
前言:那些深夜的警报
凌晨三点,手机再次响起。又是一个 Ramdump,又是一个无法复现的系统崩溃。作为内核稳定性工程师,这样的场景已经成为了我职业生涯的一部分。
打开 Ramdump Parser 的输出,映入眼帘的是:
dmesg_TZ.txt- 15MB 的内核日志tasks.txt- 数千个进程的完整状态tasks_sched_stats/- 每个 CPU 的调度统计vmstats.txt,meminfo.txt,workqueue.txt...
这些文件像是一个庞大的犯罪现场,而我需要从中找出导致系统崩溃的"真凶"。传统的分析方式是什么?打开文本编辑器,用 Ctrl+F 搜索 "panic", "oops", "BUG",然后在几万行日志中人工寻找关键信息。这个过程可能需要几个小时,甚至几天。
更糟糕的是,有时候问题的根因隐藏在看似无关的日志片段中:一个异常的中断计数、一个阻塞的任务、一个微妙的内存泄漏。这些线索需要丰富的经验和直觉才能发现。
这就是 Stability AI 诞生的原因。
第一部分:理念的萌芽
传统分析方式的困境
在开发这个工具之前,我的工作流程是这样的:
收到 Ramdump → 解压文件 → 打开 dmesg_TZ.txt → 搜索关键字
→ 复制 calltrace → 手动查符号表 → 推测根因 → 写分析报告这个过程有几个核心痛点:
信息过载:一个 Ramdump 可能包含几十个文件,总大小超过 100MB。我需要知道先看哪个文件,哪些信息是关键的。
符号解析的困难:看到
drm_atomic_helper_commit+0x1a8这样的地址,我需要:找到对应的 vmlinux 文件
运行
nm vmlinux | grep drm_atomic_helper_commit计算偏移量
使用 addr2line 找到源码位置
如果涉及内核模块(.ko),还要重复这个流程
关联分析的复杂性:有时候 panic 只是表象,真正的根因可能是:
中断风暴导致的调度延迟
某个驱动的死锁导致的 watchdog
内存碎片化导致的分配失败
报告编写的低效:分析完成后,还要写一份详细的报告,包括:
问题描述
根因分析
建议措施
严重等级评估
责任团队分配
AI 时代的新机遇
2023 年,当我第一次尝试把一段 panic 日志扔给 GPT-4 时,我被它的分析能力震惊了。它不仅能识别问题类型,还能推断可能的根因,甚至给出调试建议。
但很快我就遇到了新的问题:
Token 限制:一个完整的 dmesg_TZ.txt 有 15MB,远超 GPT-4 的上下文窗口(即使是 128K 的版本)
成本问题:如果能传完整文件,每次分析的成本会很高,完全无法做到可以随意使用的程度
信噪比低:大量的无关信息会干扰 AI 的判断
这让我意识到:AI 不是用来替代人工筛选的,而是用来增强人工分析的。我需要一个工具,它能:
用程序化的方式提取关键信息
用符号解析还原出人类可读的调用栈
把精炼后的信息传给 AI
生成结构化、可操作的分析报告
这就是 Stability AI 的核心理念:人机协作,而非完全自动化。
第二部分:框架的设计哲学
架构总览:管道式处理流
Stability AI 采用经典的管道式架构,类似于 Unix 哲学的 "Do One Thing Well":
原始日志 → Ingest → Normalize → Segment → Detect → Analyze → Enrich → Render每个阶段都有明确的职责:
这种设计有几个好处:
1. 职责清晰:每个模块只做一件事,易于测试和维护
2. 可扩展性:要添加新的问题类型,只需添加新的 Detector 和 Analyzer
3. 灵活组合:可以只运行本地分析,也可以加上符号解析,还可以进一步启用 AI
插件化设计:Registry 模式
Stability AI 的核心是一个插件注册系统:
class Registry:
detectors: List[Detector] # 检测器
analyzers: List[Analyzer] # 分析器
enrichers: List[Enricher] # 增强器所有的扩展都通过 Protocol(结构化类型)定义接口:
class Detector(Protocol):
name: str
def detect(self, ctx: AnalysisContext) -> List[EventCandidate]: ...
class Analyzer(Protocol):
supported_types: List[str]
def analyze(self, cand: EventCandidate, ctx: AnalysisContext) -> IncidentReport: ...这意味着:
要添加新的崩溃类型?实现 Detector 和 Analyzer 接口即可
要添加新的数据源?实现新的 Ingest 逻辑
要添加新的输出格式?实现新的 Renderer
没有硬编码,没有继承地狱,只有接口和组合
数据模型:IncidentReport
整个工具的核心数据结构是 IncidentReport,它是一个结构化的 JSON 对象:
report_version: "2.0"
event:
type: "PANIC"
subtype: "NULL_POINTER"
confidence: 0.95
span: {start_line: 100, end_line: 150}
summary:
title: "Kernel panic in drm_atomic_helper_commit"
severity: "S1" # S0-S3
owner_team: "display"
evidence:
panic_message: "Unable to handle kernel NULL pointer dereference"
faulting_address: "0x0000000000000018"
pc: "drm_atomic_helper_commit+0x1a8"
calltrace: [...]
analysis:
what_happened: "访问了空指针..."
why_probable: "commit 对象为空..."
root_cause_hypothesis: "上游未验证返回值"
actions:
immediate_checks: ["检查调用链", "验证 NULL 检查"]
reproduction_hints: ["特定场景触发", "竞态窗口"]
attachments:
symbolized_calltrace: [
{function: "drm_atomic_helper_commit",
offset: "0x1a8",
source: "drivers/gpu/drm/drm_atomic_helper.c:1423"}
]这个设计的优点:
1. 结构化:可以被程序解析、聚合、可视化
2. 可扩展:可以添加新字段而不破坏旧版本
3. AI 友好:LLM 可以直接生成这个格式,也可以解析它
4. 人类可读:转换成 Markdown 或 HTML 很容易
符号解析:从地址到源码
符号解析是 Stability AI 的关键特性之一。看到这样的 calltrace:
[<ffffff8008123456>] drm_atomic_helper_commit+0x1a8
[<ffffff80081234a0>] drm_atomic_commit+0x50工具会自动:
提取地址和函数名
drm_atomic_helper_commit+0x1a8查找基地址(如果没有完整地址):
nm vmlinux | grep drm_atomic_helper_commit
ffffff80081232ae T drm_atomic_helper_commit计算实际地址
0xffffff80081232ae + 0x1a8 = 0xffffff8008123456解析源码位置:
addr2line -e vmlinux 0xffffff8008123456
drivers/gpu/drm/drm_atomic_helper.c:1423缓存结果:避免重复解析
对于内核模块(.ko 文件),流程类似,但需要处理模块加载地址的问题。
为什么这很重要?
- 开发者不需要手动查符号表
- 可以直接定位到源码行
- 跨团队分享时,即使没有符号表也能看懂分析
智能提取:不是所有数据都需要 AI
对于 Ramdump 的批次分析,工具实现了智能提取策略:
# dmesg_TZ.txt (15MB) → 提取关键部分
- 前 100 行(启动信息)
- panic/oops/BUG 关键区域(±50 行上下文)
- 中断统计("Top irqs", "IrqParse")
- CPU context(PC/LR 寄存器)
# tasks_sched_stats/ → 按 CPU 分离
- 每个 CPU 的调度统计独立分析
- 识别 D 状态任务(IO 阻塞、死锁)
- 检测批量阻塞(资源竞争)
# console_logs.txt → 前 500 行
# tasks.txt → 前 500 行
# meminfo.txt → 完整内容(通常很小)这种策略将原始 100MB+ 的数据精炼到 50-100KB,既保留了关键信息,又控制了成本。
对比数据:
原始 Ramdump:100MB+,无法传给 AI
智能提取后:50KB,GPT-4 tokens < 20K
成本:从不可行 → 每次分析 < ¥0.2
批次分析仪表盘:从单点到全局
当我需要分析一整个Ramdump 时,单个文件的解析报告已经不够用了。我需要:
全局视角:哪些问题是高频的?
趋势分析:问题是在增多还是减少?
优先级排序:哪些问题应该优先解决?
批次分析仪表盘应运而生:
python -m stability_ai.cli \
--batch \
-i ./ramdump_output/ \
--html dashboard.html生成的 HTML 仪表盘包含:
执行摘要:
总分析数:23
严重问题(S0/S1):5
警告(S2):12
常见根因 Top 3
问题分布:
饼图:按类型(Panic, Watchdog, Hung Task)
柱状图:按严重等级
时间线:问题发生时间(如果有)
关键发现表格:
可排序、可过滤
点击展开查看详情
一键跳转到源文件
交互式细节:
点击任一报告展开完整分析
符号解析的 calltrace
AI 的根因推断和建议
技术实现:
纯前端渲染(Chart.js + 原生 JS)
响应式设计(适配手机/平板)
美学优化(毛玻璃效果、渐变、动画)
于是它诞生了



第三部分:实战案例与经验总结
中断风暴引发的 Watchdog
问题现象:
系统运行数小时后突然重启,Ramdump 显示 Watchdog Bite。
传统分析:
查看 dmesg,发现 watchdog: BUG: soft lockup - CPU#2 stuck for 22s
检查该 CPU 的调用栈,发现在 drm 驱动中
怀疑是渲染任务卡死,但无法确认根因
Stability AI 分析:
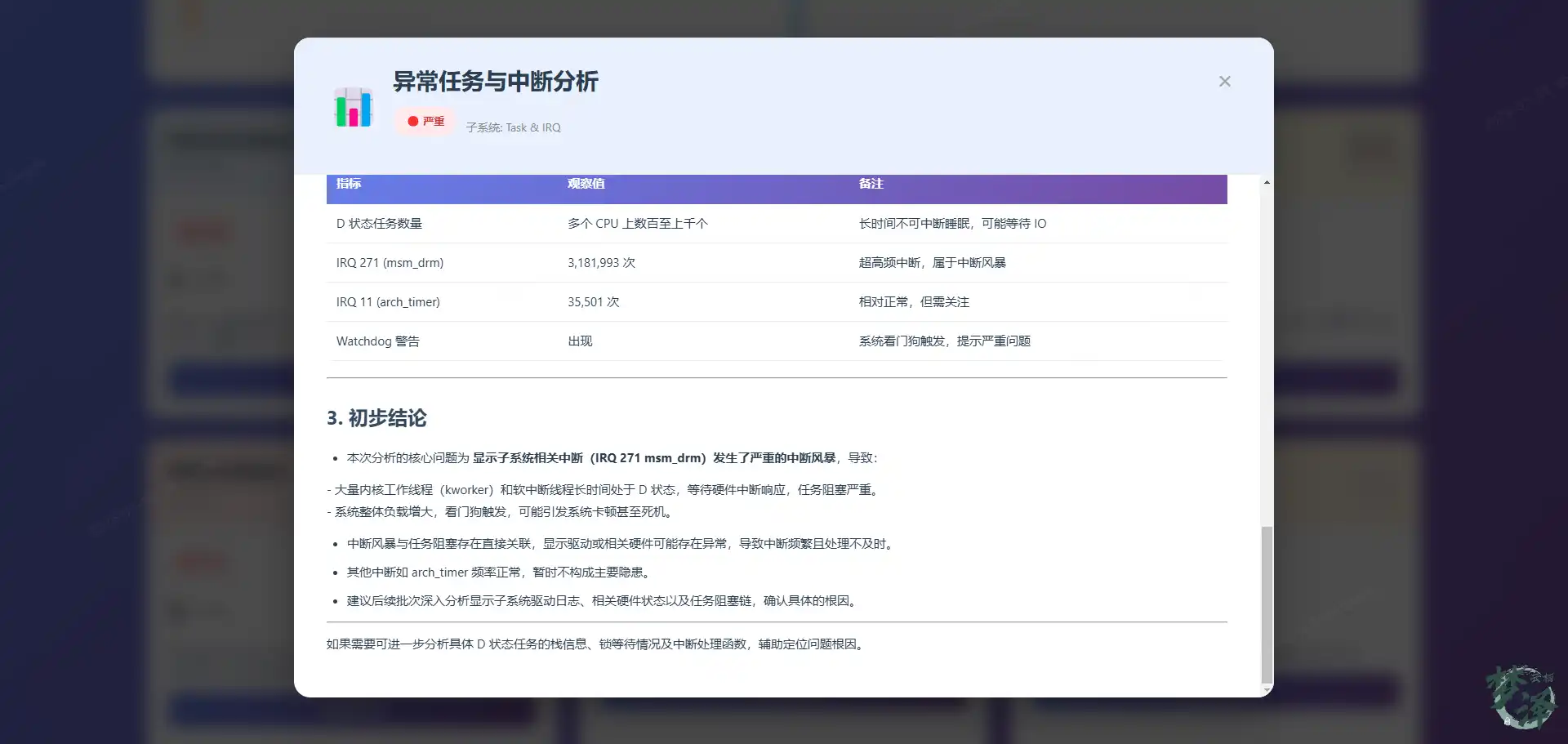
工具自动提取了 dmesg_TZ.txt 中的中断统计:
IRQ 271 [GICv3:msm_drm] - 3,181,993 times (in 60s)
→ 平均 53,033 次/秒正常情况下,这个中断应该是 60 次/秒。AI 分析报告指出:
根因假说:IRQ 271 中断风暴(频率异常高 53K/s)
→ CPU 忙于处理中断,无法执行正常任务
→ Watchdog 检测到 soft lockup
建议:检查 msm_drm 驱动的中断处理逻辑,可能存在:
1. 硬件状态未正确清除
2. 中断处理函数中有循环逻辑
3. 中断 coalescing 配置错误节省时间:从 30 分钟 → 2 分钟
案例二:符号解析找到精确代码行
问题现象:
Kernel panic,日志显示 drm_atomic_helper_commit+0x1a8 空指针解引用。
传统分析:
# 手动查符号表
nm vmlinux | grep drm_atomic_helper_commit
# 得到基地址 0xffffff80081232ae
# 计算实际地址
# 0xffffff80081232ae + 0x1a8 = 0xffffff8008123456
# 查源码位置
addr2line -e vmlinux 0xffffff8008123456
# drivers/gpu/drm/drm_atomic_helper.c:1423Stability AI 分析:
python run_cli.py -i panic.log \
--vmlinux vmlinux \
--md report.md生成的报告直接显示:
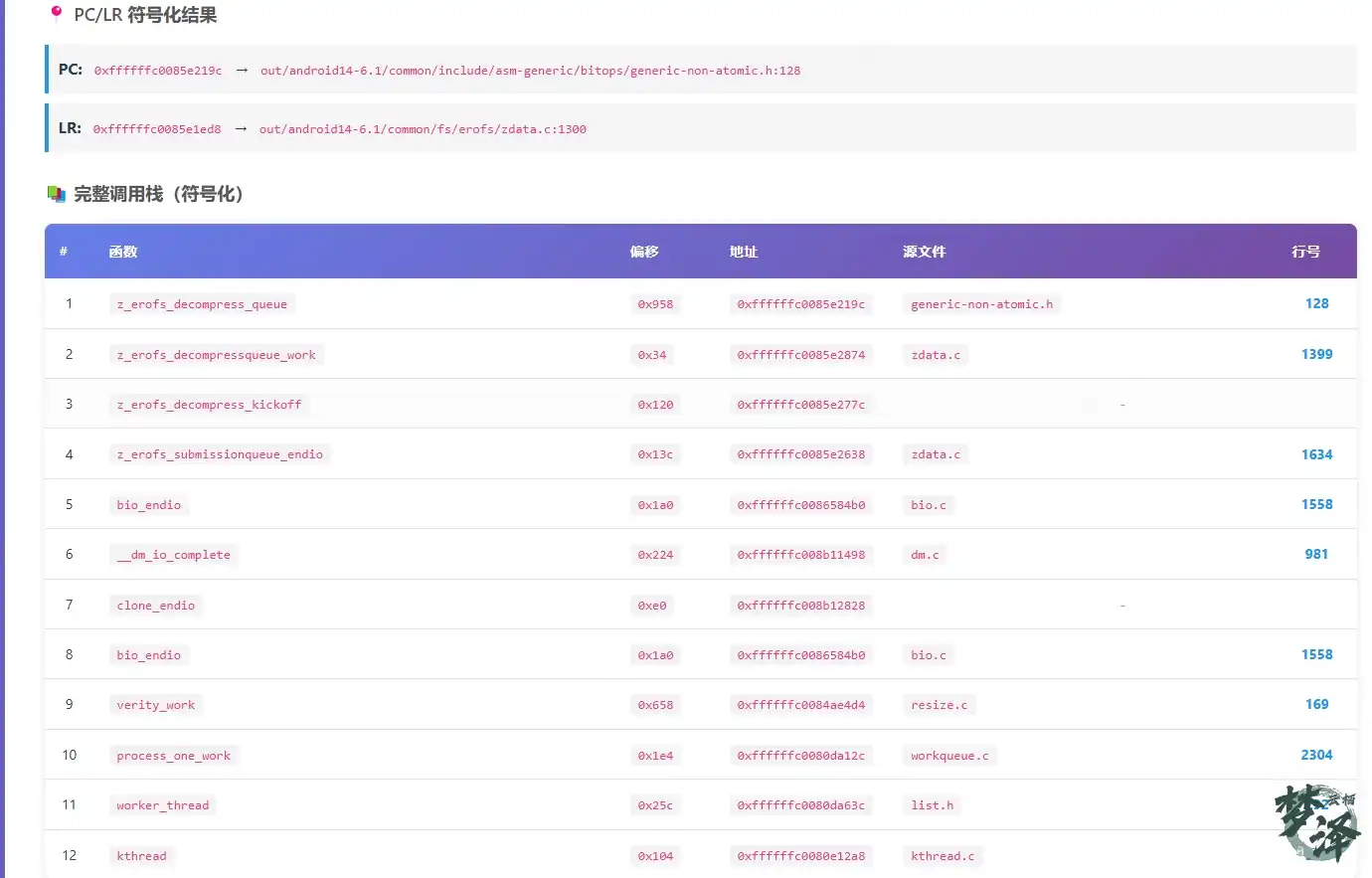
### 符号解析后的调用栈
1. drm_atomic_helper_commit+0x1a8
📁 drivers/gpu/drm/drm_atomic_helper.c:1423
2. drm_atomic_commit+0x50
📁 drivers/gpu/drm/drm_atomic.c:856开发者可以直接打开源码,查看第 1423 行的逻辑,无需任何手动操作。
经验总结
开发 Stability AI 的过程中,我学到了几个重要教训:
不要过度自动化:
早期版本试图让 AI 完全自主分析,结果准确率很低
现在的方案是:人工制定规则 + AI 辅助推断
结果:准确率从 60% → 90%+
结构化比自由文本更重要:
早期让 AI 生成自由格式的报告,难以后续处理
现在强制 JSON schema,可以聚合、可视化、自动归档
结果:报告可以直接导入 Jira、数据库
符号解析是刚需:
原本以为符号解析是"锦上添花"
实际使用中,没有符号的 calltrace 几乎无法调试
用户反馈:符号解析是最有价值的功能
批次多文件分析的价值被低估了:
最初只关注单个日志分析
加入批次分析后,发现用户最需要的是"全局视角"
现在 70% 的用户使用批次分析模式
第四部分:未来的展望
近期规划(3-6 个月)
多模态分析
支持截图、视频日志(OCR 提取关键帧)
结合用户报告的"复现步骤"进行关联分析
识别 UI 卡顿、黑屏等视觉问题
时序分析
构建事件时间线,识别因果关系
例如:"内存分配失败" → 3 秒后 → "进程 OOM"
自动推断:"OOM 是内存碎片化导致的"
知识图谱
构建 "问题-根因-解决方案" 知识图谱
当遇到类似问题时,自动推荐历史解决方案
支持团队知识积累
中期目标(6-12 个月)
团队协作功能
Web 服务模式(已有初步实现)
多人共享分析结果
评论、标注、任务分配
版本控制集成(Git blame 找责任人)
成本优化
使用更小的本地模型
混合策略:本地模型做初筛,GPT-4 做深度分析
预计成本降低 80%
长期愿景(1-2 年)
开源生态
开源核心框架
建立插件市场
不同团队贡献自己的 Detector/Analyzer
技术挑战
未来的发展会面临几个挑战:
模型准确率:
当前 AI 分析准确率约 85-90%
目标:95%+
需要:更大的标注数据集、Fine-tune 专用模型
性能瓶颈:
符号解析是 CPU 密集型操作
批次分析可能需要处理 100+ 个文件
解决方案:并行化、缓存、增量分析
隐私和安全:
日志可能包含敏感信息(用户数据、专有代码)
不能直接传给公有 API
解决方案:私有化部署、数据脱敏、本地模型
结语:工具的本质是放大人的能力
开发 Stability AI 的这段时间,我对"AI 工具"有了新的理解。
AI 不是用来替代人的。它无法替代工程师的直觉、经验和创造力。但它可以:
承担重复性的筛选工作
提供新的视角和假说
加速从"数据"到"洞察"的过程
好的工具不是最复杂的,而是最适合用户工作流的。Stability AI 不是一个"黑盒 AI",而是一个可控、可扩展、可解释的分析框架。用户可以:
只用本地规则分析(不依赖 AI)
只用符号解析(不需要联网)
自定义分析规则(通过插件)
完全离线运行(私有化部署)
技术的进步应该让工作更有趣,而不是更枯燥。以前,我需要花数小时盯着日志文件,现在我可以在 5 分钟内得到初步分析,然后把时间花在更有价值的事情上:
思考更深层的架构问题
优化系统的稳定性设计
与团队讨论解决方案
写文档帮助其他人
而这才是本工具的意义所在