回收策略:优先回收文件页,尽量避免回收匿名页。因为文件页有磁盘上的后备存储,回收时只需丢弃(若未修改)或写回磁盘(页面内容修改了(变为 脏页 ));而匿名页没有后备存储,回收时需要交换到swap分区,代价更高。
每个页面通过struct page中的标志位和LRU链表节点来参与LRU管理:
struct page {
/* ... */
struct { /* 使用联合体节省空间 */
struct list_head lru;
/* 或用于slab等其他用途 */
};
unsigned long flags; /* 包含PG_active, PG_referenced等标志 */
/* ... */
};
关键标志位说明:
PG_active:页面是否在活跃链表上PG_referenced:页面最近是否被访问过PG_lru:页面是否在某个LRU链表上PG_mlocked:页面是否被mlock锁定
当页面被加入LRU系统时,内核会根据其初始状态将其放入相应的链表。例如,新分配的匿名页通常会被放入LRU_INACTIVE_ANON链表,等待后续的访问行为来决定其命运。
在下一节中,我们将详细分析页面如何在active和inactive链表之间移动,以及页面老化算法的具体实现逻辑。
页面如何加入到LRU链表?
在Linux内核中,页面并不是在分配时就自动加入LRU链表的。相反,在 Linux 内核中,页 page 并不会在 alloc_pages() 时自动加入 LRU。只有当它成为回收系统需要跟踪的可回收页(如进入 page cache 的文件页、或建立了匿名映射的匿名页)时,才会被加入 LRU/unevictable 列表,从而参与页面回收决策。这个设计哲学体现了"按需管理"的思想:只有可能被回收的页面才需要被LRU管理。
页面主要通过lru_cache_add()函数加入到LRU链表:
void lru_cache_add(struct page *page)
{
struct pagevec *pvec;
VM_BUG_ON_PAGE(PageActive(page) && PageUnevictable(page), page);
VM_BUG_ON_PAGE(PageLRU(page), page);
get_page(page);
local_lock(&lru_pvecs.lock);
///获取页向量组
pvec = this_cpu_ptr(&lru_pvecs.lru_add);
///将page加入页向量组,并判断是否需要刷新
///这里为提高性能,对page加入lru做了个批处理,一次性加入15个page
if (pagevec_add_and_need_flush(pvec, page))
///将pvec一次性加入lru链表
__pagevec_lru_add(pvec);
local_unlock(&lru_pvecs.lock);
}
pagevec
这里使用页向量 pagevec 数据结构,借助一个数组来保存特定数量的页
///页向量组,批量处理,对一对页面执行同样操作
struct pagevec {
unsigned char nr;
bool percpu_pvec_drained;
struct page *pages[PAGEVEC_SIZE];
};
nr:记录当前 pagevec 中存放的page 数;
percpu_pvec_drained:用以pagevec_release()时进行标记保护;
pages:page 指针数组,最多存放15个,当达到15时,就会统一存到 LRU 中;
struct page 是描述物理页面的核心结构,每个物理页面通过 lru 字段(struct list_head)挂载到 LRU 链表,而 pagevec 中的 pages 数组存储指向 struct page 的指针,形成 “临时批量管理” 与 “长期链表管理” 的衔接:
短期存储:pagevec 作为临时缓冲区,在操作期间持有页面指针。
长期管理:操作完成后,页面被挂载到 LRU 链表(通过 lru 字段),进入内核的页面生命周期管理。
lru_pvecs
/*
* The following struct pagevec are grouped together because they are protected
* by disabling preemption (and interrupts remain enabled).
*/
struct lru_pvecs {
local_lock_t lock;
struct pagevec lru_add; //待加入 LRU 的页面
struct pagevec lru_deactivate_file; //待去激活的file页面 activate->inactivate
struct pagevec lru_deactivate; //待去激活的file/匿名页面 activate->inactivate
struct pagevec lru_lazyfree; //用于延迟释放匿名交换页 activate->inactivate
#ifdef CONFIG_SMP
struct pagevec activate_page; //待激活的页面 inactivate->activate
#endif
};
///定义per cpu变量的缓存页向量组
static DEFINE_PER_CPU(struct lru_pvecs, lru_pvecs) = {
.lock = INIT_LOCAL_LOCK(lock),
};
page 可以加入到 lru 链表,并且根据条件在 active/inactive 链表间移动。
struct lru_pvecs 是 Linux 内核中用于管理 per-CPU 批量页面操作 的核心数据结构,其设计目的是通过将高频页面操作(如添加到 LRU、激活、去激活)批量暂存到 pagevec 中,减少锁竞争和链表操作开销,提升内存管理效率。
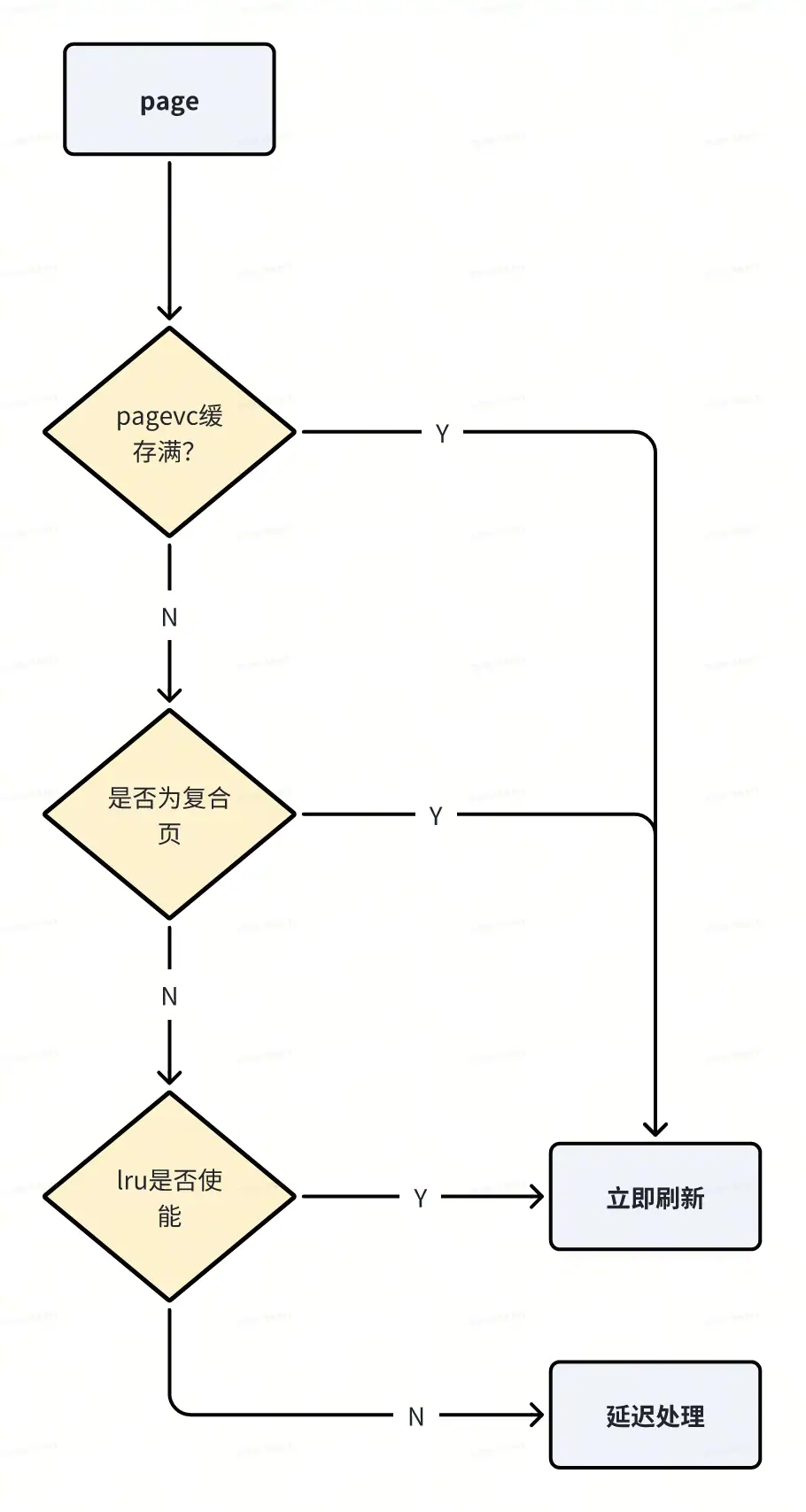
pagevec_add_and_need_flush
/* return true if pagevec needs to drain */
static bool pagevec_add_and_need_flush(struct pagevec *pvec, struct page *page)
{
bool ret = false;
if (!pagevec_add(pvec, page) || PageCompound(page) ||
lru_cache_disabled())
ret = true;
return ret;
}
在内核中,频繁操作单个页面(如添加到 LRU 链表)会导致大量锁竞争和链表操作开销。pagevec 作为批量容器,通过累积多个页面后一次性处理,可显著提升性能。pagevec_add_and_need_flush 的设计目标是:
添加页面到 pagevec:将新页面加入 pagevec 的页面数组。
触发批量处理条件:当满足特定条件时(如 pagevec 已满、页面特殊类型),返回 true 触发批量处理,减少后续操作延迟。
pagevec_add
static inline unsigned pagevec_space(struct pagevec *pvec)
{
return PAGEVEC_SIZE - pvec->nr;
}
/*
* Add a page to a pagevec. Returns the number of slots still available.
*/
static inline unsigned pagevec_add(struct pagevec *pvec, struct page *page)
{
pvec->pages[pvec->nr++] = page;
return pagevec_space(pvec);
}
将 page 加入 pvec->pages 数组,并递增 pvec->nr(当前页面计数)。 若 pvec->nr 已达到 PAGEVEC_SIZE(通常为 15),则无法添加,返回 false。若成功添加,返回 true。
2. PageCompound
static __always_inline int PageCompound(struct page *page)
{
return test_bit(PG_head, &page->flags) || PageTail(page);
}
复合页(Compound Page):由多个连续物理页组成的大页(如透明大页 THP),通常用于高性能场景。
触发逻辑:
复合页的管理与普通页不同(如迁移、回收需特殊处理),因此不适合批量操作,需立即处理。
3. lru_cache_disabled
LRU 缓存禁用:当系统内存压力极大或处于特殊模式(如紧急回收)时,内核可能临时禁用 LRU 链表的正常管理。
__pagevec_lru_add
void __pagevec_lru_add(struct pagevec *pvec)
{
int i;
struct lruvec *lruvec = NULL;
unsigned long flags = 0;
///遍历pvec所有页面
for (i = 0; i < pagevec_count(pvec); i++) {
struct page *page = pvec->pages[i];
lruvec = relock_page_lruvec_irqsave(page, lruvec, &flags);
///page加入lru
__pagevec_lru_add_fn(page, lruvec);
}
if (lruvec)
unlock_page_lruvec_irqrestore(lruvec, flags);
release_pages(pvec->pages, pvec->nr);
pagevec_reinit(pvec);
}
在内核中,频繁操作单个页面(如添加到 LRU 链表)会导致大量锁竞争和链表操作开销。通过 pagevec 批量累积多个页面后,使用 __pagevec_lru_add 一次性处理,可显著提升性能。
__pagevec_lru_add_fn
static void __pagevec_lru_add_fn(struct page *page, struct lruvec *lruvec)
{
//清除 PG_mlocked 标志并获取页面数量
int was_unevictable = TestClearPageUnevictable(page);
int nr_pages = thp_nr_pages(page);
VM_BUG_ON_PAGE(PageLRU(page), page);
//设置 PG_lru 标志并添加内存屏障
SetPageLRU(page);
smp_mb__after_atomic();
if (page_evictable(page)) {
// 如果page是PG_unevictable置位,则获取LRU_UNEVICTABLE链表
// 如果page是匿名页,并且PG_active置位,则获取LRU_ACTIVE_ANON链表,
// 否则是LRU_INACTIVE_ANON链表。
// 如果page是文件页,并且PG_active置位,则获取LRU_ACTIVE_FILE链表,
// 否则是LRU_INACTIVE_FILE链表。
if (was_unevictable)
__count_vm_events(UNEVICTABLE_PGRESCUED, nr_pages);
} else {
//不可回收页面
//清除 PG_active 标志
ClearPageActive(page);
//重新设置 PG_mlocked 标志
SetPageUnevictable(page);
if (!was_unevictable)
__count_vm_events(UNEVICTABLE_PGCULLED, nr_pages);
}
/*
* 将page加入到对应lru链表头部中:
* 1. 获取页的数量,如果支持透明大叶,会是多个页
* 2. 通过mem_cgroup_update_lru_size更新lruvec中lru类型的链表的page num
* 3. 加入对应lru链表头部,更新统计
*/
add_page_to_lru_list(page, lruvec);
// 触发内核跟踪点,记录页面加入 LRU 链表的事件,用于性能分析和调试。
trace_mm_lru_insertion(page);
}
最总会调用list_add添加到表头
add_page_to_lru_list
static __always_inline void add_page_to_lru_list(struct page *page,
struct lruvec *lruvec)
{
///获取page页面类型
enum lru_list lru = page_lru(page);
update_lru_size(lruvec, lru, page_zonenum(page), thp_nr_pages(page));
///将page加入到lru链表
list_add(&page->lru, &lruvec->lists[lru]);
}
在内核的 LRU 页面管理体系中,不同类型和状态的页面需要被分类存储到不同的 LRU 链表中,以便内存回收时能按优先级处理。所以该函数的核心目标是:
判断页面是否不可回收?
若页面被 mlock() 锁定(PG_mlocked 标志置位),则应放入LRU_UNEVICTABLE 链表。区分页面类型
判断页面是匿名页(如堆、栈内存)还是文件映射页(如文件缓存)。判断页面活跃状态
根据 PG_active 标志,确定页面是活跃还是非活跃,从而选择对应的活跃 / 非活跃链表。
static __always_inline enum lru_list page_lru(struct page *page)
{
enum lru_list lru;
// 断言:页面不能同时是活跃且不可回收的
VM_BUG_ON_PAGE(PageActive(page) && PageUnevictable(page), page);
// 判断邪恶面是否不可回收,就是检查页面的 PG_mlocked 标志
if (PageUnevictable(page))
return LRU_UNEVICTABLE;
///判断是否为文件页还是匿名页,根据不同页面类型放在不同的lru链表
lru = page_is_file_lru(page) ? LRU_INACTIVE_FILE : LRU_INACTIVE_ANON;
// 判断页面是否活跃
if (PageActive(page))
lru += LRU_ACTIVE;
return lru;
}
根据不同这三种不同的判断的组合,就可以得到这几种LRU链表:
lru_cache_add 是页面进入 LRU 管理体系的 “入口”,后续页面的生命周期(活跃 / 非活跃转换、回收)均基于 LRU 链表:
初始状态:新页面通过 lru_cache_add 暂存到 pagevec,批量添加时默认进入非活跃 LRU 链表(LRU_INACTIVE_ANON 或 LRU_INACTIVE_FILE)。
活跃升级:若页面被访问(如 mark_page_accessed 调用),会从非活跃链表迁移到活跃 LRU 链表(减少被回收概率)。
回收候选:内存不足时,页面回收算法优先扫描非活跃链表尾部的页面(最近最少使用),通过 lru_cache_add 加入的页面成为回收候选。
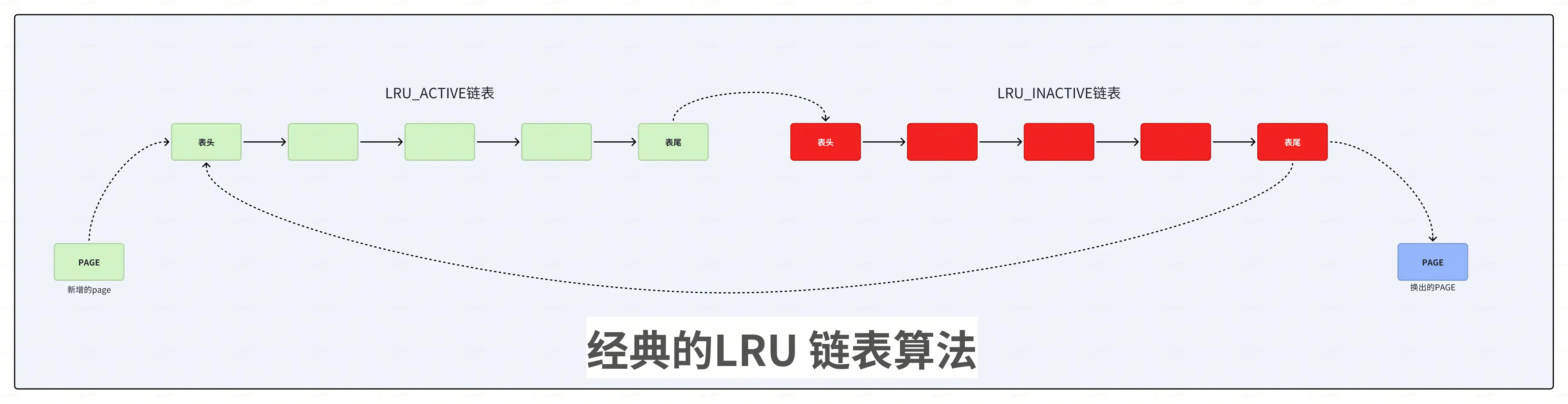
这个就是LRU的经典算法,新产生的页面 被添加到 LRU 链表的开头 ,将 LRU 链表中存在的页面向后移动一个位置。当系统内存短缺时, LRU 链表尾部 的页面将会离开并 被换出 。当系统再需要这些页面时,这些页面会被重新置于 LRU 链表的开头。
页面何时加入到LRU链表?
当内核分配新页面(如文件缓存、匿名内存)或页面状态变化时,需将其加入 LRU 链表以便后续内存回收。
页面缓存处理
当文件数据被读入内存时,新创建的页面会被添加到页面缓存,这些页面通常也会通过 lru_cache_add 被添加到 LRU 链表中匿名页面处理
匿名页面 (anonymous pages) 如进程堆栈、堆分配的内存,这些页面被换出时也会被添加到 LRU 链表页面从 “不可回收” 转为 “可回收”
透明大页(THP)合并
将连续的普通页面合并为透明大页,如果连续的普通页面在LRU链表里面,那么连续的普通页面要从LRU链表摘除,合并的透明大页要加入到LRU链表中。页面状态转换
页面激活/停用
活跃 <-> 非活跃转换:
活跃页面变为非活跃: deactivate_page()
非活跃页面重新激活: mark_page_accessed()页面回收时
活跃 LRU → 非活跃 LRU → 被回收
将活跃页移到非活跃列表: shrink_active_list()
回收非活跃页: shrink_inactive_list()
下面列了四种场景的案例
PS:以下代码均做简化处理
场景一:页缓存(Page Cache)读取路径
mm/filemap.c
// mm/filemap.c
struct page *pagecache_get_page(...)
{
//...
page = __page_cache_alloc(gfp_mask);
if (page) {
// 分配成功后初始化页面
err = add_to_page_cache_lru(page, mapping, index, gfp_mask);
if (unlikely(err)) {
put_page(page);
page = NULL;
}
}
return page;
}
int add_to_page_cache_lru(struct page *page, struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask)
{
//...
// 将页面添加到页缓存树中
int ret = add_to_page_cache(page, mapping, offset, gfp_mask);
if (ret == 0)
lru_cache_add(page); // 关键:加入LRU系统
return ret;
}
场景二:匿名页缺页处理(do_anonymous_page)
// mm/memory.c
static vm_fault_t do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page;
// 分配零初始化的匿名页
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
if (!page)
goto oom;
// 初始化页面
__SetPageUptodate(page);
// 建立页表映射
entry = mk_pte(page, vma->vm_page_prot);
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
// 更新反向映射
page_add_new_anon_rmap(page, vma, vmf->address, false);
// 关键:匿名页加入LRU系统
lru_cache_add_inactive_or_unevictable(page, vma);
return VM_FAULT_NOPAGE;
}
// mm/swap.c
void lru_cache_add_inactive_or_unevictable(struct page *page,
struct vm_area_struct *vma)
{
bool unevictable;
VM_BUG_ON_PAGE(PageLRU(page), page);
unevictable = (vma->vm_flags & (VM_LOCKED | VM_SPECIAL)) == VM_LOCKED;
if (unlikely(unevictable) && !TestSetPageMlocked(page)) {
int nr_pages = thp_nr_pages(page);
/*
* We use the irq-unsafe __mod_zone_page_state because this
* counter is not modified from interrupt context, and the pte
* lock is held(spinlock), which implies preemption disabled.
*/
__mod_zone_page_state(page_zone(page), NR_MLOCK, nr_pages);
count_vm_events(UNEVICTABLE_PGMLOCKED, nr_pages);
}
lru_cache_add(page);
}
场景三:文件映射缺页处理(filemap_fault)
vm_fault_t filemap_fault(struct vm_fault *vmf)
{
///如果pagecache已经存在,直接获取
page = find_get_page(mapping, offset);
if (likely(page)) {
/*
* We found the page, so try async readahead before waiting for
* the lock.
*/
if (!(vmf->flags & FAULT_FLAG_TRIED))
///直接读到pagecache
fpin = do_async_mmap_readahead(vmf, page);
if (unlikely(!PageUptodate(page))) {
filemap_invalidate_lock_shared(mapping);
mapping_locked = true;
}
} else {
/* No page in the page cache at all */
count_vm_event(PGMAJFAULT);
count_memcg_event_mm(vmf->vma->vm_mm, PGMAJFAULT);
ret = VM_FAULT_MAJOR;
fpin = do_sync_mmap_readahead(vmf);
retry_find:
/*
* See comment in filemap_create_page() why we need
* invalidate_lock
*/
if (!mapping_locked) {
filemap_invalidate_lock_shared(mapping);
mapping_locked = true;
}
///pagecache不存在,分配一个
page = pagecache_get_page(mapping, offset,
FGP_CREAT|FGP_FOR_MMAP,
vmf->gfp_mask);
if (!page) {
if (fpin)
goto out_retry;
filemap_invalidate_unlock_shared(mapping);
return VM_FAULT_OOM;
}
}
}
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t index,
int fgp_flags, gfp_t gfp_mask)
{
///分配一个page,并读入文件内容, 用于pagecache
page = __page_cache_alloc(gfp_mask);
///page加入lru链表
err = add_to_page_cache_lru(page, mapping, index, gfp_mask);
}
场景四:swap缓存页面
// mm/swap_state.c
struct page *__read_swap_cache_async(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma,
unsigned long addr)
{
struct page *page;
// 分配页面
page = alloc_page_vma(gfp_mask, vma, addr);
if (!page)
return NULL;
/* May fail (-ENOMEM) if XArray node allocation failed. */
if (add_to_swap_cache(page, entry, gfp_mask & GFP_RECLAIM_MASK, &shadow))
goto fail_unlock;
mem_cgroup_swapin_uncharge_swap(entry);
if (shadow)
workingset_refault(page, shadow);
/* Caller will initiate read into locked page */
lru_cache_add(page);
*new_page_allocated = true;
return page;
}
LRU的其他操作函数
我们在上一节,花了很多的篇幅介绍了LRU add的操作,其实我们也了解LRU涉及了多种状态,这其中必然存在状态间的切换!也就是一个page在不同链表之间的切换!所以这章主要介绍这部分的操作函数
下面介绍三个接口
activate_page
static void activate_page(struct page *page)
{
page = compound_head(page);
if (PageLRU(page) && !PageActive(page) && !PageUnevictable(page)) {
struct pagevec *pvec;
local_lock(&lru_pvecs.lock);
// 获取本cpu的active_page链表
pvec = this_cpu_ptr(&lru_pvecs.activate_page);
get_page(page);
if (pagevec_add_and_need_flush(pvec, page)) ///加入页向量组
pagevec_lru_move_fn(pvec, __activate_page); ///从不活跃链表移除
local_unlock(&lru_pvecs.lock);
}
}
static void __activate_page(struct page *page, struct lruvec *lruvec)
{
if (!PageActive(page) && !PageUnevictable(page)) {
int nr_pages = thp_nr_pages(page);
del_page_from_lru_list(page, lruvec); ///从不活跃链表删除掉
SetPageActive(page);
add_page_to_lru_list(page, lruvec); ///添加到活跃链表
trace_mm_lru_activate(page);
__count_vm_events(PGACTIVATE, nr_pages);
__count_memcg_events(lruvec_memcg(lruvec), PGACTIVATE,
nr_pages);
}
}
非活动页被标记为活动页后,要加入到活动lru链表中
deactivate_page
void deactivate_page(struct page *page)
{
//确保页面当前在活跃链表。
//排除不可回收的页面(如 mlock 锁定的页面)。
if (PageLRU(page) && PageActive(page) && !PageUnevictable(page)) {
struct pagevec *pvec;
local_lock(&lru_pvecs.lock);
// 获取本cpu的deactivate缓存链表
pvec = this_cpu_ptr(&lru_pvecs.lru_deactivate);
get_page(page);
if (pagevec_add_and_need_flush(pvec, page))
pagevec_lru_move_fn(pvec, lru_deactivate_fn);
local_unlock(&lru_pvecs.lock);
}
}
static void lru_deactivate_fn(struct page *page, struct lruvec *lruvec)
{
if (PageActive(page) && !PageUnevictable(page)) {
//若页面是透明大页,返回其包含的基页数量(如 2MB 大页返回 512);普通页返回 1。
int nr_pages = thp_nr_pages(page);
//将页面从其当前所属的活跃 LRU 链表中删除。
del_page_from_lru_list(page, lruvec);
//移除活跃状态标志。
ClearPageActive(page);
//清除引用标记
ClearPageReferenced(page);
//将页面添加到非活跃 LRU 链表(默认插入头部)。
add_page_to_lru_list(page, lruvec);
__count_vm_events(PGDEACTIVATE, nr_pages);
__count_memcg_events(lruvec_memcg(lruvec), PGDEACTIVATE,
nr_pages);
}
}
deactivate_page() 函数用于将特定页面从活跃 LRU 链表移至非活跃 LRU 链表,加速其回收流程,这个函数是不区分页面类型(匿名页还是文件映射页)
前提需要满足条件:
该 page 是在 LRU中;
该page 是PG_active;
该 page 是可以回收;
deactivate_file_page
///将文件页从LRU_ACTIVE放入LRU_INACTIVE
void deactivate_file_page(struct page *page)
{
/*
* In a workload with many unevictable page such as mprotect,
* unevictable page deactivation for accelerating reclaim is pointless.
*/
if (PageUnevictable(page))
return;
if (likely(get_page_unless_zero(page))) {
struct pagevec *pvec;
local_lock(&lru_pvecs.lock);
pvec = this_cpu_ptr(&lru_pvecs.lru_deactivate_file);
if (pagevec_add_and_need_flush(pvec, page))
pagevec_lru_move_fn(pvec, lru_deactivate_file_fn);
local_unlock(&lru_pvecs.lock);
}
}
static void lru_deactivate_file_fn(struct page *page, struct lruvec *lruvec)
{
bool active = PageActive(page);
int nr_pages = thp_nr_pages(page);
///page不可回收,退出
if (PageUnevictable(page))
return;
/* Some processes are using the page */
///page被映射使用中,退出
if (page_mapped(page))
return;
///从LRU_ACTIVE中删除
del_page_from_lru_list(page, lruvec);
///清除PG_active和PG_referenced标记
ClearPageActive(page);
ClearPageReferenced(page);
//根据页面状态重新加入链表
//脏页/回写页
if (PageWriteback(page) || PageDirty(page)) {
/*
* PG_reclaim could be raced with end_page_writeback
* It can make readahead confusing. But race window
* is _really_ small and it's non-critical problem.
*/
///如果需要回写或脏页,加到LRU链表头
add_page_to_lru_list(page, lruvec);
///设置PG_reclaim标记
SetPageReclaim(page);
} else {
/*
* The page's writeback ends up during pagevec
* We move that page into tail of inactive.
*/
///加到LRU链表尾,尽快回收
add_page_to_lru_list_tail(page, lruvec);
__count_vm_events(PGROTATED, nr_pages);
}
if (active) {
__count_vm_events(PGDEACTIVATE, nr_pages);
__count_memcg_events(lruvec_memcg(lruvec), PGDEACTIVATE,
nr_pages);
}
}
deactivate_file_page() 函数用于强制将文件映射页面标记为非活跃状态,向内存管理系统(VM)提示该页面是潜在的内存回收候选对象。
lru_deactivate_file_fn 是 Linux 内核中用于处理文件映射页面 LRU 状态转换的核心函数,其作用是将符合条件的页面从活跃 LRU 链表移至非活跃 LRU 链表,或调整其在非活跃 LRU 中的位置,以优化内存回收效率。
核心功能:将文件页从活跃 LRU 链表降级到非活跃链表,或调整其在非活跃链表中的位置,以优化内存回收效率。
设计目标:提高脏页/回写页的刷新效率(通过移动到非活跃链表头部,优先被刷盘线程处理)。
状态处理规则总结如下:
dactivate_page和deactivate_file_page的区别:
第二次机会法
单纯基于LRU算法,INACTIVE LIST表头的page页面最容易被回收,这样可能存在频繁使用的page被换出去,为了防止这种情况,内核开发者提交了第二次机会法补丁,也就是标记页面是否频繁被引用/访问,如果频繁被使用,会多一次机会停留在不活跃链表,甚至还有机会迁移到活跃链表。为了实现第二次机会法,
内核定义了2个标志位:
PG_active:表示页面是否活跃
PG_referenced:表示页面是否被引用过
三个函数:
mark_page_accessed
page_referenced
page_check_references
mark_page_accessed
void mark_page_accessed(struct page *page)
{
//处理复合页
page = compound_head(page);
///PG_referenced==0,无论活跃或不活跃链表,都置1
if (!PageReferenced(page)) {
//对应状态转换:inactive,unreferenced → inactive,referenced。
//对应状态转换:active,unreferenced → active,referenced
SetPageReferenced(page);
} else if (PageUnevictable(page)) {
// 处理不可回收页面
/*
* Unevictable pages are on the "LRU_UNEVICTABLE" list. But,
* this list is never rotated or maintained, so marking an
* evictable page accessed has no effect.
*/
} else if (!PageActive(page)) {
// 激活非活跃页面
/*
* If the page is on the LRU, queue it for activation via
* lru_pvecs.activate_page. Otherwise, assume the page is on a
* pagevec, mark it active and it'll be moved to the active
* LRU on the next drain.
*/
///页面被访问,且referenced不为0,但不是活跃,将访问位清零,加入到活跃链表
///加入到活跃链表:
/// 如果page在当前在lru(inactive),先从原来lru删除,再加入也向量组,等待激活;
/// 如果page在页向量组, 激活标志位,将来会加入活跃链表
if (PageLRU(page))
activate_page(page);
else
__lru_cache_activate_page(page); ///设置活跃标记
// 状态转换:inactive,referenced → active,unreferenced
ClearPageReferenced(page); ///清除referenced=0
workingset_activation(page);
}
if (page_is_idle(page))
clear_page_idle(page);
}
mark_page_accessed() 函数的实现,负责管理页面的访问状态和 LRU (Least Recently Used) 链表位置。
该函数用于标记一个页面被访问过,并根据其当前状态调整在 LRU 链表中的位置,影响内核的内存回收策略。
页面状态转换遵循以下规则:
inactive,unreferenced -> inactive,referenced
inactive,referenced -> active,unreferenced
active,unreferenced -> active,referenced
mark_page_accessed() 的主要逻辑:
如果PG_active 0 && PG_referenced 1 时
如果 page 处于 LRU 中,通过activate_page() 将page 置入activate_page_pvecs,或者加入LRU_ACTIVE 链表中(这里会设置 PG_active 为 1);
如果 page 不处于 LRU 中,确认 lru_add_pvec 是否有,如果有则设置PG_active 为 1;
清除 PG_referenced标志位;
如果PG_referenced == 0,则设置PG_referenced 标志位(active 或 inactive);
page_check_references
在扫描不活跃LRU链表时,page_check_referenced()会被调用,返回值是一个page_referenced的枚举类型。
/*******************************************************************************
* func:扫描不活跃链表时,会被调用;返回page_references页面行为类型
* 无页面访问,无映射,回收
* 当页面有访问,引用了PTE时,要放回到活跃LRU链表的情况有:
* (1)页面是匿名页面(PageSwapBacked(page));
* (2)页面位于最近第二次访问的文件缓存,或共享的文件缓存中;
* (3)页面位于可执行文件的缓存中;
*
* 为了解决大量仅使用一次的page cache页面,充斥活跃链表问题,2.6.29开始做了如下优化
* 当第一次读文件时,不调用mark_page_accessed(),
* 即referenced_ptes=1,referenced_page=0
******************************************************************************/
static enum page_references page_check_references(struct page *page,
struct scan_control *sc)
{
int referenced_ptes, referenced_page;
unsigned long vm_flags;
///检查页面,引用了多少个PTE(referenced_ptes),是否有访问
referenced_ptes = page_referenced(page, 1, sc->target_mem_cgroup,
&vm_flags);
///返回PG_referenced的值(只跟是否访问有关,与历史值无关),并清除PG_referenced标记
referenced_page = TestClearPageReferenced(page);
/*
* Mlock lost the isolation race with us. Let try_to_unmap()
* move the page to the unevictable list.
*/
///页面被锁,不支持回收
if (vm_flags & VM_LOCKED)
return PAGEREF_RECLAIM;
///referenced_ptes有映射pte
if (referenced_ptes) {
/*
* All mapped pages start out with page table
* references from the instantiating fault, so we need
* to look twice if a mapped file page is used more
* than once.
*
* Mark it and spare it for another trip around the
* inactive list. Another page table reference will
* lead to its activation.
*
* Note: the mark is set for activated pages as well
* so that recently deactivated but used pages are
* quickly recovered.
*/
SetPageReferenced(page);
///referenced_page > 0, 访问过,放入活跃链表
///referenced_ptes>1, 多个vma映射,放入活跃链表
if (referenced_page || referenced_ptes > 1)
return PAGEREF_ACTIVATE;
/*
* Activate file-backed executable pages after first usage.
*/
///映射可执行文件,或匿名页面,放入活跃链表
if ((vm_flags & VM_EXEC) && !PageSwapBacked(page))
return PAGEREF_ACTIVATE;
///referenced_page==0,referenced_ptes==1,继续放在不活跃链表,优化读文件大量一次性page cache占用活跃链表问题
return PAGEREF_KEEP;
}
/* Reclaim if clean, defer dirty pages to writeback */
///没有被访问,也无映射回收页面
if (referenced_page && !PageSwapBacked(page))
return PAGEREF_RECLAIM_CLEAN;
return PAGEREF_RECLAIM;
}
如果有访问引用PTE
如果页面的引用计数大于0或访问引用PTE的个数大于1,则加入活跃链表
此处referenced_page可以过滤大量只读一次的文件页面迁移到active list? 由于对于page cache页面不会调用mark_page_accessed设置PG_referenced,因此第一次访问referenced_page为0,不会加入活跃链表,第二次访问通过page_check_references->SetPageReferenced会设置PG_referenced标志,referenced_page不为0,因此会将page加入活跃链表可执行文件的page cache 加入活跃链表
最近第二次访问的page cache或shared page cache加入活跃链表
除以上情况继续留在不活跃链表,如第一次访问的page cache
如果没有访问引用PTE
可以尝试回收页面
page_referenced
page_referenced() 函数判断page是否被访问引用过,返回访问引用pte的个数,即访问和引用这个页面的用户进程空间虚拟页面的个数。
核心思想是利用反响映射系统来统计访问引用pte的用户个数。
int page_referenced(struct page *page,
int is_locked,
struct mem_cgroup *memcg,
unsigned long *vm_flags)
{
int we_locked = 0;
struct page_referenced_arg pra = {
.mapcount = total_mapcount(page),
.memcg = memcg,
};
struct rmap_walk_control rwc = {
.rmap_one = page_referenced_one,
.arg = (void *)&pra,
.anon_lock = page_lock_anon_vma_read,
};
*vm_flags = 0;
if (!pra.mapcount) ///判断_mapcount是否大于等于0
return 0;
if (!page_rmapping(page)) ///判断page->mapping是否有地址空间映射
return 0;
if (!is_locked && (!PageAnon(page) || PageKsm(page))) {
we_locked = trylock_page(page);
if (!we_locked)
return 1;
}
/*
* If we are reclaiming on behalf of a cgroup, skip
* counting on behalf of references from different
* cgroups
*/
if (memcg) {
rwc.invalid_vma = invalid_page_referenced_vma;
}
rmap_walk(page, &rwc); ///遍历映射page的所有VMA,调用rmap_one()函数,判断是否有映射的pte,统计映射pte总数
*vm_flags = pra.vm_flags;
if (we_locked)
unlock_page(page);
return pra.referenced;
}
函数主要操作如下:
在 rmap_walk_control 数据结构中定义 rmap_one 函数的指针;
用total_mapcount(),然后调用 page_mapcount() 判断 page->_mapcount 是否大于或等于0;
page_rmapping() 判断page->mapping 是否有地址空间映射;
rmap_walk() 遍历所有映射该页面的PTE,然后调用 rmap_one() 函数。由于 rmap_one 之前指定的是 page_referenced_one(),因此在rmap_walk() 函数中,最终会调用 page_referenced_one() 函数来统计访问、引用的 PTE 个数。page_referenced_one() 函数定义在 mm/rmap.c 中;
带来的严重的性能的问题!!!
每一次page_check_references() 函数调用,都需要确认 referenced_ptes,当一个页面被多个进程共享时,需要经过反向映射技术RMAP 找到每个进程的PTE,最终确定 referenced_ptes。这将带来很大的性能问题!而MGLRU的引入也是为了解决这个问题!
总结
分层管理思想:将页面按类型(匿名/文件)和活跃度分层管理,实现了差异化的回收策略
渐进式状态转移:通过"首次访问标记、二次访问激活"的渐进策略,有效区分了临时使用和真正活跃的页面
批量处理优化:per-CPU pagevec缓存机制显著减少了锁竞争,提升了LRU操作性能